
赵纯想:写在Laper.ai内测的这一天(内含内测邀请码)
赵纯想:写在Laper.ai内测的这一天(内含内测邀请码)Laper.ai 始于和王慧文先生的一次微信聊天。聊完后,实在气不过的我,把他给删了。在2025年7月底的一天,本来忙活得好好的,突然,我的手指,不受控地飞速打开游览器。搜索起“AI Screenwriter”来。
来自主题: AI资讯
10928 点击 2025-12-21 13:43
 搜索
搜索
Laper.ai 始于和王慧文先生的一次微信聊天。聊完后,实在气不过的我,把他给删了。在2025年7月底的一天,本来忙活得好好的,突然,我的手指,不受控地飞速打开游览器。搜索起“AI Screenwriter”来。

机器之心报道 编辑:+0、陈陈 最近,学术圈的大瓜莫过于 ICLR 评审大开盒事件了,只要在浏览器上输入某个网址,自行替换你要看的 paper ID 和审稿人编号,你就可以找到对应的审稿人身份。你甚至
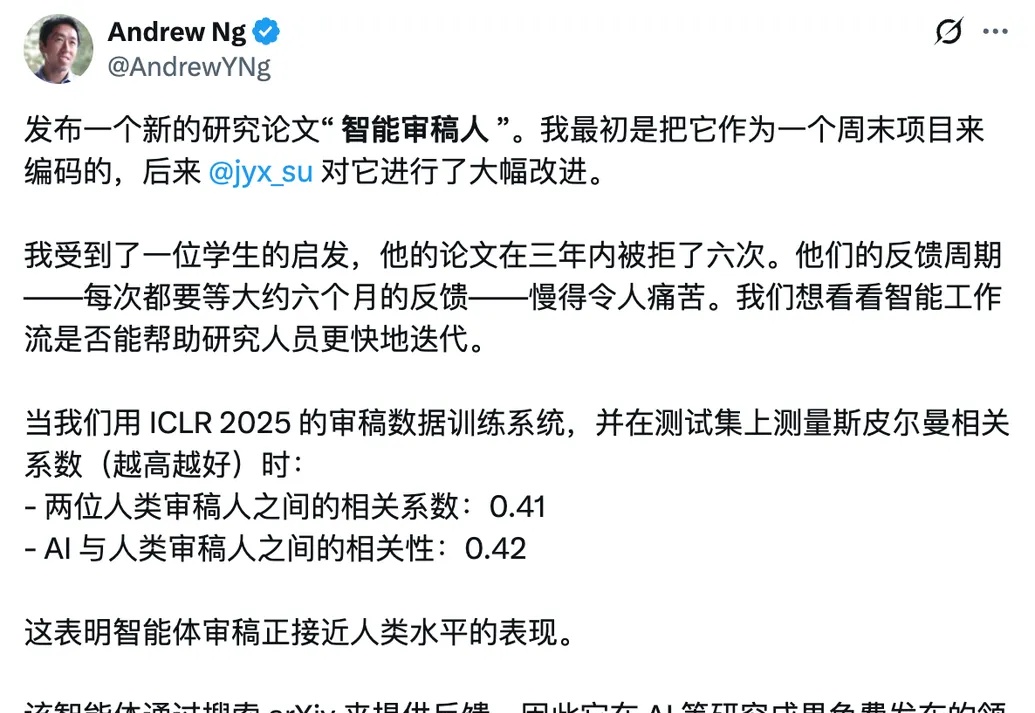
科研人不容易。3年投稿6次全被拒,每次等反馈要半年??机器学习大佬吴恩达听说这位学生的“水逆”遭遇后,亲手搓了个免费的AI论文评审智能体出来。通过在ICLR 2025审稿数据上训练系统,并在测试集中对比发现,该AI审稿系统与人类审稿的相关系数达0.42,和人与人审稿间的0.41相近甚至还高一点。

厦门大学和腾讯合作的最新论文《FlashWorld: High-quality 3D Scene Generation within Seconds》获得了海内外的广泛关注,在当日 Huggingface Daily Paper 榜单位列第一,并在 X 上获得 AK、Midjourney 创始人、SuperSplat 创始人等 AI 大佬点赞转发。

学术展示视频作为科研交流的重要媒介,制作过程仍高度依赖人工,需要反复进行幻灯片设计、逐页录制和后期剪辑,往往需要数小时才能产出几分钟的视频,效率低下且成本高昂,这凸显了推动学术展示视频自动化生成的必要性。

斯坦福大学研究人员提出了Paper2Agent,将静态论文转化为可交互的AI智能体,让学术成果可以直接被「调用」,为科研知识传播开辟了新模式,并为构建AI共研生态奠定基础。

来自牛津大学、新加坡国立大学、伊利诺伊大学厄巴纳-香槟分校,伦敦大学学院、帝国理工学院、上海人工智能实验室等等全球 16 家顶尖研究机构的学者,共同撰写并发布了长达百页的综述:《The Landscape of Agentic Reinforcement Learning for LLMs: A Survey》。

近日,全球权威咨询机构IDC发布《IDC MarketScape: 中国工业大模型及智能体解决方案 2025年厂商评估》。报告选取了中国市场18家工业大模型及智能体解决方案的典型服务商进行重点研究,从现有能力和未来战略两个层面对厂商进行评估,为工业企业选择大模型、智能体服务提供了参考。

近日,全球网络通信顶会 ACM SIGCOMM 2025 在葡萄牙落幕,共 3 篇论文获奖,华为网络技术实验室与香港科技大学 iSING Lab 合作的 DCP 研究成果,获本届大会 Best Student Paper Award (Honorable Mention),成为亚洲地域唯一获奖的论文。
9月2日,AI生物医药公司CHARM Therapeutics宣布完成超额认购的 B 轮融资,共计筹集8000万美元。(约合人民币5.7亿元)