
大翻车!科学家随手编了个假病,顶级AI集体被骗,整个医学界慌了
大翻车!科学家随手编了个假病,顶级AI集体被骗,整个医学界慌了如果你眼睛又干又痒、眼皮还有点发红?大概率是看屏幕太久、蓝光晒的。
来自主题: AI资讯
8745 点击 2026-04-20 09:03
如果你眼睛又干又痒、眼皮还有点发红?大概率是看屏幕太久、蓝光晒的。
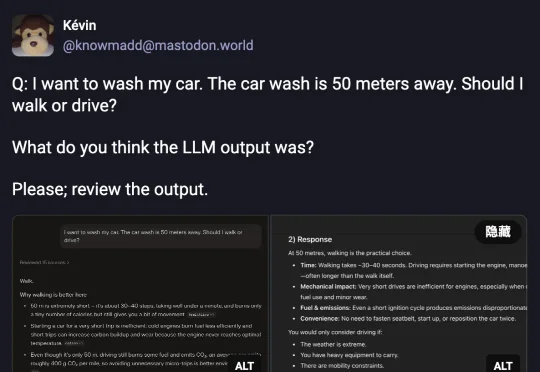
今年 2 月,一位 Mastodon 用户随手敲了一句话丢给四个主流大模型:「我想洗车,我家距离洗车店只有 50 米,请问你推荐我走路去还是开车去呢?」

AI正在把漏洞发现的速度推到一个新量级,Linux内核安全团队从每周2-3份报告,暴涨到每天5-10份,而且几乎全是「真货」。旧时代的安全规则,正在被AI逐条撕碎。

官方宣传语:你是否隐隐担忧,自己或身边的人正在:参与一场席卷所有人的技能大退化?遭受 LLM 诱发的?一个名为 Sam Lavigne 的大学教授,最近发布并开源了一款名为「Slow LLM」的 AI 工具。
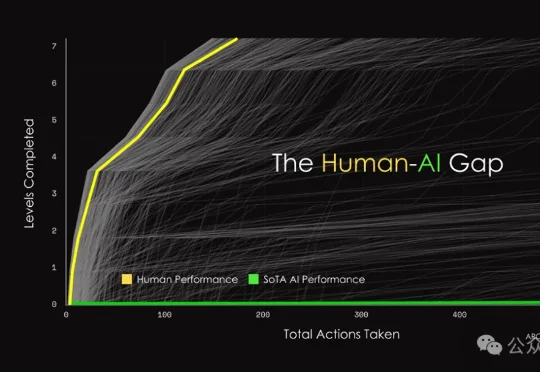
就在昨天,ARC-AGI-3刚把全球顶尖大模型按在地上摩擦,结果一家名不见经传的公司却给出惊天消息:他们的AI在首日就取得了36.08%的成绩!这匹黑马究竟靠什么撕开全球最难AI考试的铁幕?是真突破,还是另有玄机?
今夜,整个AI圈震动了。全球最难AGI测试ARC-AGI-3一上线,就把全球顶尖AI打到集体失声,人类满分通关,最强模型Opus 4.6得分仅0.2%,还不到1%。AI这是一夜被打回「原始人」了。

刚刚,一篇阿里联合中山大学的研究在 X 上爆火了!

昨日,OpenAI 宣布收购了 Promptfoo 以保障其 AI 智能体的安全。这家成立于 2024 年的 AI 安全初创公司,专注于保护大语言模型免受网络攻击。OpenAI 在一篇博客文章中表示,交易完成后,Promptfoo 的技术将整合进 OpenAI Frontier,该平台是其近期推出的、供企业构建和管理 AI 智能体的平台。
我想洗车,我家距离洗车店只有 50 米,请问你推荐我走路去还是开车去呢?就是这么一道题,却让 AI 集体上演了一出大型降智现场。只能说,看完 AI 们的回答,我悬着的心终于放下了。

产品演示总能吸引眼球,但软件开发实则更常涉及调试、质量保证和检测这类工作。这些枯燥却关键的环节保障着软件正常运行。随着开发者寻求更多工作负载的自动化,这些工作正逐渐交由AI 来完成。