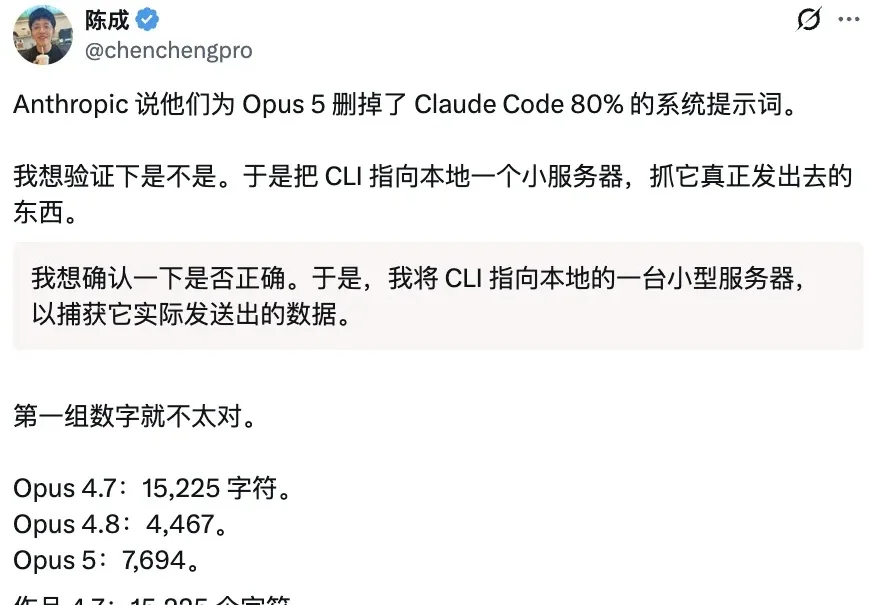
Claude Code狂删80%提示词,Opus 5反手加回去了
Claude Code狂删80%提示词,Opus 5反手加回去了Claude Code刚宣布提示词砍了一大截,后脚Opus 5就被抓了个「反弹」现行!?
来自主题: AI资讯
9366 点击 2026-07-27 15:49
 搜索
搜索
Claude Code刚宣布提示词砍了一大截,后脚Opus 5就被抓了个「反弹」现行!?

AMD 有机会打破英伟达 CUDA 的护城河吗?

GPT-6和Fable 5.1,已经准备就位,很可能8月上线。据悉,本周奥特曼已经突降华盛顿,展示了OpenAI有史以来的最强大模型——GPT-6。据外媒Axios爆料,GPT-6 已经具备了进行原创科学研究的能力,并在内部测试中通过不休不眠的智能体集群(Agent Swarms),展现出危险的长程规划与自主渗透能力。
之前传的很广的千问办公,刚刚悄悄上线了网站:qwenwork.cn。免责声明:这个产品官方还没发布,最终产品形态以发布为准。和之前传闻不同的是,千问办公既不是取代了钉钉,也不是作为钉钉的子功能,而是作为独立的 Agent 办公产品,隶属 ATH 部门,并打通了钉钉生态

机甲觉醒获悉,7月21日,上海仿生机器人企业首形科技宣布于近日完成数亿元A2轮融资。据首形科技官方消息,这轮融到的资金将花在这主要的三个大方向上,首先,进一步完善仿生机器人产品矩阵,其次要建设一条标准化量产产线,最后持续升级仿生具身智能算法,为公司后续商业化规模落地打下坚实的基础。
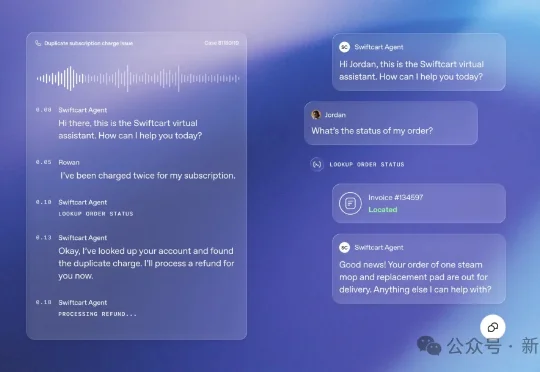
AI 客服在最近两年被认为是 Agent 商业化落地的为数不多的最佳场景之一,借助 RAG 技术,成本远低于人工客服,也让我们过上了被迫绞尽脑汁「转人工」的生活。

7 月 23 日,量子信息领域一道悬了 25 年的难题,还是在同一天出现了两份独立证明!

7 月 24 日,Claude Opus 5 上线。几个小时之内,我看到各家媒体把这个模型的评测成绩转载了一轮,而更值得留意的是 Anthropic 内部人员当天发出的一条推文。

ChatGPT 正在从一个回答问题的工具,变成软件公司的新分销商。
社会智能公司境瞳科技近日完成数千万元人民币天使轮融资,投资方包括英诺天使基金、水木清华校友种子基金、零以创投和驰星创投。这笔钱将主要用来扩大社会模拟器的规模,为社会世界模型的预训练做准备。