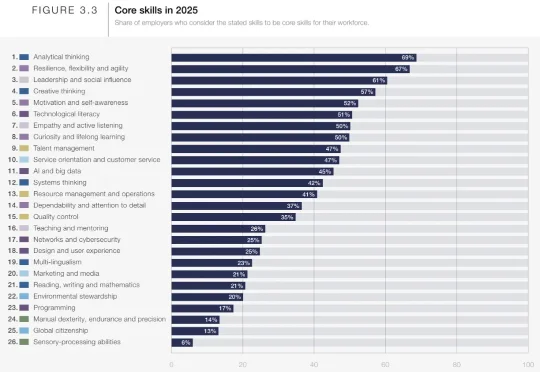
几千年都没考过这个?谷歌「最毒」AI考局,专测你在压力下怎么做人
几千年都没考过这个?谷歌「最毒」AI考局,专测你在压力下怎么做人最近,Google Research推出了一个叫Vantage的实验项目,就把这件事给干了。Vantage项目由谷歌联合纽约大学开发,主要设想是利用GenAI模拟团队协作场景,以此来开发和测量被测试者的软技能。
来自主题: AI技术研报
10231 点击 2026-05-03 23:04
 搜索
搜索
最近,Google Research推出了一个叫Vantage的实验项目,就把这件事给干了。Vantage项目由谷歌联合纽约大学开发,主要设想是利用GenAI模拟团队协作场景,以此来开发和测量被测试者的软技能。
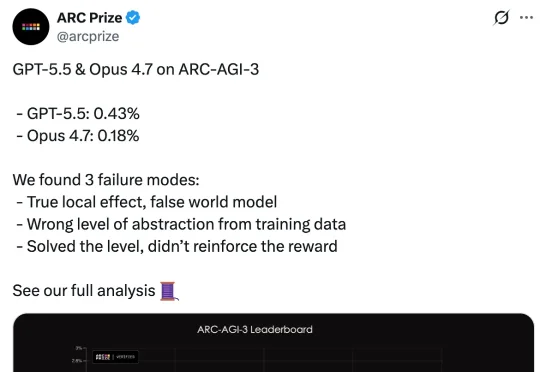
近日,ARC Prize 官方发布了针对这两款顶级模型的详细分析报告,结果令人震惊:在面对未见过的逻辑任务时,两者的表现得分均低于 1%,GPT-5.5 得分 0.43%,Claude Opus 4.7 得分 0.18%。

小扎又出手了,这次瞄准的是人形机器人。 Meta正式完成对机器人AI初创公司Assured Robot Intelligence(简称 ARI)的收购。这家公司专注于机器人智能底层技术,由华南农业大学、中山大学校友王晓龙联合创办。
近日,AI编程智能体初创公司 Factory 完成1.5亿美元C轮融资,投后估值达到15亿美元,正式跻身独角兽行列。本轮由Khosla Ventures领投,Sequoia Capital、Blackstone、Insight Partners、Evantic Capital、20VC、NEA和Mantis VC参与跟投。

刚刚的消息,Cloudflare 联合 Stripe 发布了一份新协议,Agent 现在可以独立成为 Cloudflare 的客户。它能自己创建账户、订阅付费方案、注册域名、拿到 API token,然后直接部署代码

ElatoAI 是一个开源免费的实时AI语音交互系统,采用Arduino 编程,运行在乐鑫 ESP32 主控制器上,通过安全WebSocket连接至部署在Deno边缘函数构建的服务端,通过OpenAI Realtime API等技术实现低成本、长时长、跨设备的自然对话体验,支持多种AI模型,

这不是恐怖故事,也不是田螺姑娘的寓言故事,而是 3 月 17 日,HooRii 在 Kickstarter 上线的众筹项目「ClawStage」的宣传。它的定位是“OpenClaw 的现实世界游乐场”——用一个小方块,让 OpenClaw 来到现实世界,并能担任你的家庭管家。

智元机器人的办公室里,最近员工们一上班就能看到机器人熟练地切着水果:这么全面的能力是如何做到的?答案是直接在真实环境中搞大规模分布式强化学习训练。它们使用的是全新的具身智能训练范式:面向通用机器人策略的分布式多机强化学习(LWD)。这一套技术捅破了当前VLA的「天花板」。

OpenAI刚用Deep Research抢了先手,谷歌直接掀桌!DeepMind祭出研究智能体双杀,Max版质量评分从66.1%暴拉到93.3%,知识工作自动化的军备竞赛正式进入贴身肉搏。

今天,大洋彼岸,硅谷自动驾驶领域的秘密,终于有大佬站出来分享了。如果你对自动驾驶、人形机器人中炙手可热的 VLA、世界模型还有疑惑,全球“物理 AI” 领域头部的基础设施平台 Applied Intuition 两位创始人:CEOQasar Younis、CTO Peter Ludwig的分享可真的是太对口了。