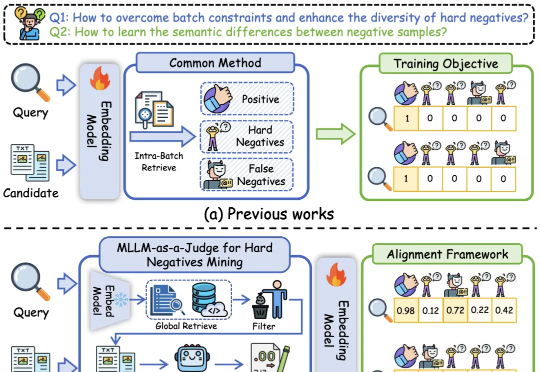
又一推理新范式:将LLM自身视作「改进操作符」,突破长思维链极限
又一推理新范式:将LLM自身视作「改进操作符」,突破长思维链极限Meta 超级智能实验室、伦敦大学学院、Mila、Anthropic 等机构的研究者进行了探索。从抽象层面来看,他们将 LLM 视为其「思维」的改进操作符,实现一系列可能的策略。研究者探究了一种推理方法家族 —— 并行 - 蒸馏 - 精炼(Parallel-Distill-Refine, PDR),
来自主题: AI技术研报
9911 点击 2025-10-10 10:33