
打破AI体验天花板,联发科成了Agent跨端生态“铺路人”
打破AI体验天花板,联发科成了Agent跨端生态“铺路人”面向一系列智能体时代的技术挑战和行业矛盾,联发科的思路和角色定位都非常明确:做好“赋能者”。终端层,联发科有着全场景芯片矩阵,这些芯片可以在各类智能终端中落地,成为智能体时代的AI算力底座。
来自主题: AI资讯
9056 点击 2026-05-16 10:35
 搜索
搜索
面向一系列智能体时代的技术挑战和行业矛盾,联发科的思路和角色定位都非常明确:做好“赋能者”。终端层,联发科有着全场景芯片矩阵,这些芯片可以在各类智能终端中落地,成为智能体时代的AI算力底座。

在过去很长的一段时间里,英伟达都被迫只能站在中间,一边是美国出口管制,一边是中国市场需求,老黄当然想找到一个突破口。也就是在同一天晚上,Anthropic发了一篇很不寻常的文章。文章标题叫《2028:Two scenarios for global AI leadership》,讲的是2028年全球AI领导权的两种可能。

Anthropic 刚刚出了一份 36 页的创始人手册:创建一家 AI Native 的公司,几个人,做几百人的事儿。由着这个问题,手册把创业拆成四个阶段(想法、MVP、上线、规模化),每个阶段讲清楚该做什么、容易踩什么坑、Claude 的三个产品形态(Chat、Cowork、Code)分别在什么时候用

今天凌晨,俄勒冈州立大学杰出教授(荣休)、arXiv 计算机科学分区 CoRR 的机器学习板块首席版主 Thomas G. Dietterich 宣布:根据我们的行为准则,在论文上署名即表示每位作者对其全部内容承担完全责任,无论这些内容是如何生成的。

上个月我遇到一个挺尴尬的事。同事指着屏幕上一张零件截图问我:"这个法兰盘,外径多少,孔位怎么分布的?"我张嘴比划了半天,最后打开SolidWorks重新画了一遍给他看。明明脑子里是完整的三维造型,传到另一个人那里就变成了一堆说不清的数字和手势。
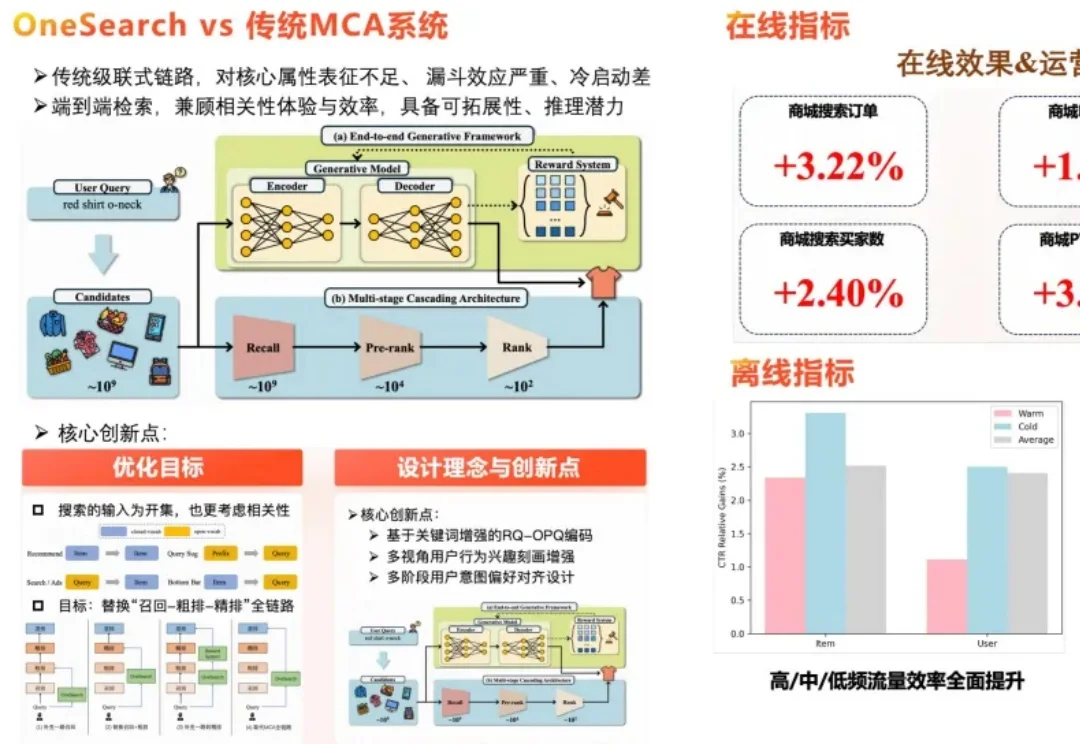
针对生成式检索范式在电商搜索场景下面临的复杂查询理解不足、用户潜在意图挖掘乏力、奖励系统易过拟合历史窄偏好等落地瓶颈,快手技术团队在已规模化部署的工业级生成式搜索框架 OneSearch 基础上,发布了一篇系统性升级的研究论文,正式推出新一代框架 OneSearch-V2。

这款 AI 工具名为 RetinaMind,利用视网膜图像训练 AI 模型,以百分比形式呈现对视网膜图像的置信度,通过这样的方式在疾病早期对 ASD 以及 ADHD 进行识别和诊断,准确率达 89%。不仅如此,该工具还可以帮助分析疾病基因机制(如 ABCA4)的潜在变化。

这两天打开X,发现一个开源项目刷屏了——Hyperframes。GitHub上两天干了17.4k star,1.6k fork,Codex、Cursor、Claude Code的插件全线覆盖。

你可以直接跟 Claude 说想做什么,它帮你写代码、刷固件、装应用,几分钟之后,这台信用卡大小的设备就跑起了你要的东西。这台小设备叫 M5Stack Cardputer ADV,基于 ESP32-S3 芯片,真的只有信用卡那么大。

今天,MiniMax Agent 桌面端完成了一次重大更新。新加入了一个名为 Mavis 的模式(其实它是「MiniMax as a Jarvis」的缩写)。MiniMax 给它的 Agent Team 基础设施起的名字叫做 Team Engine,引擎下面挂着三类核心角色:Leader、Worker、Verifier。顾名思义,一类做管理,一类干活,一类验收。