
LeCun谢赛宁首发全新视觉多模态模型,等效1000张A100干翻GPT-4V
LeCun谢赛宁首发全新视觉多模态模型,等效1000张A100干翻GPT-4V近日,LeCun和谢赛宁等大佬,共同提出了这一种全新的SOTA MLLM——Cambrian-1。开创了以视觉为中心的方法来设计多模态模型,同时全面开源了模型权重、代码、数据集,以及详细的指令微调和评估方法。
来自主题: AI资讯
5525 点击 2024-06-27 16:22
 搜索
搜索
近日,LeCun和谢赛宁等大佬,共同提出了这一种全新的SOTA MLLM——Cambrian-1。开创了以视觉为中心的方法来设计多模态模型,同时全面开源了模型权重、代码、数据集,以及详细的指令微调和评估方法。
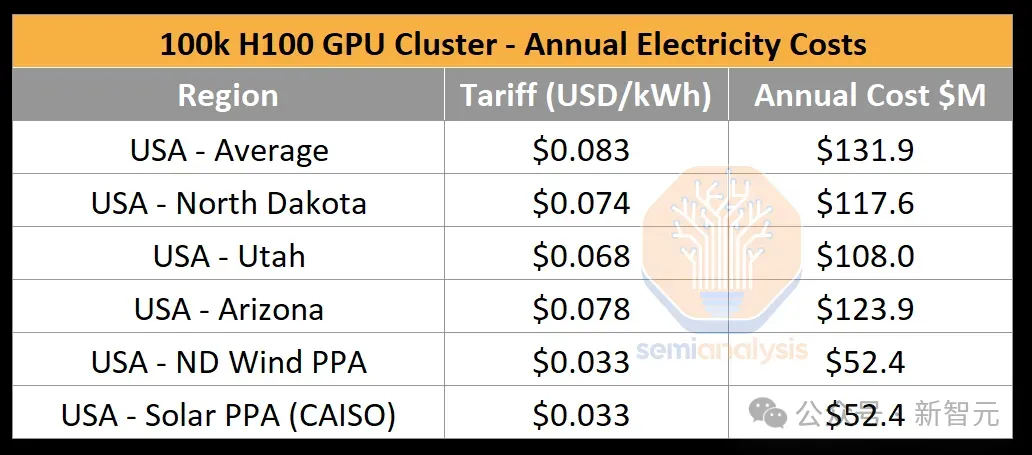
在英伟达市值猛涨、各家科技巨头囤芯片的热潮中,我们往往会忽视GPU芯片是如何转变为数据中心算力的。最近,一篇SemiAnalysis的技术文章就深入解读了10万卡H100集群的构建过程。
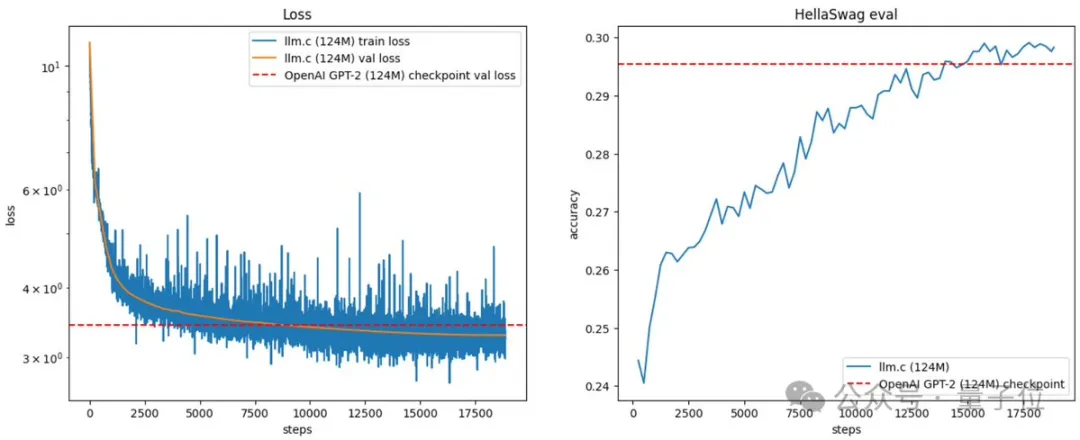
大神Karpathy已经不满足于用C语言造Llama了! 他给自己的最新挑战:复现OpenAI经典成果,从基础版GPT-2开始。
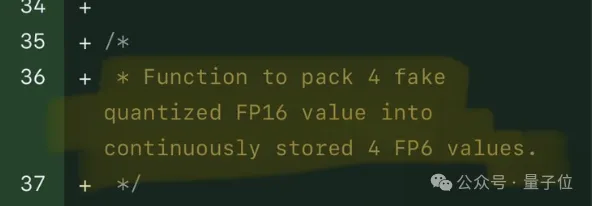
FP8和更低的浮点数量化精度,不再是H100的“专利”了!

【新智元导读】52B的生产级Mamba大模型来了!这个超强变体Jamba刚刚打破世界纪录,它能正面硬刚Transformer,256K超长上下文窗口,吞吐量提升3倍,权重免费下载。

简笔素描一键变身多风格画作,还能添加额外的描述,这在 CMU、Adobe 联合推出的一项研究中实现了。作者之一为 CMU 助理教授朱俊彦,其团队在 ICCV 2021 会议上发表过一项类似的研究:仅仅使用一个或数个手绘草图,即可以自定义一个现成的 GAN 模型,进而输出与草图匹配的图像。

许久未更新大模型的英伟达推出了150亿参数的Nemotron-4,目标是打造一个能在单个A100/H100可跑的通用大模型。
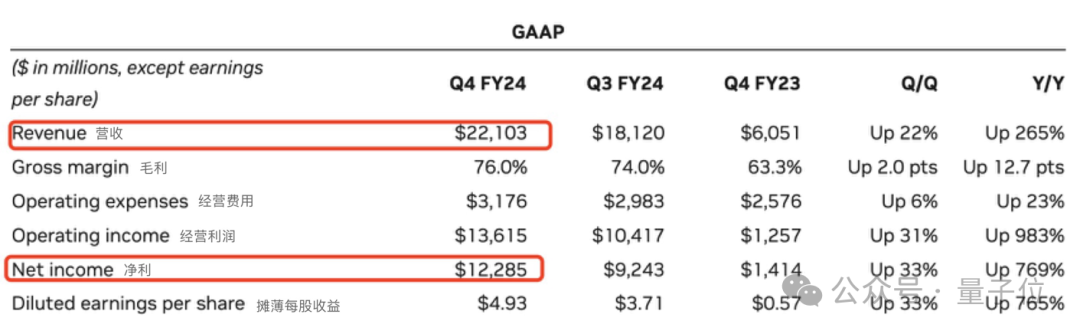
英伟达最新财报出炉。连创“三高”:

今年,会不会是AI视频生成模型的元年?UT Austin联手Meta团队提出了一个全新V2V模型FlowVid,能够在1.5分钟内生成4秒高度一致性的视频。

都快到年底了,大模型领域还在卷,今天,Microsoft发布了参数量为2.7B的Phi-2——不仅13B参数以内没有对手,甚至还能和Llama 70B掰手腕!