

套壳、断头和热舞,AI在这一年的动人瞬间
套壳、断头和热舞,AI在这一年的动人瞬间2025年,AI不再只是发布会上的炫技,也不再独属于工程师和资本。
来自主题: AI资讯
9420 点击 2026-01-07 11:33
2025年,AI不再只是发布会上的炫技,也不再独属于工程师和资本。

当英伟达被曝出以20亿-30亿美元洽谈收购AI21 Labs,这是提前锁定「下一代AI主导权」,而不是一笔普通的技术并购。更让人吃惊的是,AI21 Labs全职员工规模约200人,折算下来,人均「身价」高达1000万至1500万美元,远高于大多数独角兽并购案例。
财大气粗的老黄,又要出手了!为了将200多位顶尖AI人才纳入麾下,英伟达被曝拟用20~30亿美金收购一家以色列AI初创公司。这家公司名为AI21 Labs,是以色列为数不多的自主研发大语言模型的公司,其联创还曾创办了明星自动驾驶公司Mobileye(Mobileye被收购后成了英特尔副总裁)。

三年前点燃大模型革命的 OpenAI,正在被算力成本、开源浪潮与分发缺口拖入泥潭。与之相反,谷歌用 Gemini 与全栈生态完成反击,把 AI 塞入搜索、安卓与广告。领先者与追赶者在 2025 年末交换了位置。
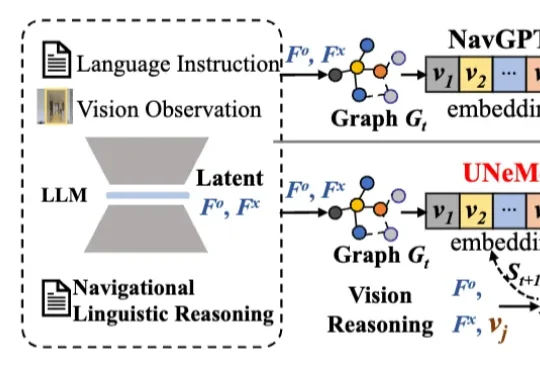
深圳大学李坚强教授团队最近联合北京理工莫斯科大学等机构,提出视觉-语言导航(VLN)新框架——UNeMo。让机器人听懂指令,精准导航再升级!

当美国巨头如Google、OpenAI 和 Anthropic 竞相开发支撑其 AI 产品的大型语言模型时,Sakana AI、Mistral AI、DeepSeek 和 AI21 Labs 等初创公司正凭借为特定地区、行业或独特功能设计的专业模型开辟自己的细分市场。

新星闪耀!28位学者获1800万美元,华人天才齐上阵。AI2050瞄准AI普惠与安全。一文速览谷歌前CEO看好的AI方向和研究项目。

今日(10 月 28 日),高通正式宣布推出两款全新芯片——高通 AI200 和高通 AI250,以及相应的机架级解决方案。此举直接挑战了由英伟达和超威半导体长期主导的 AI 芯片领域。消息宣布后,高通股价依然应声飙升,涨幅超 11%,创 2024 年 7 月以来新高。

UC Berkeley、UW、AI2 等机构联合团队最新工作提出:在恰当的训练范式下,强化学习(RL)不仅能「打磨」已有能力,更能逼出「全新算法」级的推理模式。他们构建了一个专门验证这一命题的测试框架 DELTA,并观察到从「零奖励」到接近100%突破式跃迁的「RL grokking」现象。
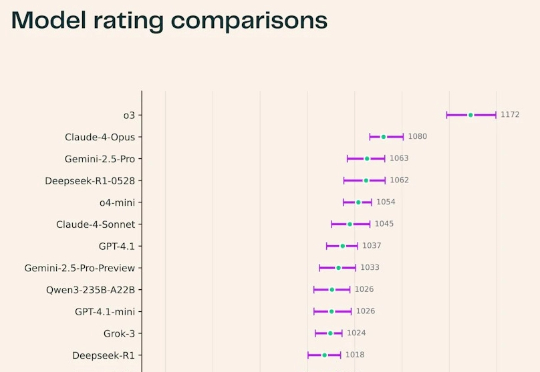
最近,Ai2耶鲁NYU联合推出了一个科研版「Chatbot Arena」——SciArena。全球23款顶尖大模型火拼真实科研任务,OpenAI o3领跑全场,DeepSeek紧追Gemini挤入前四!不过从结果来看,要猜中科研人的偏好,自动评估系统远未及格。