
陶哲轩回应OpenAI新模型IMO夺金!GPT-5测试版也曝光了
陶哲轩回应OpenAI新模型IMO夺金!GPT-5测试版也曝光了OpenAI最新模型曝光了,在2025年国际数学奥林匹克竞赛(IMO)上达到了金牌水平!IMO被公认为全球最顶尖的数学竞赛,每年只有不到8%的参赛者能够获得金牌。而现在,一个AI模型做到了。
来自主题: AI资讯
9988 点击 2025-07-20 23:48
 搜索
搜索
OpenAI最新模型曝光了,在2025年国际数学奥林匹克竞赛(IMO)上达到了金牌水平!IMO被公认为全球最顶尖的数学竞赛,每年只有不到8%的参赛者能够获得金牌。而现在,一个AI模型做到了。
OpenAI通用推理模型在国际奥数竞赛中达到金牌水平,解出5题得分35/42。模型通过新技术实现长时间复杂推理和自然语言证明,非专用系统。标志AI在创造性思考和科学研究的重大突破,为解决千年难题铺路。GPT-5即将发布但暂缺此能力。
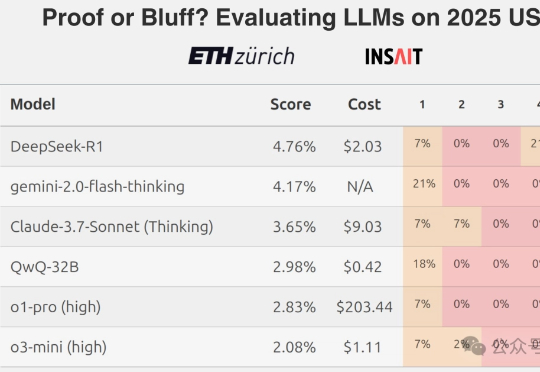
AI做奥数的神话,刚刚被戳破了!最新出炉的2025 IMO数学竞赛中,全球顶尖AI模型无一例外翻车了。即便是冠军Gemini也只拿下可怜的31分,连铜牌都摸不到。Grok-4更是摆烂到底,连DeepSeek-R1都令人失望。看来,AI想挑战人类奥数大神,还为时尚早。
AIMO2冠军「答卷」公布了!英伟达团队NemoSkills拔得头筹,开源了OpenMath-Nemotron系列AI模型,1.5B小模型击败14B-DeepSeek「推理大模型」!

AIMO2最终结果出炉了!英伟达团队NemoSkills拔得头筹,凭借14B小模型破解了34道奥数题,完胜DeepSeek R1。

国产AI几何模型性能达IMO金牌水平,打平谷歌DeepMind最新AlphaGeometry系列——
谷歌DeepMind的AI,终于拿下IMO金牌了!六个月前遗憾摘银,如今一举得金,SKEST新算法立大功。这不,它首破解了2009 IMO最难几何题,辅助作图的神来之笔解法让谷歌研究员当场震惊。
阿里巴巴全球数学竞赛,已经举办了六年。 在今年三月,组委会宣布了一件振奋人心的事情—— “不论碳基和硅基”,今年首次开辟了 AI 赛道。

OpenAI的o1系列一发布,传统数学评测基准都显得不够用了。

13.8和13.11哪个大?这个问题不光难倒了部分人类,还让一票大模型折戟。AI如今都能做AI奥数题了,但简单的常识问题对它们依然难如登天。其实,无论是比大小,还是卷心菜难题,都揭示了LLM在token预测上的一个重大缺陷。