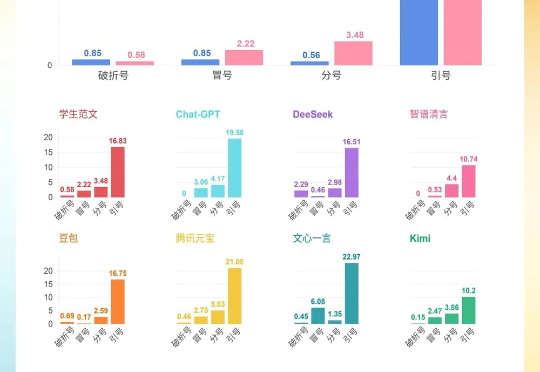
用AI砍掉70%制作预算!OpenAI首部动画长片《Critterz》能否改写动画规则?(深度观察)
用AI砍掉70%制作预算!OpenAI首部动画长片《Critterz》能否改写动画规则?(深度观察)《Critterz》讲述了一群森林生物在村庄受到一个陌生人打扰后踏上冒险之旅的故事,该片是OpenAI创意专家Chad Nelson的创意。2023年,导演兼编剧Chad Nelson与Native Foreign团队完成了《Critterz》短片,并尝试首次使用OpenAI的DALL-E完成美术与场景风格设定。
来自主题: AI资讯
11052 点击 2025-09-27 10:30