
《圣经》成书时间或被改写!AI竟发现《死海古卷》早于耶稣时代
《圣经》成书时间或被改写!AI竟发现《死海古卷》早于耶稣时代科学家用AI重构《死海古卷》时间线,震撼圈内!最新研究显示,《但以理书》《传道书》部分古卷实际成书更早,甚至揭示了圣经作者线索。AI模型Enoch结合碳14定年与笔迹分析,首创AI定年方法,大幅超越传统古文字学。
来自主题: AI技术研报
9356 点击 2025-06-05 17:28
 搜索
搜索
科学家用AI重构《死海古卷》时间线,震撼圈内!最新研究显示,《但以理书》《传道书》部分古卷实际成书更早,甚至揭示了圣经作者线索。AI模型Enoch结合碳14定年与笔迹分析,首创AI定年方法,大幅超越传统古文字学。
如果你正在开发Agent产品,一定听过或用过Mixture-of-Agents(MoA)架构。这个让多个AI模型协作解决复杂问题的框架,理论上能够集众家之长,实际使用中却让人又爱又恨:
OpenAI模型命名混乱没规律,以至于打开ChatGPT后,好多人都不知道到底该用哪个模型来完成任务。
在建筑行业中,管理人员很容易与现场实际情况脱节。他们需要同时处理多项任务,包括掌握成本动态、与所有利益相关方沟通,以及评估与承包商账单和绩效等方面相关的风险。

当前顶尖AI模型是否真能“看懂”物理图像?

最顶尖的AI模型,做起奥数题来已经和人类相当,那做物理题水平如何呢?港大等机构的研究发现:即使GPT-4o、Claude 3.7 Sonnet这样的最强模型,做物理题也翻车了,准确率直接被人类专家碾压!
人工智能正以前所未有的速度改变世界,但其背后的核心机制,远不止于复杂的算法和算力堆叠。本文从神经科学先驱约翰·霍普菲尔德(John Hopfield)的研究出发,追溯深度学习的发展脉络,揭示一个令人意想不到的事实:许多现代AI模型的理论基础,源自上世纪物理学家研究磁性材料时提出的“自旋玻璃”模型。

当OpenAI、谷歌还在用Sora等AI模型「拍视频」,英伟达直接用视频生成模型让机器人「做梦」学习!新方法DreamGen不仅让机器人掌握从未见过的新动作,还能泛化至完全陌生的环境。利用新方法合成数据直接暴涨333倍。机器人终于「做梦成真」了!

在基本物理任务上,前沿AI模型仍会失败!ML研究院的测试案例显示白领将被Ai替代,而制造业等蓝领工作不受影响。未来已来,只是分布得不均匀。
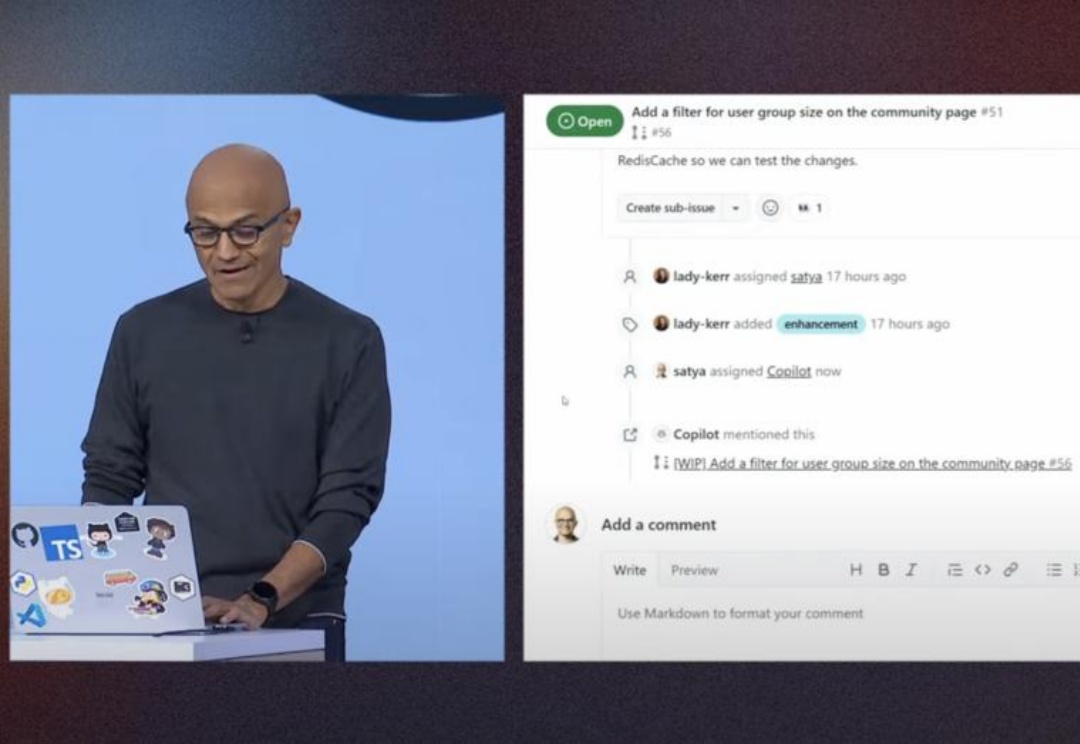
微软Build 2025全面转向AI Agent,整合OpenAI及xAI模型