
20岁拿下博士、答辩席坐着费曼的狂人:AI是第一种「外星智能」
20岁拿下博士、答辩席坐着费曼的狂人:AI是第一种「外星智能」Stephen Wolfram,一个把毕生精力都花在「让机器变聪明」上的人,坐在电脑前,屏幕上是ChatGPT刚替他写好的一段代码。语言是他自己发明的Wolfram Language,语法他看过,没问题,按下回车键就能直接在这台机器上跑。
来自主题: AI资讯
8784 点击 2026-07-26 14:22
 搜索
搜索
Stephen Wolfram,一个把毕生精力都花在「让机器变聪明」上的人,坐在电脑前,屏幕上是ChatGPT刚替他写好的一段代码。语言是他自己发明的Wolfram Language,语法他看过,没问题,按下回车键就能直接在这台机器上跑。

现在的 Agent 将所有的工程线索和垃圾噪音都一股脑扔进 Chat Context 里,缺乏一层独立、结构化的 Engineering State 来做隔离与控制。为了打破这个瓶颈,Valkor 联合浙江大学智能计算与软件研究中心、伦敦大学学院(UCL)软件工程团队正式推出并开源了 loom。
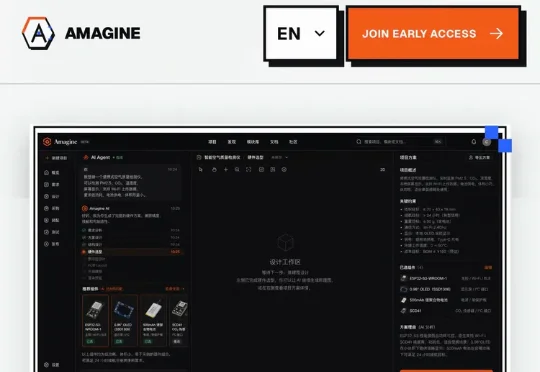
这些项目未必都是最成熟的,但它们有一个共同点:没有把模型本身当作产品,而是把 AI 放进一条具体的任务链里,让一个想法变成物品,让一个需求得到回应,或者让一套智能系统真正运转起来。

近日,有关DeepSeek创始人梁文锋此前一次长达4小时的投资人会议内容在业内流传。不过,据报道,这场本应在小范围封闭场合进行的内部交流,因会议纪要在未经授权的情况下外泄,引起了梁文锋的不满。
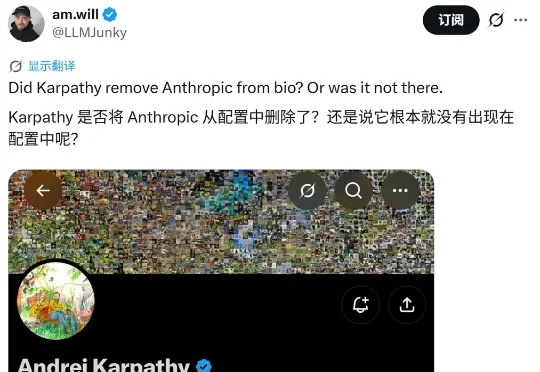
官宣入职 Anthropic 才两个多月,Andrej Karpathy 就要走了?刚刚,有网友发现 Karpathy 修改了自己的个人简介,去掉了其中的公司信息。在删除之前,他的信息简介栏有着清晰的「Anthropic」字眼。有人说,这个改动发生在昨天。

一部由AI创作的连续短剧,成了最近中文互联网上最受关注的作品之一。上线不到30天,《被裁掉的女孩》第一季,播放量破亿。作品之外,剧中的两名角色也开始拥有自己的“观众”,方桃子和周以衡分别开设了社交账号,“两个AI演员比内娱待爆艺人都火”也成为社交平台上的热门讨论。
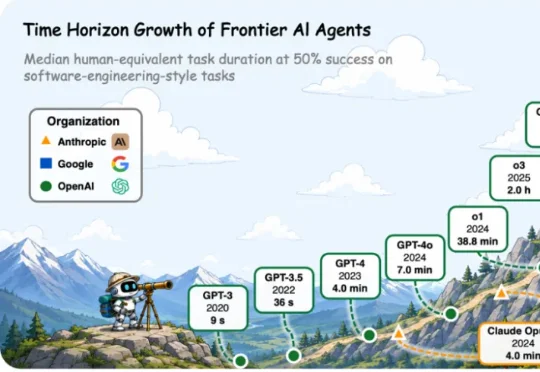
我们想强调的是:智能体 “跑得久”,并不等于 “具备长程能力”。真正的关键,不在于占用更多时间与算力,而在于能否在更长、更复杂、更真实的推理依赖链上持续、有效地行动。长期以来,Autonomous Agent、Self-Evolving Agent 等概念常与长程智能体混用。
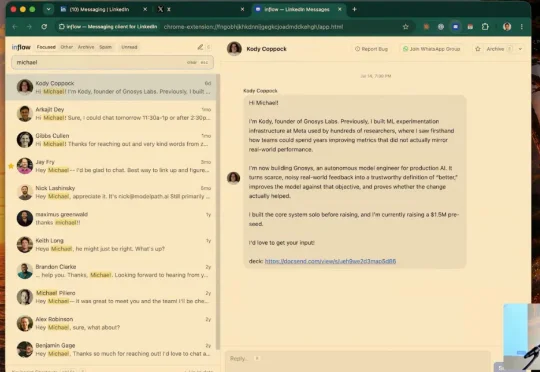
你有没有想过,写代码这件事的对象正在悄悄换人?上周一晚上,我在旧金山Market Street上WorkOS的办公室里待了将近两个小时,看了二十几个现场demo。进门之前我以为这只是一场普通的创业展示夜,但看完之后我意识到,这群人在展示的根本不是产品,而是他们对"写代码、用代码、读代码"这件事本身的理解,已经发生了多深的变化。

“包括Physical Intelligence在内,如今的北美头部具身智能公司离成熟都还有不短的距离。整个领域,也还没出现真正的奠基性工作。”“中国真正领先的,恰恰是机器人硬件。美国同样没有成熟答案,中国公司又何必急着把自己称为‘中国版XX’?”
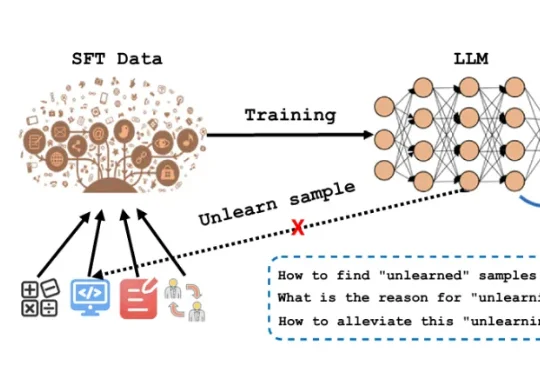
SFT是LLM从“通才”变成“专才”的关键步骤。业界默认做法是:准备标注数据(QA对、指令-回复对等)在基座模型上跑SFT训练。看loss曲线收敛了→认为训练完成。但问题在于:loss是全局平均,掩盖了样本间的差异。loss收敛只代表“大部分样本学会了”——那些始终学不会的样本被淹没了。