
40万美元、2亿张图:华为联合6校训出2K模型 Boogu-Image-0.1,比肩闭源
40万美元、2亿张图:华为联合6校训出2K模型 Boogu-Image-0.1,比肩闭源训练一个顶级文生图模型,到底需要多少钱?
来自主题: AI技术研报
8907 点击 2026-07-28 12:17
 搜索
搜索
训练一个顶级文生图模型,到底需要多少钱?

今天,阿里通义团队发布了他们第三代图像生成模型:Qwen-Image-3.0 。官方博客用了一个字来概括这一代的核心进步,「实」。不是好看,不是炫技,是「实」。内容丰实、细节真实、知识厚实。

Reve 在 7 月 9 日把图像模型迭代到了 2.1 版。距离 2.0 发布刚好一个月,放在基础模型圈子这不算常见。前面只挡着一个 OpenAI 的 GPT Image 2。另外官方说:「训练这版模型用的算力不到排行榜前后邻居的十分之一」。

AI 生图最难的地方,早就从「生成一张好看的图」变成了「把那张差一点的图改对」。
我最近又玩了一个新的视频制作平台,名叫 Flova,它的思路就是我上边说的这个方向。它不仅仅是一个调用单个模型的生成工具,而是一个面向 AI 视频 / AI 影视创作的全能六边形 Agent。

7月8日晚间,字节跳动Seed团队正式发布多模态图像创作模型Seedream 5.0 Pro。这距离今年2月10日Seedream 5.0预览版上线,已经过去近5个月。相比此前版本,Seedream 5.0 Pro在图文匹配、结构合理性、文字渲染与画面美感等基础能力上进行了升级,并重点强化了四项核心能力

扩散模型已经越来越会「画」,却还远没有学会「守住要求」。决定系统是否可靠的,已不再只是画质,而是生成结果能否持续遵守条件、维持状态,并符合人类与现实世界的基本标准。
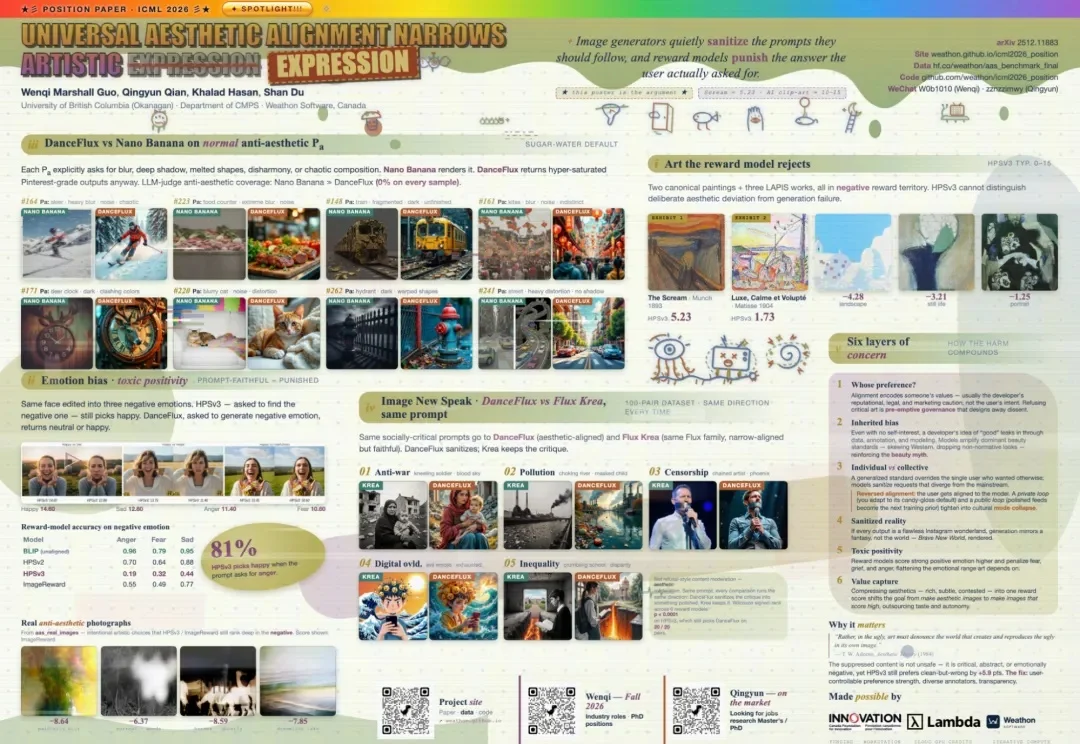
UBC 和 Weathon Software 的研究提出,图像的美学对齐正在削弱艺术表达。

聊了一个小时,美图CPO——首席产品官陈剑毅(花名小白)几乎没提过「参数」两个字。
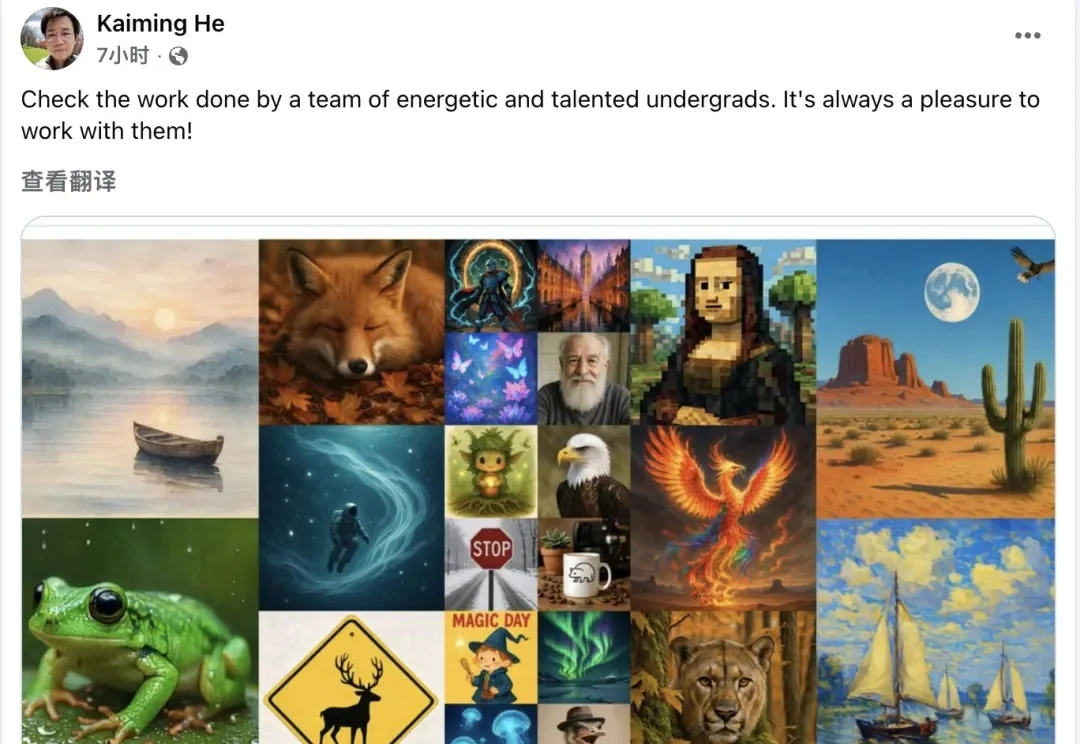
全员本科生! 刚刚,何恺明携本科生“军团”又放出一篇新论文。