
刚刚,DeepSeek首曝V3降成本秘诀!软硬协同突破Scaling天花板
刚刚,DeepSeek首曝V3降成本秘诀!软硬协同突破Scaling天花板DeepSeek最新论文深入剖析了V3/R1的开发历程,揭示了硬件与大语言模型架构协同设计的核心奥秘。论文展示了如何突破内存、计算和通信瓶颈,实现低成本、高效率的大规模AI训练与推理。不仅总结了实践经验,还为未来AI硬件与模型协同设计提出了建议。
来自主题: AI技术研报
10172 点击 2025-05-15 17:12
 搜索
搜索
DeepSeek最新论文深入剖析了V3/R1的开发历程,揭示了硬件与大语言模型架构协同设计的核心奥秘。论文展示了如何突破内存、计算和通信瓶颈,实现低成本、高效率的大规模AI训练与推理。不仅总结了实践经验,还为未来AI硬件与模型协同设计提出了建议。
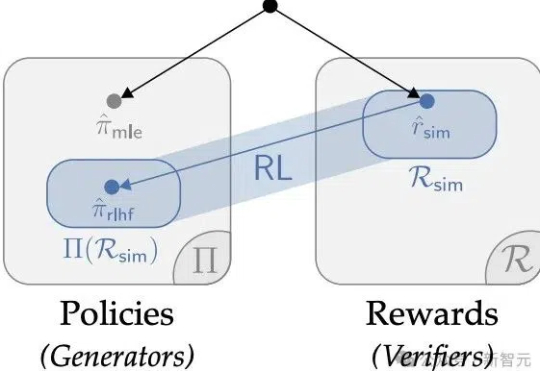
华人学者参与的一项研究,重新确立了强化学习在LLM微调的价值,深度解释了AI训练「两阶段强化学习」的原因。某种意义上,他们的论文说明RL微调就是统计。

据EETimes报道,美国AI芯片独角兽SambaNova Systems近期宣布将裁员77人,约占其500名员工的15%。此次裁员正值该公司偏离最初目标,放弃做AI训练,转向完全专注于AI推理。
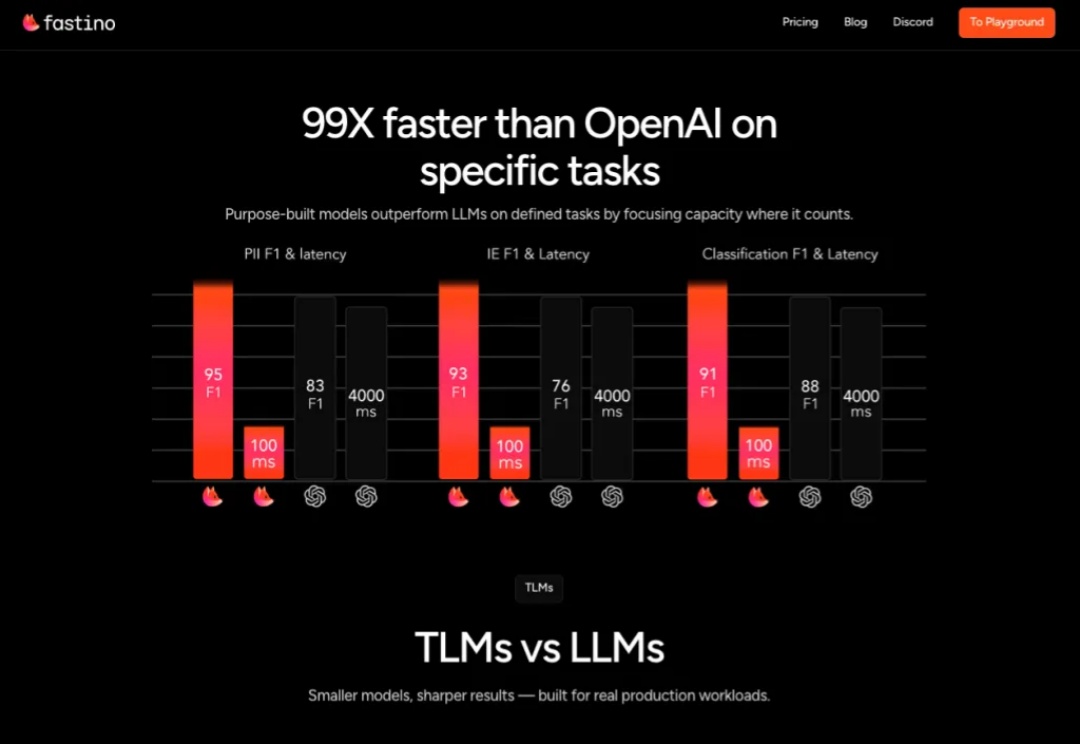
科技巨头常吹嘘需要庞大昂贵GPU 集群的万亿参数 AI 模型,但 Fastino 正采取截然不同的策略

2025年3月18日,英伟达年度技术大会(GTC)在美国圣何塞开幕,CEO黄仁勋以"AI推理时代"为核心,发布了重磅技术与合作计划,涵盖硬件架构、软件生态、量子计算、机器人技术及行业应用。与往年不同,2025 GTC英伟达转变重心,从去年的"AI训练"转向"推理与部署"的行业转型。

OpenAI训练创意写作模型,网友质疑AI情感联系。

本周二,美国特拉华州地方法院对“汤森路透”诉法律AI公司Ross Intelligence版权侵权诉讼作出部分简易判决”,汤森路透赢得美国首例AI训练版权诉讼,本案主要情况如下:
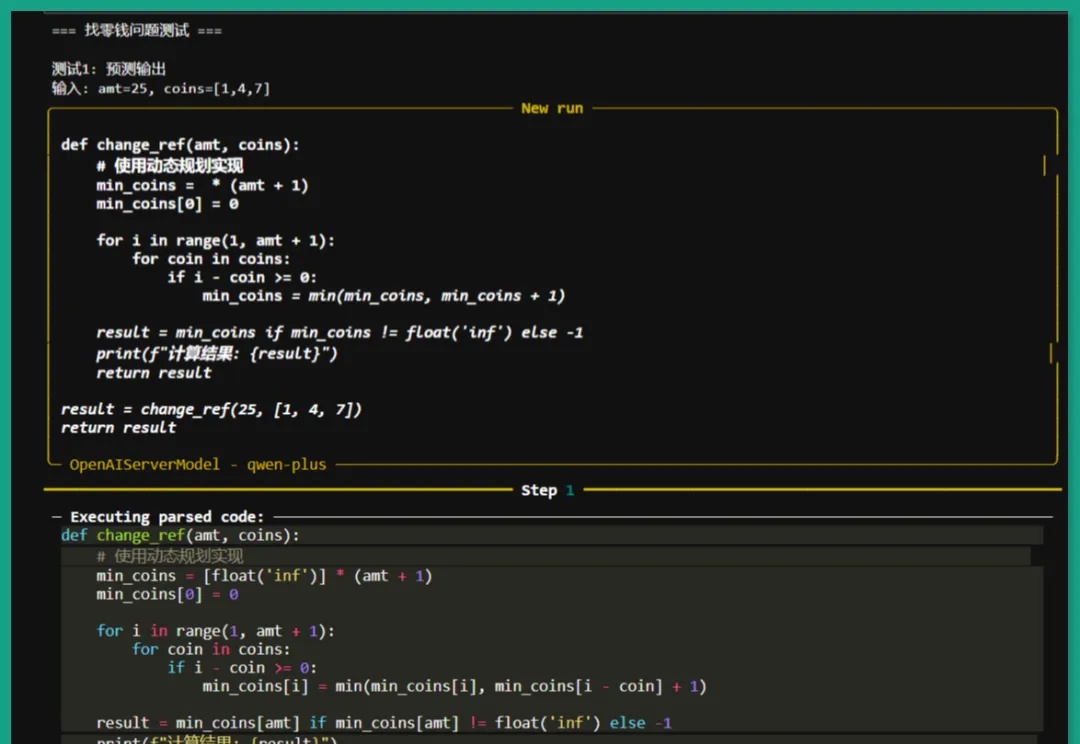
我们正见证一场静默的推理革命。传统AI训练如同盲人摸象,依赖碎片化文本拼凑认知图景,DeepSeek-AI团队的CODEI/O范式首次让机器真正"理解"了推理的本质——它将代码执行中蕴含的逻辑流,转化为可解释、可验证的思维链条,犹如为AI装上了解剖推理过程的显微镜。
这几天,一些人卖DeepSeek课的事冲上了热搜。什么9.9元的DeepSeek入门课,到几百块钱的deepseek变现特训营,再到线下动辄上万的本地AI训练师。甚至有卖家打出“三天精通AI,月入10万”的口号。闲鱼都快被卖课的屠榜了。
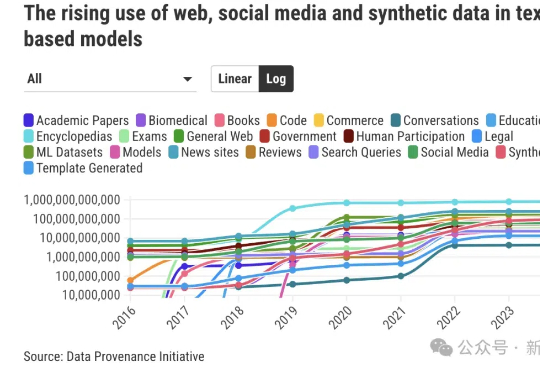
相比LLM和Agent领域日新月异、高度成熟的进展相比,数据收集方面的规范有明显滞后。由超过50名研究人员组成的「数据溯源计划」(DPI)旨在回答这样一个问题:AI训练所需的数据究竟来自何处?