# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
尽管扩散模型(Diffusion Model)与流匹配(Flow Matching)已经把文本到图像生成(Text-to-Image, T2I)推向了更高的视觉质量与可控性,但他们通常在推理时需要数十步网络迭代,限制了其对于一些需要低延迟,Real-Time 的应用。
为了把推理步数降下来,现有路线通常依赖知识蒸馏(Distillation):先训练一个多步教师模型,再把能力迁移到少步学生模型。但这条路的代价同样明显 —— 既依赖预训练教师,又引入了额外的训练开销,并在「从零训练(from scratch)」与「极少步高质量」之间留下了长期空白。
近日,香港大学(The University of Hong Kong)与 Adobe Research 联合发布 Self-E(Self-Evaluating Model):一种无需预训练教师蒸馏、从零开始训练的任意步数文生图框架。其目标非常直接:让同一个模型在极少步数也能生成语义清晰、结构稳定的图像,同时在 50 步等常规设置下保持顶级质量,并且随着步数增加呈现单调提升。


扩散 / 流匹配范式本质上是在学习一张「局部向量场」:给定噪声状态,预测下一步该往哪里走。这个监督信号在「小步、密集积分」时非常有效,但一旦尝试「大步跳跃」,误差会被轨迹曲率放大,生成往往滑向平均解、语义漂移或结构坍塌。
Self-E 的切入点是一个根本上的范式改变:我们能否不再执着于「每一步走得对不对」,而是把训练重心转向「落点好不好」?也就是把目标从「轨迹匹配(trajectory matching)」转变为「落点评估(destination/landing evaluation)」。
换句话说,传统 Diffusion Model 训练强调「在起点对齐局部方向」;Self-E 强调「在落点评估结果并给出纠偏方向」。监督位置的改变,带来了训练信号性质的改变:从静态监督变成动态反馈。
作者在项目主页用动图展示了这两者的区别:
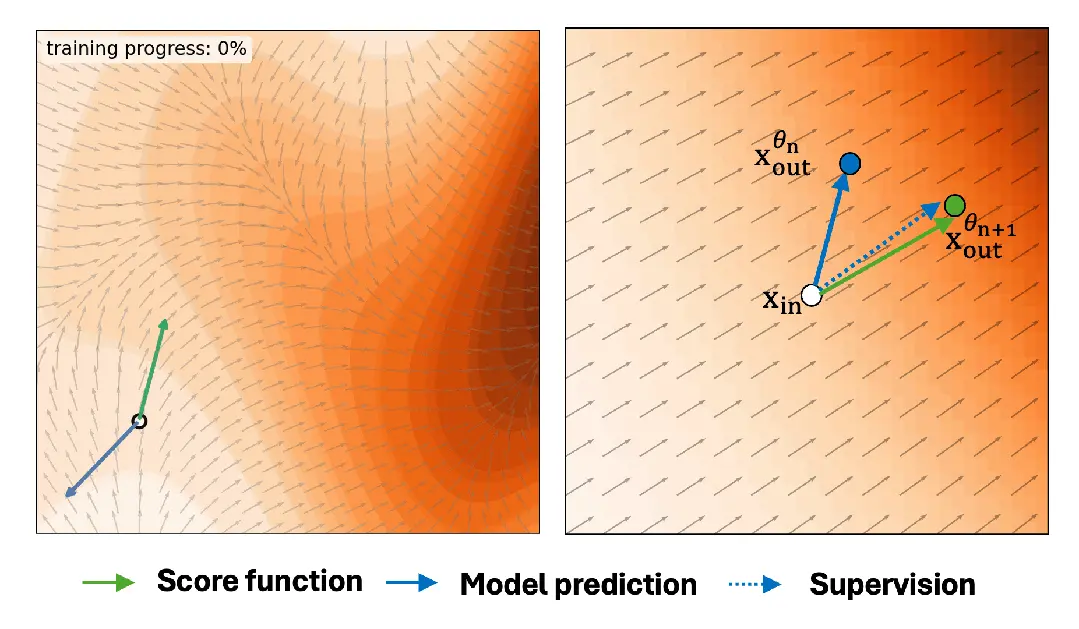
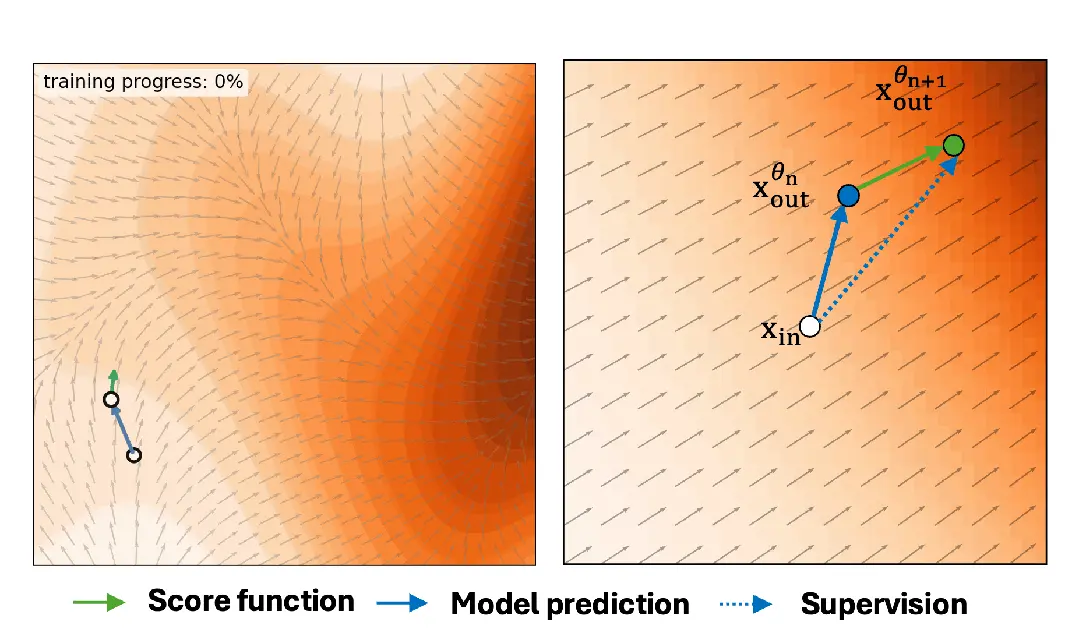
这也是为什么模型在测试阶段有少步推理能力:扩散模型在测试时只能逐步跟随当前点预测的最好局部路径,最终走到全局最优;而 Self-E 在训练阶段就逐步学会了走向全局最优的落点。
这也不同于目前多数少步生成模型所采用的学习轨迹的积分,如 Consistency Model, Mean Flow; Self-E不局限于沿着预定义的轨迹走,而是直接关心每步结果好不好,对不对。
Self-E 用同一个网络在两种「模式」下工作:一方面像 Flow Matching 一样从真实数据学习分布的局部结构;另一方面用「模型自身正在学到的局部估计」去评估自生成样本,形成自反馈闭环。
1)从数据学习:Learning from Data
2)自我评估学习:Learning by Self-Evaluation
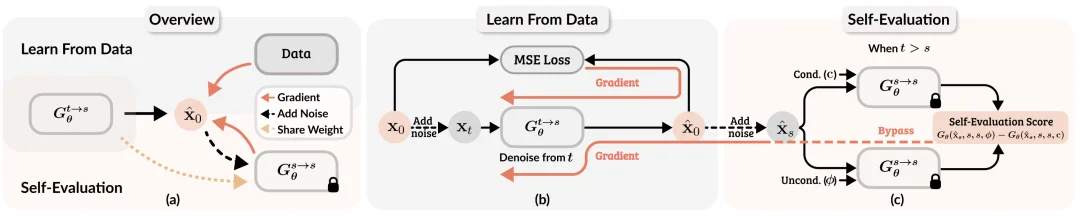
Self-E 在理论上把评估写成分布级目标(例如以反向 KL 为代表的分布匹配视角),但真正落地的难点在于:真实分布与生成分布的 score 都不可得。
Self-E 的关键观察是:模型在「从数据学习」阶段会逐步学到某种条件期望形式,而该量与 score 通过 Tweedie’s formula 存在联系,因此可以用「正在训练的模型」去近似提供评估方向。
在实现上,作者发现理论目标中包含「classifier score term」等项,并实证发现仅使用 classifier score 项就足够有效,甚至更利于收敛,从而避免早期还要额外训练一个用于 fake score 的模型分支。
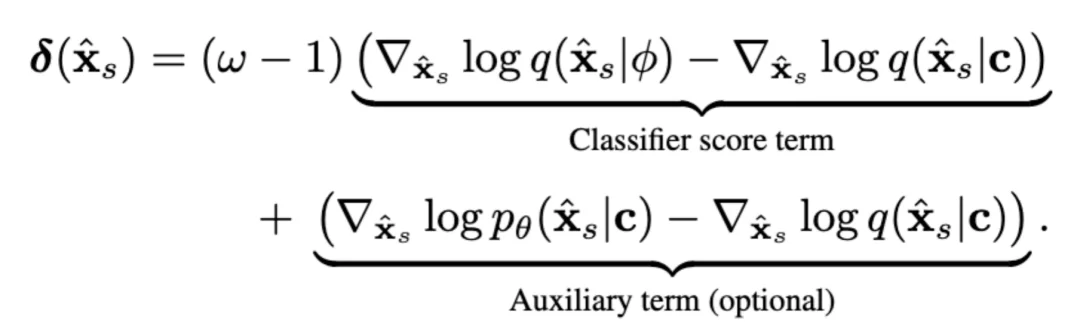
为了把这种「评估方向」变成可训练的损失,Self-E 采用 stop-gradient 的双前向构造 pseudo-target,通过最小化 MSE 诱导出与所需方向一致的梯度;并在最终目标中将数据驱动损失与自评估损失进行混合加权。
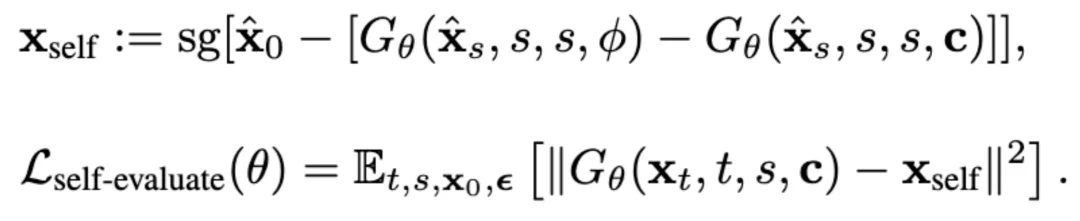
最终,我们可以用一个统一的形式来训练:
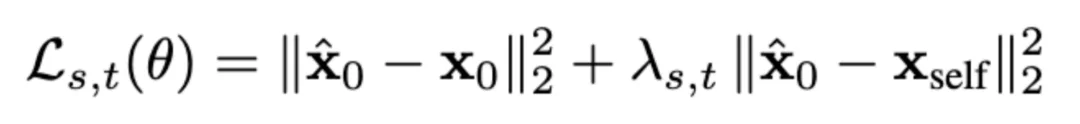
其中,等式右边第一项正是 Learning-from-data 的目标,而第二项对应 Self-Evaluation。
在推理阶段,Self-E 与扩散 / 流匹配一样进行迭代去噪,但不同之处在于:由于训练中已经显式学习「长距离落点」的质量与纠偏方向,它可以在非常少的步数下保持可用的语义与结构,同时在增加步数时继续提升细节与真实感。
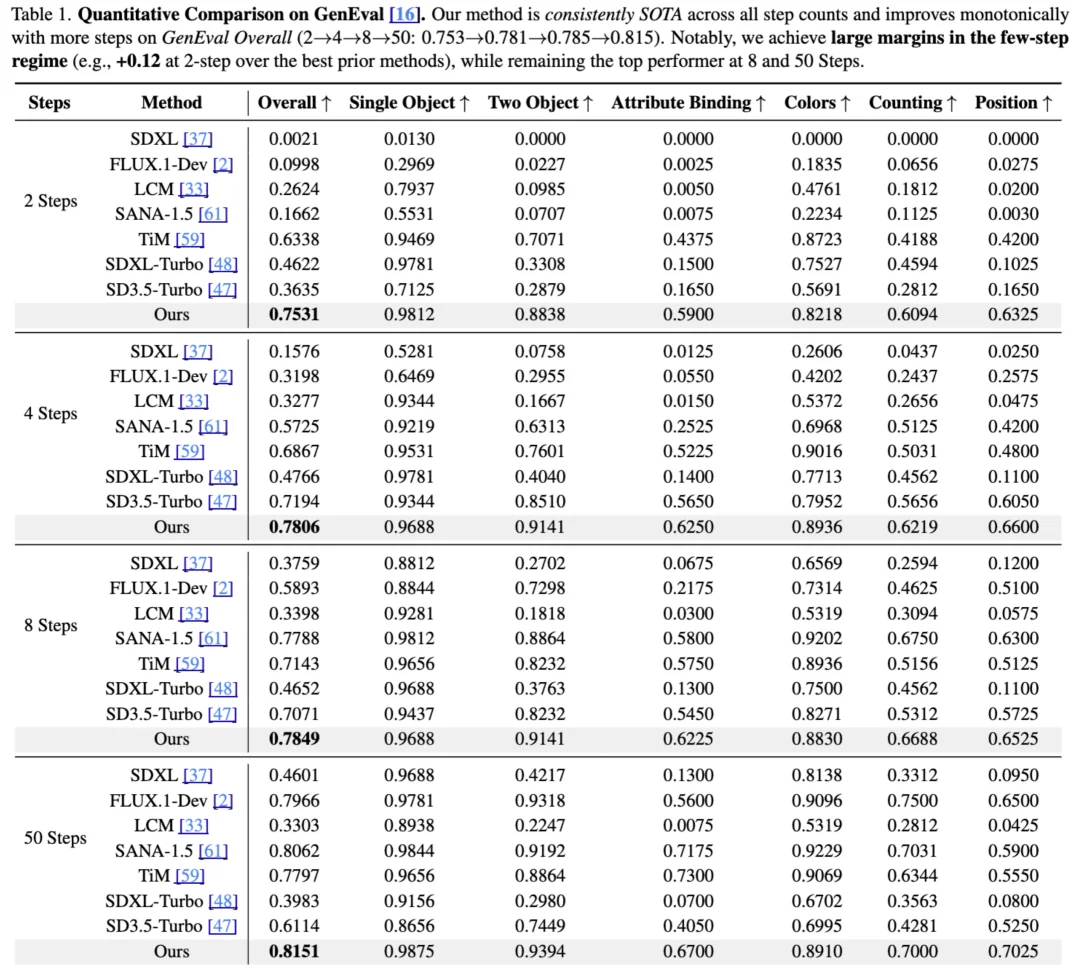
在 GenEval 基准上,Self-E 对比其他方法取得全面领先,并且随着步数增加呈现单调提升。更关键的是少步区间的「断层式」优势:在 2-step 设置下,Self-E 相比当时最佳对比方法的提升约为 +0.12(0.7531 相比 0.6338),而多种传统扩散 / 流匹配模型在 2-step 下几乎无法生成可用结果。

从更宏观的视角看,Self-E 把训练过程组织成一个类似强化学习中的「环境 — 智能体(environment–agent)闭环」:
作者在项目主页指出:这种内部评估器在角色上接近「可查询的学习型奖励模型」,为后续把强化学习(RL)更系统地引入视觉生成训练提供了新的接口与想象空间。
Self-E 的价值不只是在「少步生成」这一条指标上跑得更快,而在于它把文生图训练范式从「沿着既定轨迹走」推进到「学会评估落点并自我纠偏」:在不依赖预训练教师蒸馏的前提下,让单一模型同时覆盖极低时延与高质量长轨迹两种需求,并在不同推理预算下保持可扩展的性能曲线。
对内容创作与生成式系统落地而言,「one model, any compute」的工程意义非常直接:同一个 checkpoint 可以按场景动态选择步数 —— 交互式场景用 1~4 步追求即时反馈,高质量离线渲染用 50 步追求细节上限;而训练侧则绕开了教师蒸馏链路,把「从零训练 + 少步推理」真正拉回到可讨论、可复现、可扩展的主流路径上。
文章来自于微信公众号 “机器之心”,作者 “机器之心”


【开源免费】Browser-use 是一个用户AI代理直接可以控制浏览器的工具。它能够让AI 自动执行浏览器中的各种任务,如比较价格、添加购物车、回复各种社交媒体等。
项目地址:https://github.com/browser-use/browser-use
【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
【开源免费】graphrag是微软推出的RAG项目,与传统的通过 RAG 方法使用向量相似性作为搜索技术不同,GraphRAG是使用知识图谱在推理复杂信息时大幅提高问答性能。
项目地址:https://github.com/microsoft/graphrag
【开源免费】Dify是最早一批实现RAG,Agent,模型管理等一站式AI开发的工具平台,并且项目方一直持续维护。其中在任务编排方面相对领先对手,可以帮助研发实现像字节扣子那样的功能。
项目地址:https://github.com/langgenius/dify
【开源免费】RAGFlow是和Dify类似的开源项目,该项目在大文件解析方面做的更出色,拓展编排方面相对弱一些。
项目地址:https://github.com/infiniflow/ragflow/tree/main
【开源免费】phidata是一个可以实现将数据转化成向量存储,并通过AI实现RAG功能的项目
项目地址:https://github.com/phidatahq/phidata
【开源免费】TaskingAI 是一个提供RAG,Agent,大模型管理等AI项目开发的工具平台,比LangChain更强大的中间件AI平台工具。
项目地址:https://github.com/TaskingAI/TaskingAI
