ARC-AGI-3近被完美攻破,这个Harness能让AI掌握物理学家思维
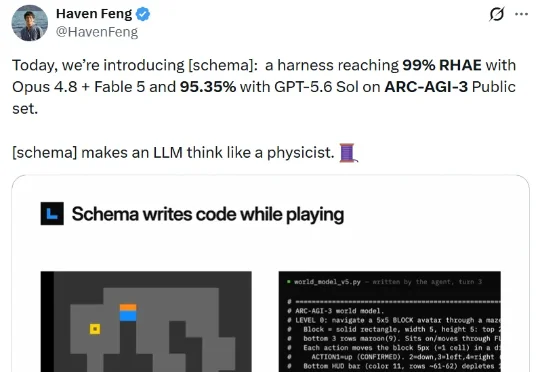
ARC-AGI-3近被完美攻破,这个Harness能让AI掌握物理学家思维7 月 16 日,伯克利博士后 Haven Feng 的一条推文火了。原因无他,结果很震撼:在 ARC-AGI-3 Public 集上,一套名为 [schema] 的智能体框架,与 Claude Opus 4.8、Fable 5 组合后达到 98.98% 的 RHAE;换成 GPT-5.6 Sol 组合,分数也有 95.35%。
来自主题: AI技术研报
9820 点击 2026-07-18 14:22