
24小时直播,只靠一张照片?虎牙实时多模态数字人VAM 1.0率先突围行业三堵墙
24小时直播,只靠一张照片?虎牙实时多模态数字人VAM 1.0率先突围行业三堵墙打脸了,家人们!!
来自主题: AI资讯
5644 点击 2026-06-30 16:06
 搜索
搜索
打脸了,家人们!!

最近,来自上海创智学院、复旦大学等机构的研究者提出了 Hallo-Live,试图正面解决这个矛盾。论文于 2026 年 4 月 26 日 发布在 arXiv。该方法将 异步双流扩散(Asynchronous Dual-Stream Diffusion) 与 人类偏好引导蒸馏(Human-Centric Preference-Guided DMD) 结合起来
就在今天,美团龙猫大模型团队突然开源了商用级数字人视频生成模型 LongCat-Video-Avatar 1.5。在权威评测中,它的用户偏好胜率全面超越 Kling Avatar 2.0、OmniHuman-1.5 和 HeyGen 这三个头部玩家,并且直接以 MIT 协议开放,连商用限制都懒得设。

上周,我们在热爱远识资本的文章中提到了其代表作:仅靠demo就能实现13.2亿美金估值的Vivix。
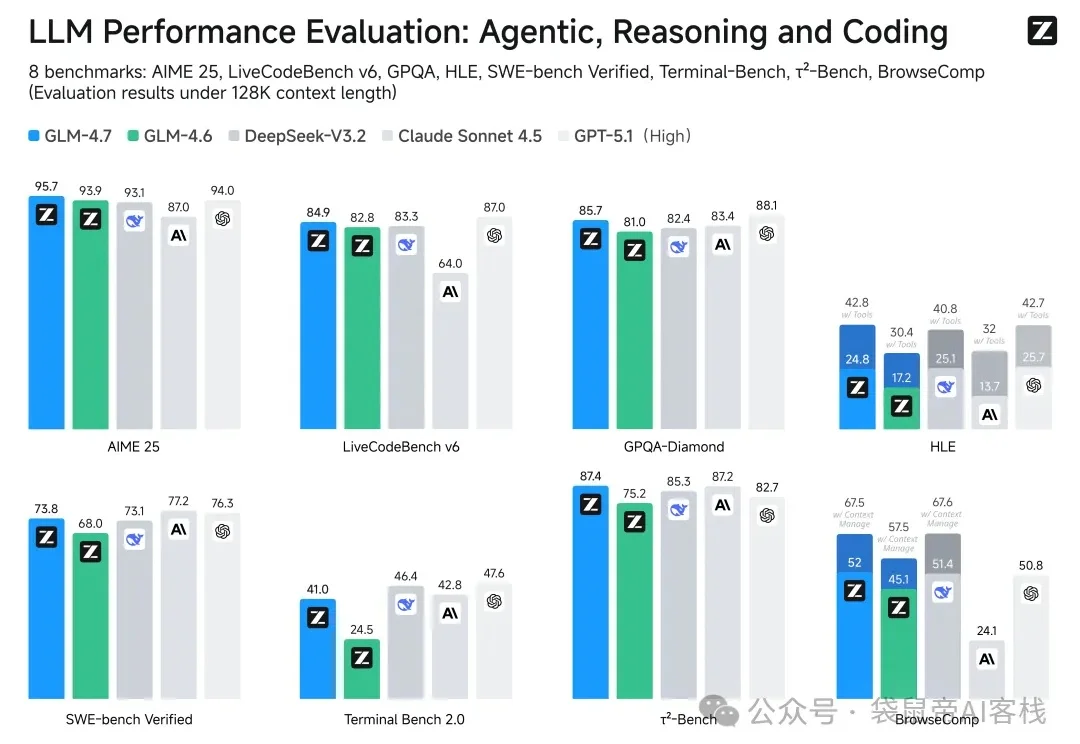
大家好,我是被智谱卷到的袋鼠帝。 昨天智谱刚把GLM-4.7放出来,群里就有老哥找我写文章了..
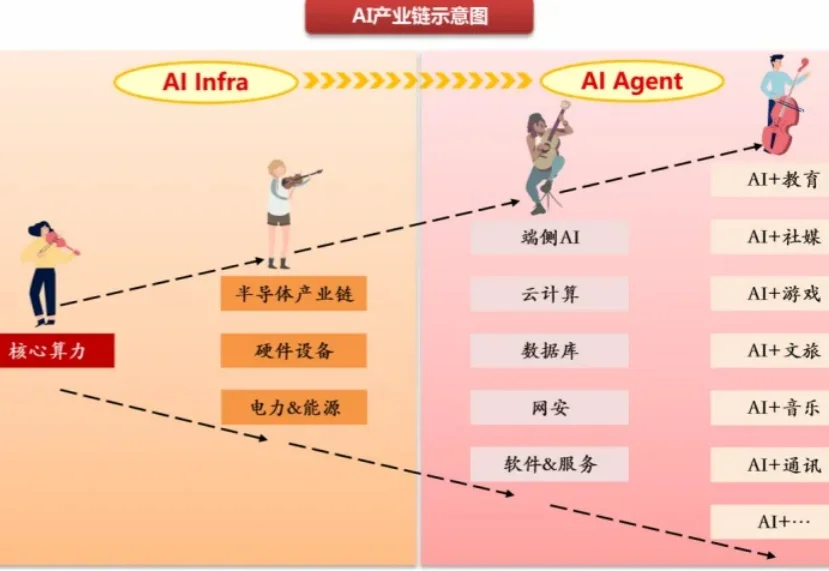
AI产业的发展遵循着典型的“基础设施→核心技术→行业应用”的科技产业化路径。当下,AI产业正在经历从“技术突破”转向“应用落地”的关键阶段。

2025 年 12 月,由 阿里巴巴 联合 中国科学技术大学、浙江大学等机构共同研发的实时虚拟人项目 LiveAvatar 正式对外开源。该项目聚焦长期困扰虚拟人行业的两大技术瓶颈——“实时响应能力”与“长时稳定生成能力”,首次在同一系统中实现了二者的工程级统一。

别惊讶,下次给你卖课的健身教练,可能带了个「数字替身」

还记得今年6月罗永浩那场堪比春晚带货专场的直播吗?评论区刷屏、订单秒飘,GMV直接干到了5500万+:

从 AI 女友到数字面试官,人格化 AI 正在「登陆」你的所有屏幕。