# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
刚刚,人工智能顶会 NeurIPS 公布了今年的最佳论文(包括 Best Paper 和 Best Paper Runner-up,大会注册者可以看到)。
一共有两篇论文获得最佳论文奖:
一是由北京大学、字节跳动研究者共同完成的《Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction》(视觉自回归建模:通过 Next-Scale 预测生成可扩展图像),论文一作为田柯宇(此前因涉攻击内部大模型,被字节起诉)。参见机器之心报道《GPT 超越扩散、视觉生成 Scaling Law 时刻!北大 & 字节提出 VAR 范式》。
机器之心获悉,从 2023 年开始,字节商业化技术团队就在研究图像生成的自回归模型,一直将 VAR 作为高优项目推进,不仅安排多名研究人员重点攻关此技术方向,还投入大量算力资源支持模型训练和实验。该团队近期将发布新的 VAR T2I 模型研究成果,并将对模型开源。
二是由新加坡国立大学、 Sea AI Lab 研究者共同完成的《Stochastic Taylor Derivative Estimator: Efficient amortization for arbitrary differential operators》(随机泰勒导数估计器:任意微分算子的有效摊销),论文一作为 Zekun Shi。
此外,还有两篇论文获得了最佳论文亚军(Best Paper Runner-up):
由厦门大学、清华大学、微软研究者共同完成的《Not All Tokens Are What You Need for Pretraining》(并非所有 token 都是预训练所需的), Zhenghao Lin 和 Zhibin Gou(苟志斌)为共同一作。
由英伟达和阿尔托大学共同完成的《Guiding a Diffusion Model with a Bad Version of Itself》(使用扩散模型的一个糟糕版本引导其自身),论文一作为 Tero Karras。
NeurIPS 2024 将于 12 月 10 日星期二至 12 月 15 日星期日在温哥华举办。本届共收到 15671 篇有效论文投稿,比去年又增长了 27%,但最终接收率低于 2023 年,仅有 25.8%。最佳论文的公布提前引爆了有关此次大会的讨论。
以下是获奖论文的详细信息:
论文 1:Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction

论文简介:在自然语言处理中,以 GPT、LLaMa 系列等大语言模型为例的 Autoregressive(自回归模型已经取得了较大的成功,尤其扩展定律(Scaling Law)和零样本任务泛化能力(Zero-shot Task Generalizability)十分亮眼,初步展示出通往「通用人工智能 AGI」的潜力。
然而在图像生成领域中,自回归模型却广泛落后于扩散(Diffusion)模型:DALL-E、Stable Diffusion、Sora 等模型均属于 Diffusion 家族。
为了「解锁」自回归模型的能力和 Scaling Laws,研究团队从图像模态内在本质出发,模仿人类处理图像的逻辑顺序,提出一套全新的「视觉自回归」生成范式:VAR, Visual AutoRegressive Modeling,首次使得 GPT 风格的自回归视觉生成,在效果、速度、Scaling 能力多方面超越 Diffusion,迎来了视觉生成领域的 Scaling Laws。
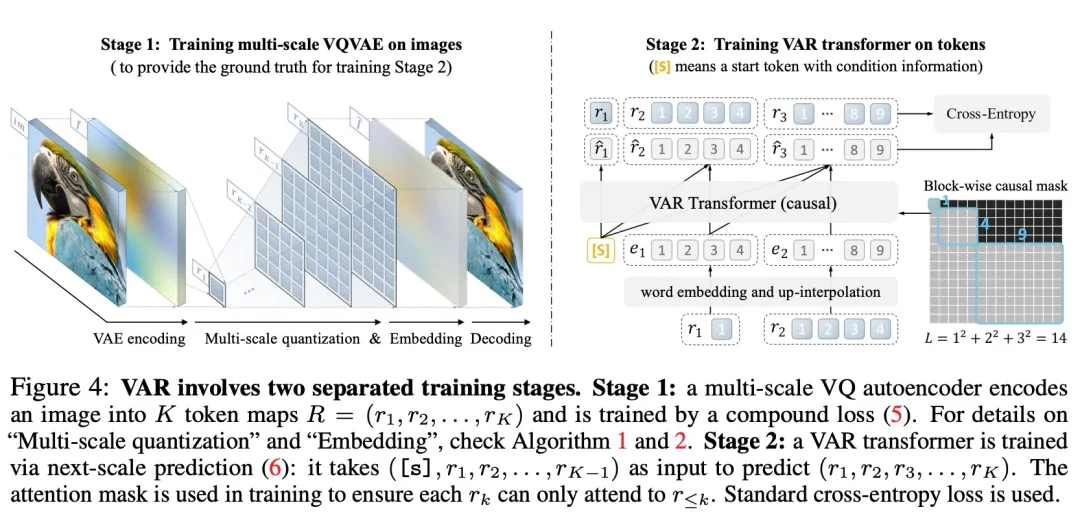

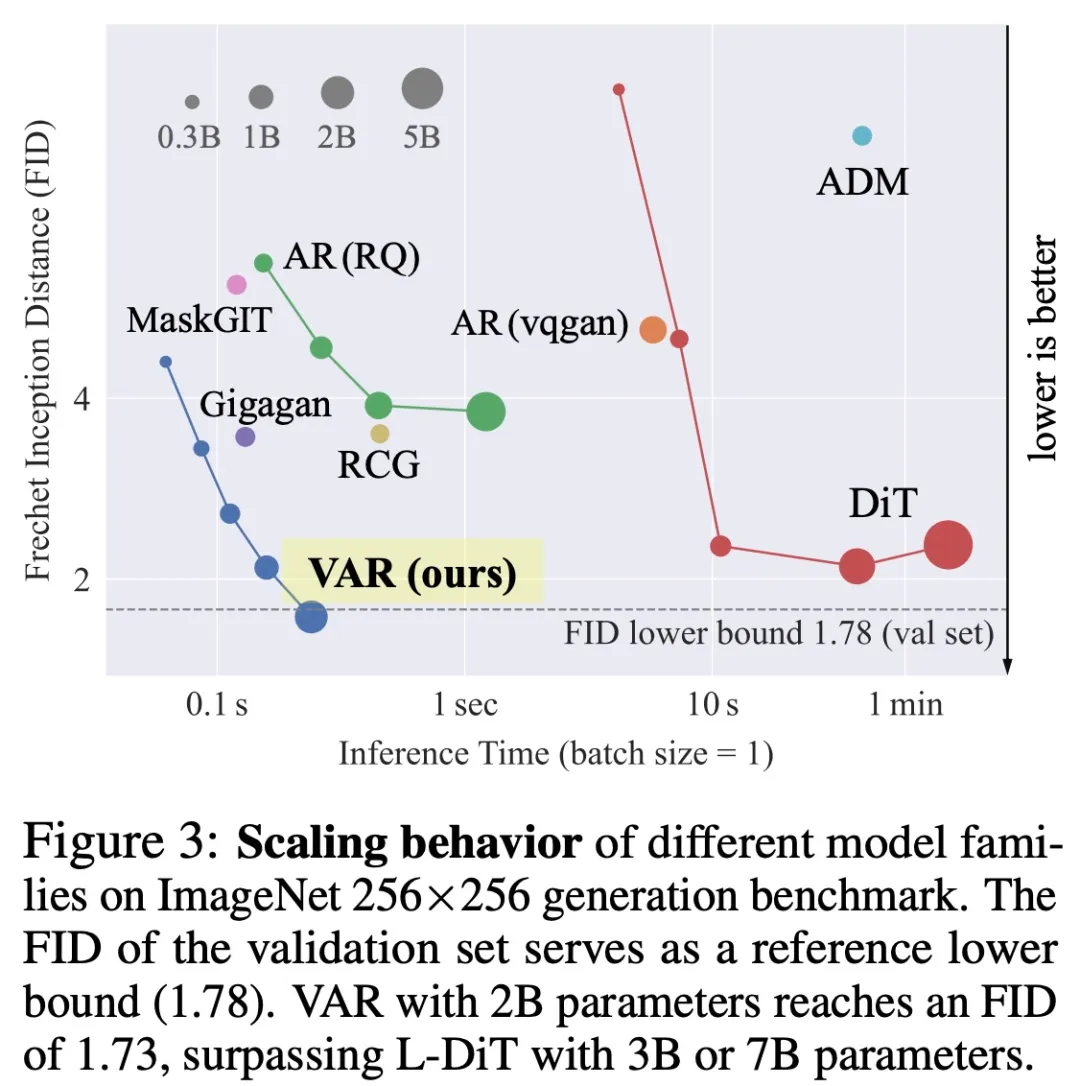
VAR 为如何定义图像的自回归顺序提供了一个全新的视角,即由粗到细、由全局轮廓到局部精调的顺序。在符合直觉的同时,这样的自回归算法带来了很好的效果:VAR 显著提升了自回归模型的速度和生成质量,在多方面使得自回归模型首次超越扩散模型。同时 VAR 展现出类似 LLM 的 Scaling Laws 和零样本任务泛化能力。
论文 2:Stochastic Taylor Derivative Estimator: Efficient amortization for arbitrary differential operators


论文 1:Not All Tokens Are What You Need for Pretraining

论文简介:以前的语言模型预训练方法会统一对所有训练 token 应用下一个 token 预测损失。
但这一范式并非不可挑战。这篇论文的作者首先做出了一个假设:「对于语言模型训练,并非语料库中的所有 token 都同等重要」。
然后,他们分析了语言模型的 token 级训练动态,结果发现不同 token 有着不同的损失模式。
基于这些见解,他们开发了一种新模型 RHO-1。不同于传统语言模型(会学习预测语料库中的每一下个 token),RHO-1 采用了选择性语言建模(SLM),它会选择性地使用与所需分布对齐的有用 token 进行训练。

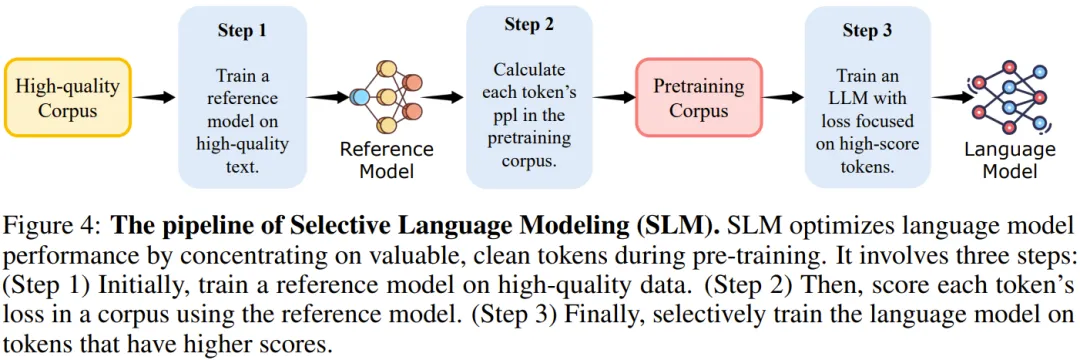
该方法需要使用一个参考模型来给 token 评分,然后再在分数更高的 token 上使用一个重点关注损失(focused loss)来训练模型。
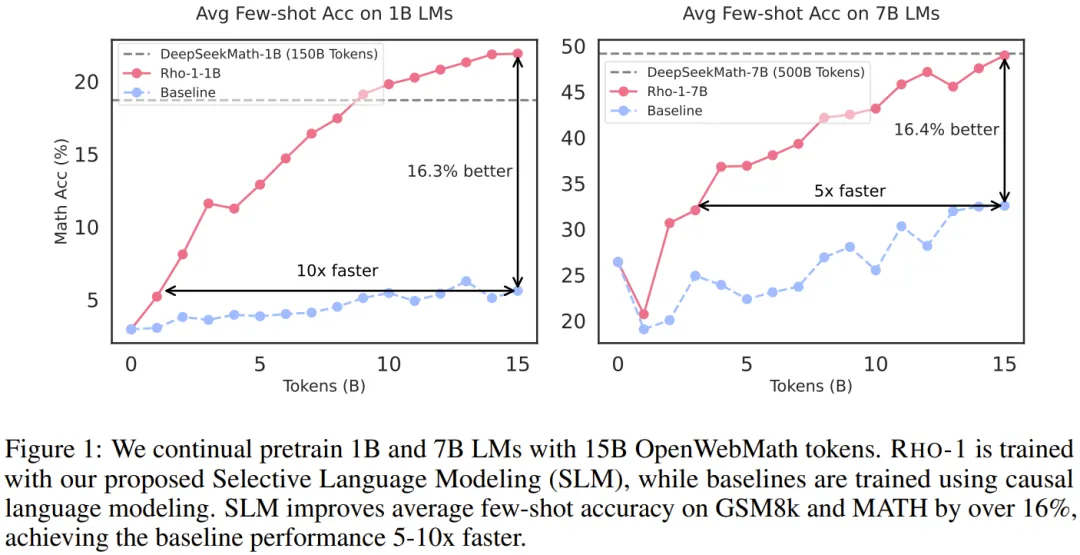
在 15B OpenWebMath 语料库上进行持续预训练时,RHO-1 在 9 个数学任务上的少样本准确率实现了 30% 的绝对提升。经过微调后,RHO-1-1B 和 7B 在 MATH 数据集上分别取得了 40.6% 和 51.8% 的 SOTA 结果 —— 仅用 3% 的预训练 token 就达到了 DeepSeekMath 相当的水平。此外,在对 80B 个通用 token 进行持续预训练时,RHO-1 在 15 个不同任务上实现了 6.8% 的平均提升,数据效率和语言模型预训练的性能都得到了提升。
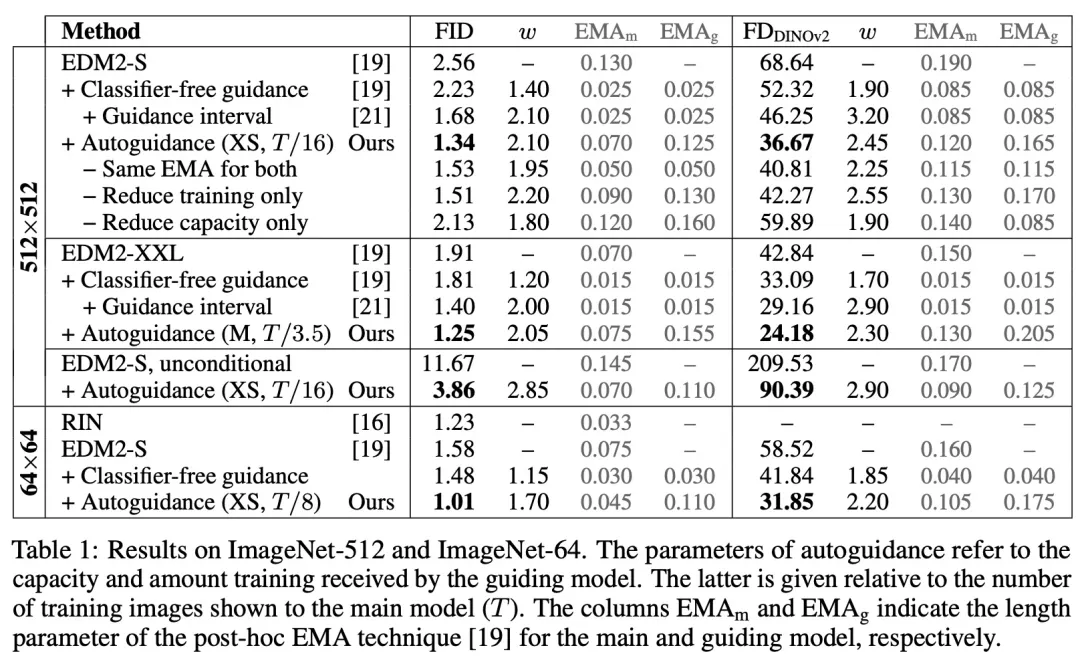
论文 2:Guiding a Diffusion Model with a Bad Version of Itself

论文简介:图像生成扩散模型关注的核心是图像质量、结果的多变程度以及结果与给定条件(例如类标签或文本提示)的对齐程度。
常见的无分类器引导方法是使用无条件模型来引导条件模型,这样既能实现更好的提示词对齐,也能得到更高质量的图像,但代价是多变程度下降。
这些效果似乎本质上是纠缠在一起的,因此很难控制。
基于此,该团队得出了一个令人惊讶的观察结果:通过使用较小、训练较少的模型版本(而不是无条件模型)来引导生成,就可以在不影响多变程度的情况下获得对图像质量的控制。由此,图像质量与多变程度就分离了。
实验表明,这能显著提升 ImageNet 生成效果。他们使用公开可用的网络,为 64×64 分辨率下的生成创造了 1.01 的 FID 记录,为 512×512 创造了 1.25 的 FID 记录。此外,该方法也适用于无条件扩散模型,可极大提高其质量。

文章来自微信公众号“机器之心”




【开源免费】DeepBI是一款AI原生的数据分析平台。DeepBI充分利用大语言模型的能力来探索、查询、可视化和共享来自任何数据源的数据。用户可以使用DeepBI洞察数据并做出数据驱动的决策。
项目地址:https://github.com/DeepInsight-AI/DeepBI?tab=readme-ov-file
本地安装:https://www.deepbi.com/
【开源免费】airda(Air Data Agent)是面向数据分析的AI智能体,能够理解数据开发和数据分析需求、根据用户需要让数据可视化。
项目地址:https://github.com/hitsz-ids/airda
【开源免费】XTuner 是一个高效、灵活、全能的轻量化大模型微调工具库。它帮助开发者提供一个简单易用的平台,可以对大语言模型(LLM)和多模态图文模型(VLM)进行预训练和轻量级微调。XTuner 支持多种微调算法,如 QLoRA、LoRA 和全量参数微调。
项目地址:https://github.com/InternLM/xtuner
【开源免费】LangGPT 是一个通过结构化和模板化的方法,编写高质量的AI提示词的开源项目。它可以让任何非专业的用户轻松创建高水平的提示词,进而高质量的帮助用户通过AI解决问题。
项目地址:https://github.com/langgptai/LangGPT/blob/main/README_zh.md
在线使用:https://kimi.moonshot.cn/kimiplus/conpg00t7lagbbsfqkq0
