
Google被曝正在研发一颗新的服务器AI芯片,把Gemini固化到硬件里
Google被曝正在研发一颗新的服务器AI芯片,把Gemini固化到硬件里刚刚,The Information报道,Google正在搞一颗代号「Frozen v2」的服务器芯片,打算把Gemini的部分架构直接固化进硬件里。
来自主题: AI资讯
6393 点击 2026-07-21 10:52
 搜索
搜索
刚刚,The Information报道,Google正在搞一颗代号「Frozen v2」的服务器芯片,打算把Gemini的部分架构直接固化进硬件里。

Databricks 表示 正在进行由 Coatue Management 领投的新一轮融资,公司估值为 1880 亿美元,比去年 12 月上次融资后的估值增长 40%,也高于上个月 The Information 报道 公司曾在考虑的 1750 亿美元估值。

这便是中国电信人工智能研究院(TeleAI),刚刚在WAIC 2026提出的新技术路线;其背后这套融合AI、通信和网络的技术体系,则是智传网(AI Flow)。就在此次发布前一天,智传网(AI Flow)还拿下了WAIC大会最高奖项卓越人工智能引领者奖(SAIL)中的赋能(Applicative)奖。
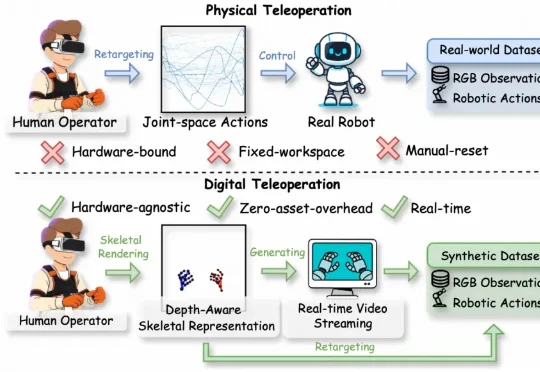
阿里巴巴达摩院的最新工作RynnWorld-Teleop对此给出的方案是:用生成式世界模型替代真实机器人。操作员的手势驱动一个实时视频生成器,由“数字世界中的机器人”完成全部视觉演示,同时自动获得关节级的动作标签。该方案被称为数字遥操作(Digital Teleoperation)。
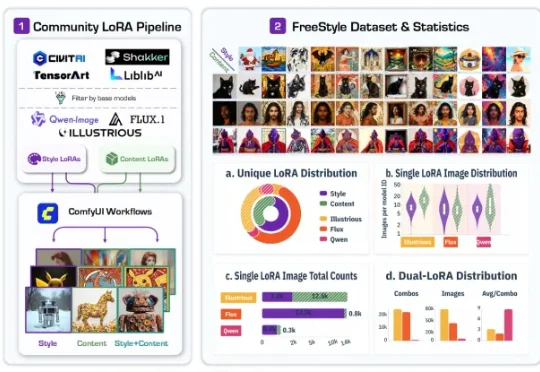
最近,一篇名为 FreeStyle: Free Control of Style-Content Dual-Reference Generation from Community LoRA Mining 的工作引起了不少关注。换句话说,FreeStyle 研究的是 style-content dual-reference generation,也就是「内容 - 风格双参考生成」。
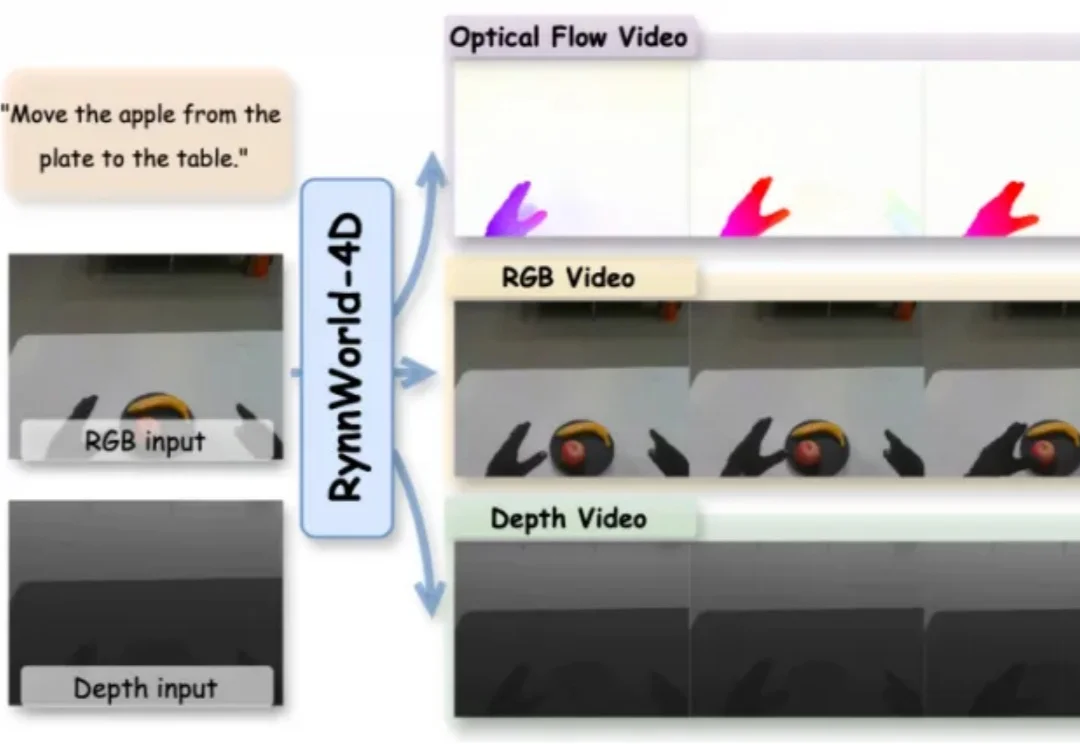
近两年,视频生成模型在具身智能领域受到持续关注。从 UniPi、SuSIE 到各类 action-conditioned video generation 变体,其核心思路一致:先由模型生成一段未来视频,再从中提取动作信号供机器人执行。

机器之心编辑部 由 OpenAI 前首席技术官 Mira Murati 创立的 AI 初创公司 Thinking Machines Lab,刚刚发布了自研 AI 模型 Inkling。与 OpenAI、Anthropic 或 Google 的旗舰模型不同,Inkling 是一款开放权重模型,外部开发者和企业可以直接下载,并根据自身需求进行修改。

3D空间数据的瓶颈,从来不是算法,而是标注。
近日,自监督学习新工作 VISReg(Variance-Invariance-Sketching Regularization)获图灵奖得主 Yann LeCun 连续转发并给予高度认可 —— 他在转发时评价道「VICReg begat SIGReg which begat VISReg」(VICReg 孕育了 SIGReg,SIGReg 又孕育了 VISReg),

“购买使用AI时,钱可能要付两遍!”