
复星医药AI平台辅助决策,打造AI+X智慧医疗生态|工赋上海·链主
复星医药AI平台辅助决策,打造AI+X智慧医疗生态|工赋上海·链主当下,人工智能(AI)技术正深度重塑医药健康行业格局。作为上海市“工赋链主”培育企业以及全球化医药健康产业集团,上海复星医药(集团)股份有限公司(简称“复星医药”),在药物研发、医学影像、精准医疗等领域进行AI布局,提升研发效率,推动行业发展。
来自主题: AI资讯
8248 点击 2025-04-10 15:19
 搜索
搜索
当下,人工智能(AI)技术正深度重塑医药健康行业格局。作为上海市“工赋链主”培育企业以及全球化医药健康产业集团,上海复星医药(集团)股份有限公司(简称“复星医药”),在药物研发、医学影像、精准医疗等领域进行AI布局,提升研发效率,推动行业发展。

谷歌Deep Research重大升级,搭载全球顶尖Gemini 2.5 Pro模型。5分钟生成46页学术论文、复杂报告转为10分钟播客。性能超OpenAI DR 40%,价格仅为其1/10。

好消息,由谷歌最新的 Gemini 2.5 Pro 模型提供支持的 Deep Research(深度研究)正式发布!坏消息,目前仅 Gemini Advanced 付费会员可体验。

随着 VR/AR、游戏娱乐、自动驾驶等领域对 3D 场景生成的需求不断攀升,从稀疏视角重建 3D 场景已成为一大热点课题。
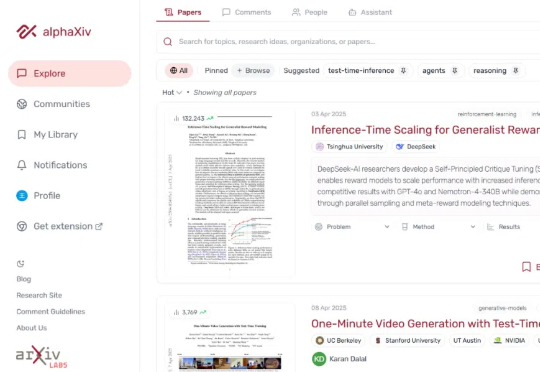
刚刚,alphaXiv 推出了新功能「Deep Research for arXiv」,该功能可协助研究人员更高效地在 arXiv 平台上进行学术论文的检索与阅读,显著提升文献检索及研究效率。
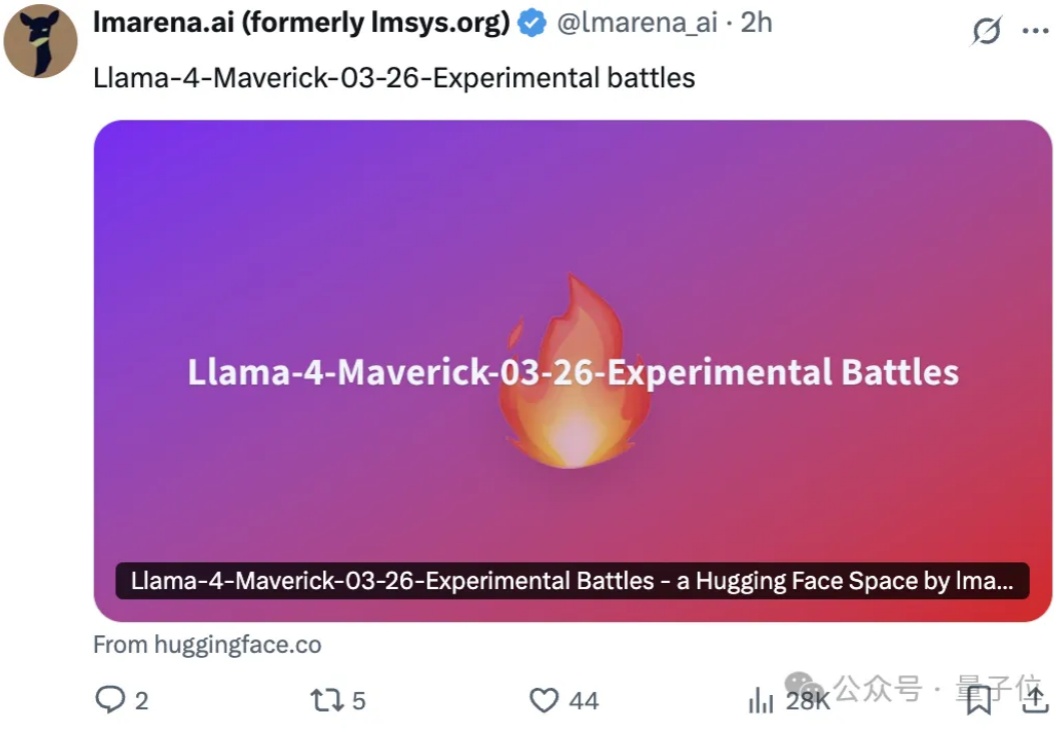
Llama 4真要被锤爆了,这次是大模型竞技场(Chatbot Arena)官方亲自下场开怼:
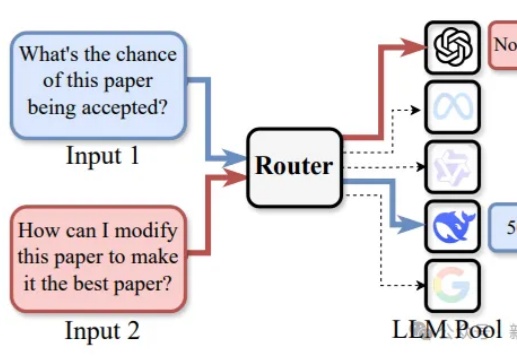
路由LLM是指一种通过router动态分配请求到若干候选LLM的机制。论文提出且开源了针对router设计的全面RouterEval基准,通过整合8500+个LLM在12个主流Benchmark上的2亿条性能记录。将大模型路由问题转化为标准的分类任务,使研究者可在单卡甚至笔记本电脑上开展前沿研究。

Agentic AI 的 3 要素是:tool use,memory 和 context,围绕这三个场景会出现 agent-native Infra 的机会。
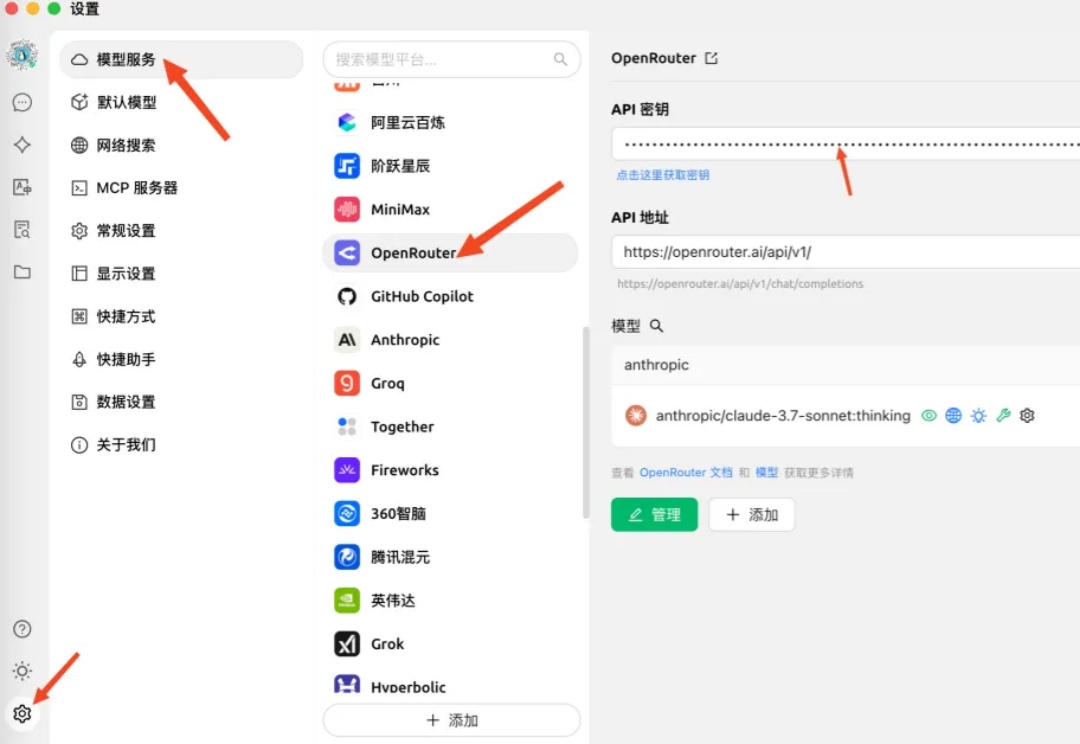
AI菩萨OpenRouter连发两大招宣布推出两项重大更新。

据 The Information 报道,Glean,一家为企业开发搜索聊天机器人的公司 ,正在与投资者进行谈判,可能筹集数亿美元的新融资,包括用于在招标中回购员工股份的资金。