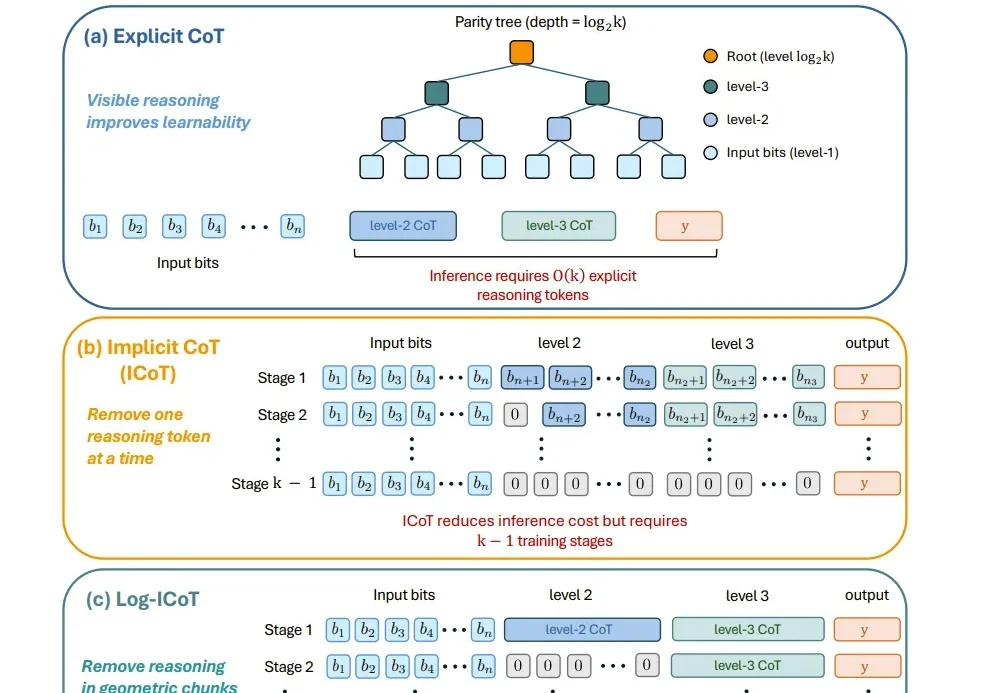
AI真的有意识了吗?《降临》原作万字长文反驳Hinton!
AI真的有意识了吗?《降临》原作万字长文反驳Hinton!AI 是否有意识了?Anthropic 在 Claude 内部发现了能驱动作弊甚至勒索的「情绪向量」,三大实验室同时下注 AI 意识研究;Hinton 认为 AI 已经有意识了,而科幻作家姜峯楠随即在《大西洋月刊》发万字长文全面否定;哈萨比斯从行业内部划清界限。这个问题的答案,正在重新定义通往 AGI 的路线图。
来自主题: AI资讯
9566 点击 2026-06-08 09:50