
刚刚,LeCun团队让世界模型学会持续学习!
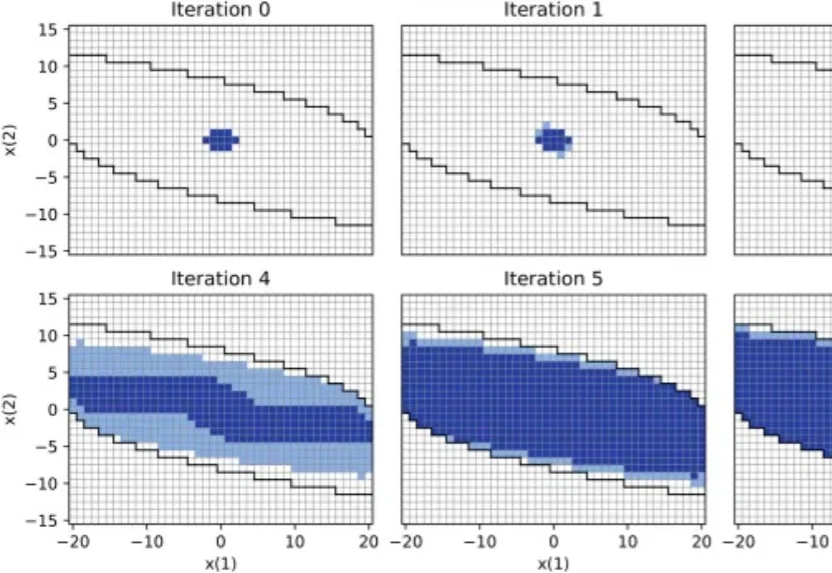
刚刚,LeCun团队让世界模型学会持续学习!刚刚,纽约大学联合LeCun初创AMI带来JEPA系列的最新成果——AdaJEPA。与过去在预训练结束后就冻结参数的世界模型不同,AdaJEPA能够在与环境交互中,基于测试时自适应(Test-Time Adaptation, TTA),实时调整世界模型的编码器和预测器参数,从而实现持续学习。
来自主题: AI技术研报
9066 点击 2026-07-03 16:12
 搜索
搜索
刚刚,纽约大学联合LeCun初创AMI带来JEPA系列的最新成果——AdaJEPA。与过去在预训练结束后就冻结参数的世界模型不同,AdaJEPA能够在与环境交互中,基于测试时自适应(Test-Time Adaptation, TTA),实时调整世界模型的编码器和预测器参数,从而实现持续学习。

阿里云正式宣布,Apache Flink 3.0全面进入Agentic Streaming For AI时代,并推出全模态数据流处理能力。这是业界第一次,把视频、音频、图像、文本这四类数据,统一放进同一条流式pipeline里调度,让AI能够实时感知、实时理解、实时回应。
近日清华大学于IEEE TPAMI发表论文,探讨了真机强化学习的安全性保障问题,提出了一套「安全探索均衡」新型机制,揭示了安全探索的理论最大边界,并攻克了其收敛性证明难题。
刚刚,开发者Jamieson O'Reilly用泄露的系统级Prompt,硬核解锁了「轻量版」的Fable 5。仅仅一行代码的注入,就让Opus 4.8当场「开智」。在极限对照实验中,O'Reilly给到同一个指令——制作一个现代苹果风的网页。

奥特曼官宣ChatGPT记忆重大升级!全新Dreaming V3架构正式上线:ChatGPT会在后台「做梦」,首次向数亿免费用户开放。这一次升级,「做梦」功能向十亿人免费开放,Plus和Pro记忆容量直接翻倍。
今天起,ChatGPT 的记忆系统更像人了。OpenAI 刚刚推出了一套全新的记忆系统,底层基于 Dreaming 技术。它会在长期对话中自动整理你的偏好、项目、设备、旅行计划和生活安排,并在回答时判断哪些信息仍然有用,哪些已经过时。

DDIM之父宋佳铭(Jiaming Song),在领英上发布了自己从Luma AI离职的消息。
「精确而丰富地唤起感官」,「旋律般的声音」,这是顶级文学杂志 Granta 今年评选的年度作品获得到的称赞——直到它翻车之前。这篇叫《The Serpent in the Grove》的小说,是 2026 年英联邦短篇小说奖加勒比地区的获奖作品,从 7806 篇投稿中被选出。作者 Jamir Nazir,这是一个带有奇幻色彩的创作,写了一个关于朗姆酒、农夫与魔法树丛的故事。
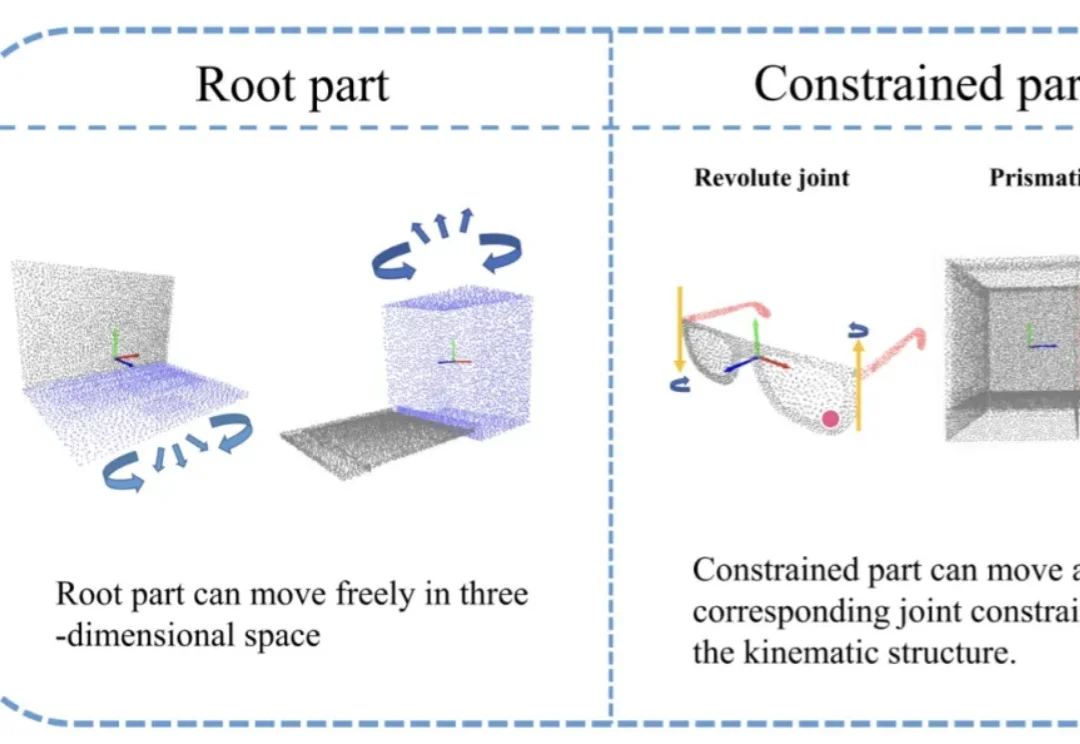
在具身智能快速发展的今天,机器人已经不再满足于「看见」刚体物体,而是开始真正走向复杂环境中的交互与操作。从机械臂开柜门,到服务机器人整理抽屉,再到工业场景中的工具操作,大量真实世界目标都属于关节物体(Articulated Objects)。

即将结束博士生涯的童晟邦,正站在另一个起点上。