什么样的偏好,才叫好的偏好?——揭秘偏好对齐数据的「三驾马车」
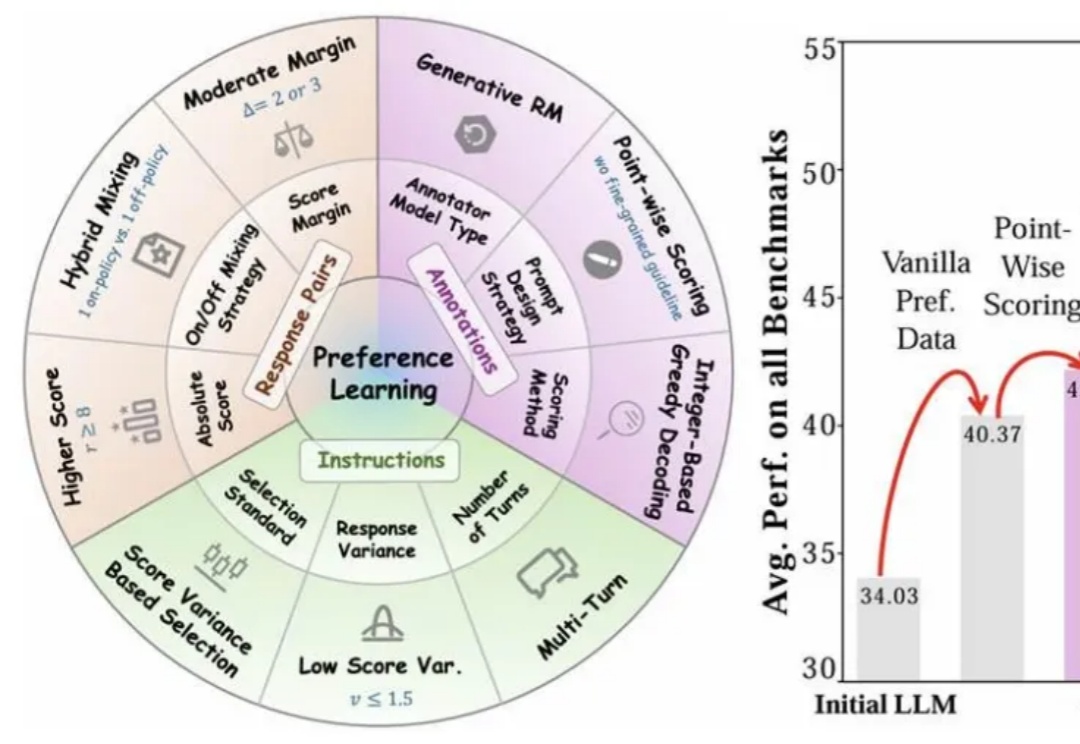
什么样的偏好,才叫好的偏好?——揭秘偏好对齐数据的「三驾马车」近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。
来自主题: AI技术研报
9417 点击 2025-04-15 14:29
 搜索
搜索
近年来,大语言模型(LLMs)的对齐研究成为人工智能领域的核心挑战之一,而偏好数据集的质量直接决定了对齐的效果。无论是通过人类反馈的强化学习(RLHF),还是基于「RL-Free」的各类直接偏好优化方法(例如 DPO),都离不开高质量偏好数据集的构建。