
203.8亿!AI视频最大单笔融资,即将诞生
203.8亿!AI视频最大单笔融资,即将诞生《南华早报》援引知情人士消息称,快手旗下视频生成业务“可灵AI”将完成一轮30亿美元(约合人民币203.8亿元)融资,投后估值将达到180亿美元(约合人民币1223亿元),较今年4月最初设定的200亿美元目标估值缩水20亿美元。腾讯参与了可灵AI本轮融资。
来自主题: AI资讯
9605 点击 2026-07-02 01:41
 搜索
搜索
《南华早报》援引知情人士消息称,快手旗下视频生成业务“可灵AI”将完成一轮30亿美元(约合人民币203.8亿元)融资,投后估值将达到180亿美元(约合人民币1223亿元),较今年4月最初设定的200亿美元目标估值缩水20亿美元。腾讯参与了可灵AI本轮融资。

AI 视频初创公司 Higgsfield AI 正在与投资者洽谈,筹资 3 亿美元至 5 亿美元,投资前估值为 50 亿美元,据两位知情于此次筹资活动的人士透露。Higgsfield 制作了一个用于 AI 图像和视频生成的平台,允许用户从文本创建视觉内容,并编辑视频的运动控制、音频和其他组件。
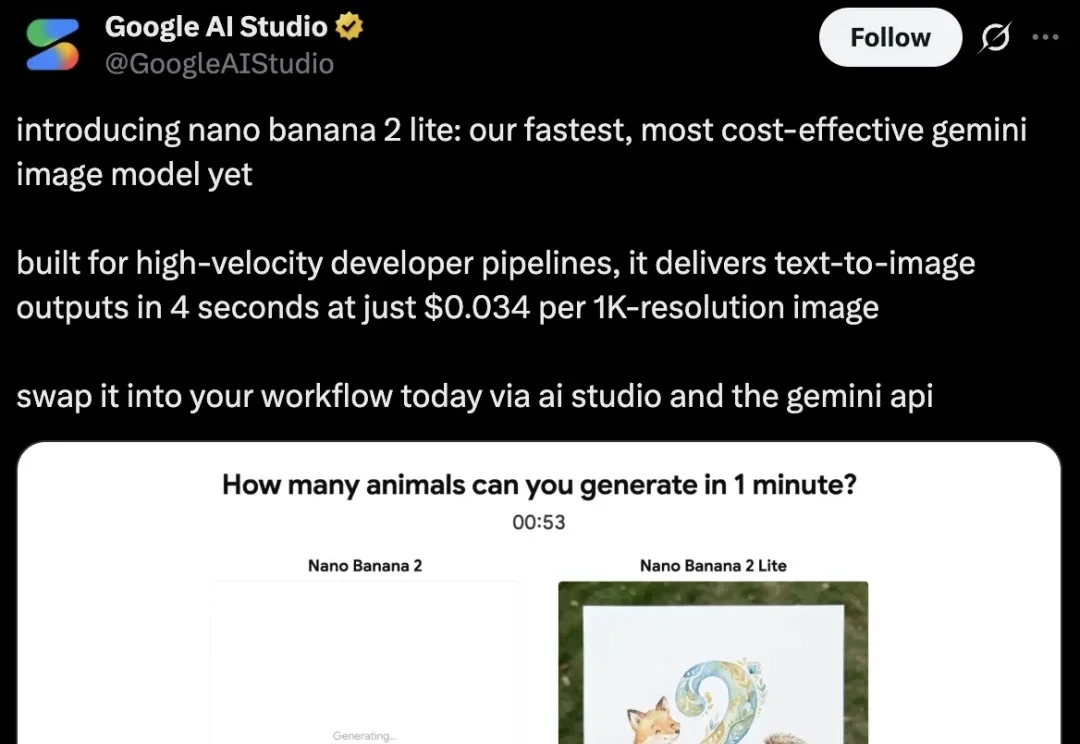
虽然Coding还是一坨,但谷歌搞「多模态」确实有两把刷子。
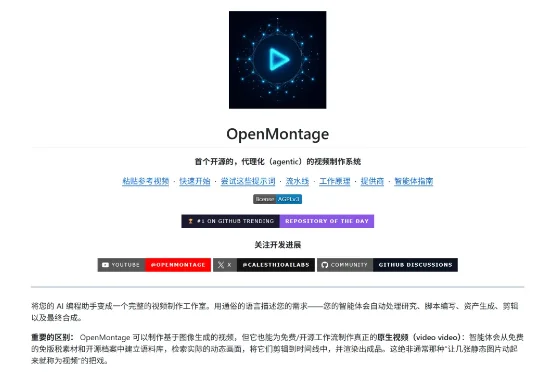
没错,我说的就是从6月下半旬开始在Github上爆火的OpenMontage。这是一个专门用来给AI视频生成准备的Harness工具,你把你的提示词给它,它就能自动帮你完善成专业的AI视频生成提示词,并且还配有剪辑、配音等等一系列后期工作。

最近,这个AI穿越Vlog刷爆全网!第一视角空降古罗马、泰坦尼克号,逼真到窒息。历史次元壁被打破的那一瞬间,很多「亲历现场」的观众,开始落泪了。

大家好,我是最近疯狂研究短剧的袋鼠帝 最近的AI漫剧发展的是真快啊,各种爽文小说改编的AI漫剧播放量甚至已经超过了某些电影和电视剧。

同样是36小时AI动画黑客松,从24支团队手忙脚乱搓出优质率约40%的AI短片,到110支AI创作者团队火力全开、用60%以上的精彩作品冲击观众的视网膜,才过去多久呢?

180 万亿。这是截至今年 6 月,豆包大模型的日均 token 调用量。

今天,阿里巴巴发布了其最新一代视频生成模型HappyHorse 1.1(快乐小马1.1)。阿里称,相比HappyHorse 1.1,这代模型在动态表现力、主体一致性、指令遵循、视觉质感和音频能力等维度有了一定提升。

“每一代模型,我们都在押注一个非共识。”