老显卡福音!美团开源首发INT8无损满血版DeepSeek R1
老显卡福音!美团开源首发INT8无损满血版DeepSeek R1满血版DeepSeek R1部署A100,基于INT8量化,相比BF16实现50%吞吐提升! 美团搜推机器学习团队最新开源,实现对DeepSeek R1模型基本无损的INT8精度量化。
来自主题: AI技术研报
8020 点击 2025-03-04 20:36
 搜索
搜索
满血版DeepSeek R1部署A100,基于INT8量化,相比BF16实现50%吞吐提升! 美团搜推机器学习团队最新开源,实现对DeepSeek R1模型基本无损的INT8精度量化。

全球有多少AI算力?算力增长速度有多快?在这场AI「淘金热」中,都有哪些新「铲子」?AI初创企业Epoch AI发布了最新全球硬件估算报告。

由无问芯穹与上海交通大学联合研究团队提出的视频生成软硬一体加速器,首次实现通过差分近似和自适应数据流解决 VDiT 生成速度缓慢瓶颈,推理速度相比 A100 提升高达 16.44 倍。
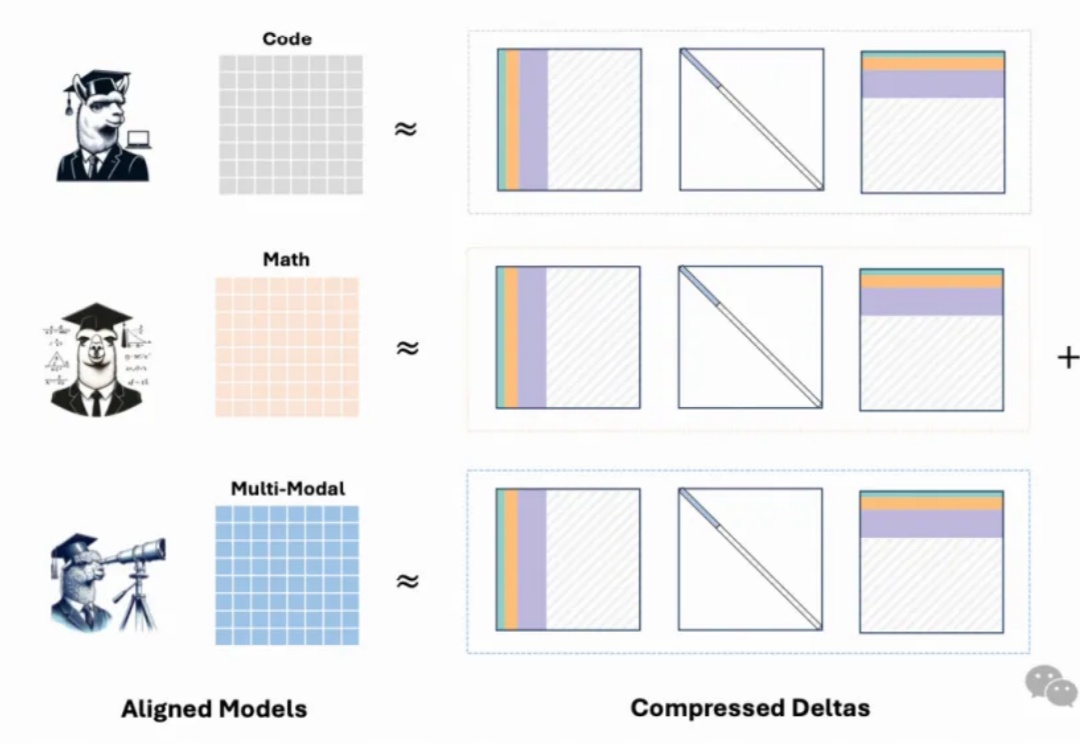
最新模型增量压缩技术,一个80G的A100 GPU能够轻松加载多达50个7B模型,节省显存约8倍,同时模型性能几乎与压缩前的微调模型相当。
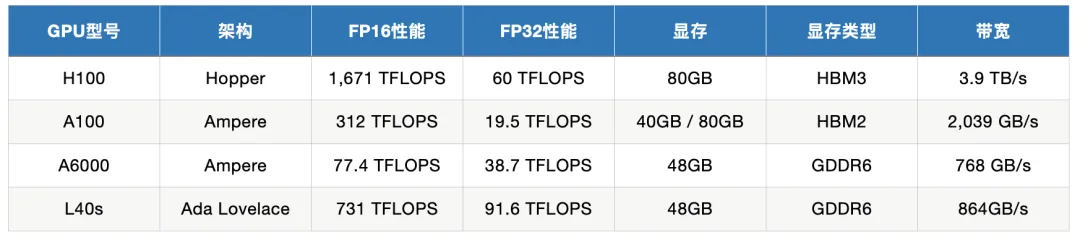
通过深入分析这些 GPU 的性能指标,我们将探讨它们在模型训练和推理任务中的适用场景,以帮助用户在选择适合的 GPU 时做出明智的决策。同时,我们还会给出一些实际有哪些知名的公司或项目在使用这几款 GPU。

人类已知最大的素数,被GPU发现了!英伟达前员工Luke Durant发现的2136279841-1,比前一个纪录保持者多出1600万位,由A100计算,H100确认。为此,小哥搭了数千个GPU的「云超算」,分布在17个国家。
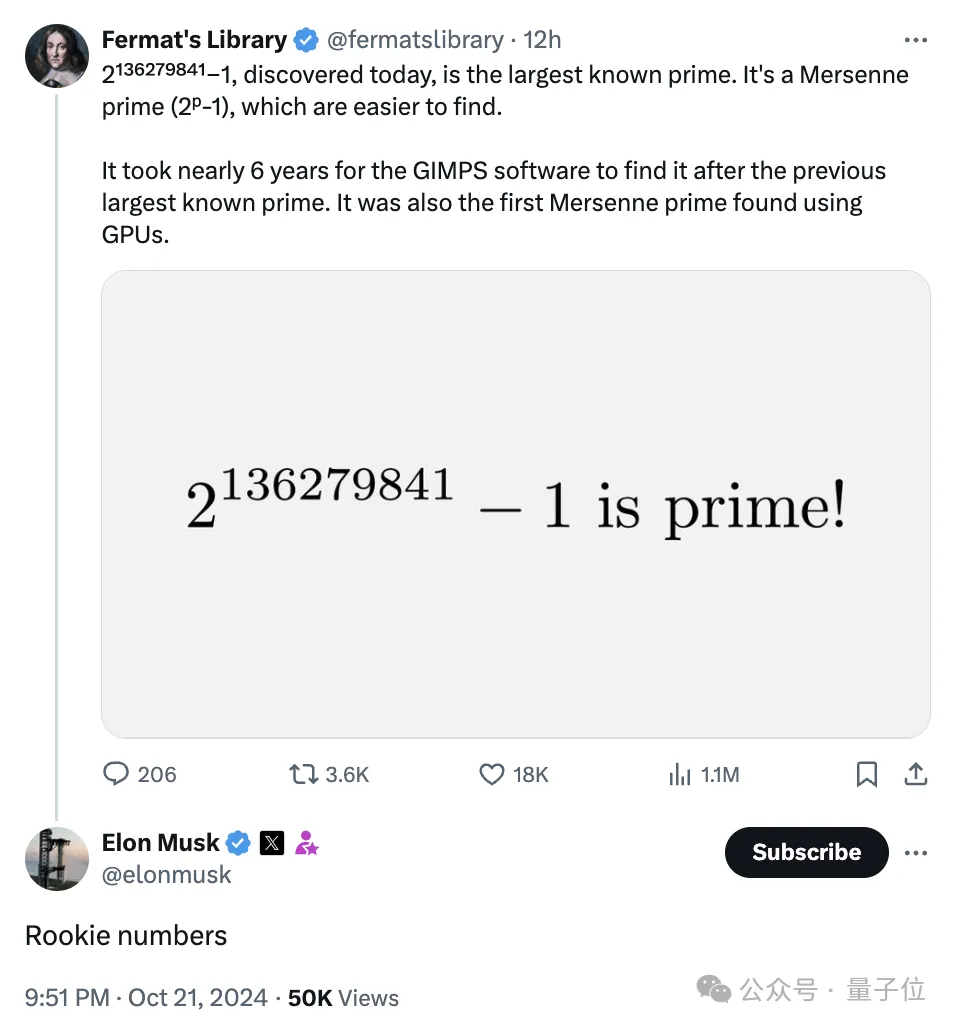
新的人类已知最大素数,被GPU发现!

自回归解码已经成为了大语言模型(LLMs)的事实标准,大语言模型每次前向计算需要访问它全部的参数,但只能得到一个token,导致其生成昂贵且缓慢。
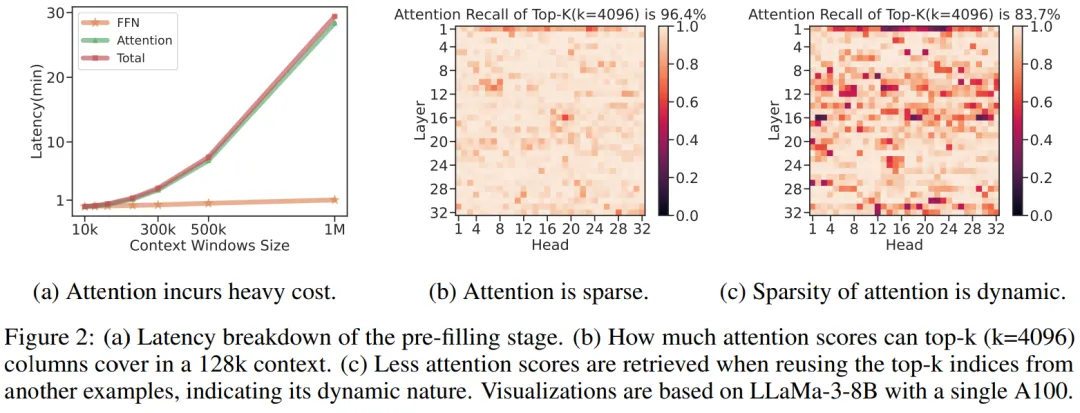
微软的这项研究让开发者可以在单卡机器上以 10 倍的速度处理超过 1M 的输入文本。
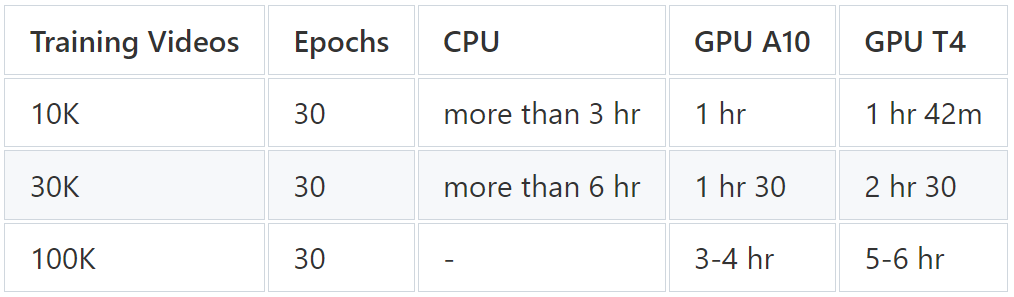
很翔实的一篇教程。