
AI爆改陶哲轩30年主页,顺手揪出两个藏了20多年的bug
AI爆改陶哲轩30年主页,顺手揪出两个藏了20多年的bug都以为AI应该先去替数学家证定理,陶哲轩却让它搬30年前的旧网页。一天迁走560篇论文,还从他二十多年前亲手写的老代码里揪出两个连他都不知道的bug。
来自主题: AI资讯
5709 点击 2026-07-14 11:09
 搜索
搜索
都以为AI应该先去替数学家证定理,陶哲轩却让它搬30年前的旧网页。一天迁走560篇论文,还从他二十多年前亲手写的老代码里揪出两个连他都不知道的bug。
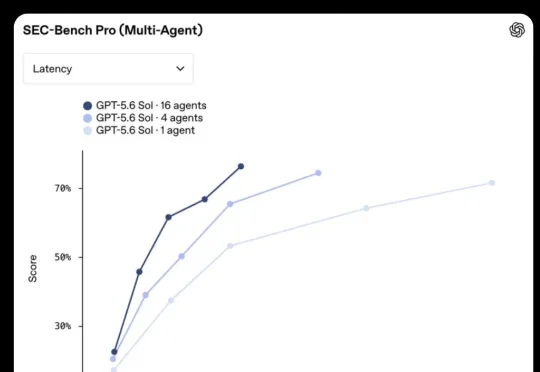
昨儿刚出的GPT-5.6,用不到一小时,就完成了一道存在了半个世纪的图论猜想证明。而这道题呢,来头也还真不小,就是大名鼎鼎的循环双覆盖猜想(Cycle Double Cover Conjecture)。

研究团队提出了符号嵌入量子算法(Sign Embedding Quantum Algorithms),形成了一篇84页的量子算法论文。可以说,相比此前主要解决研究者给定的开放数学问题,这一次,AIM开始参与研究问题的提出与方向探索。
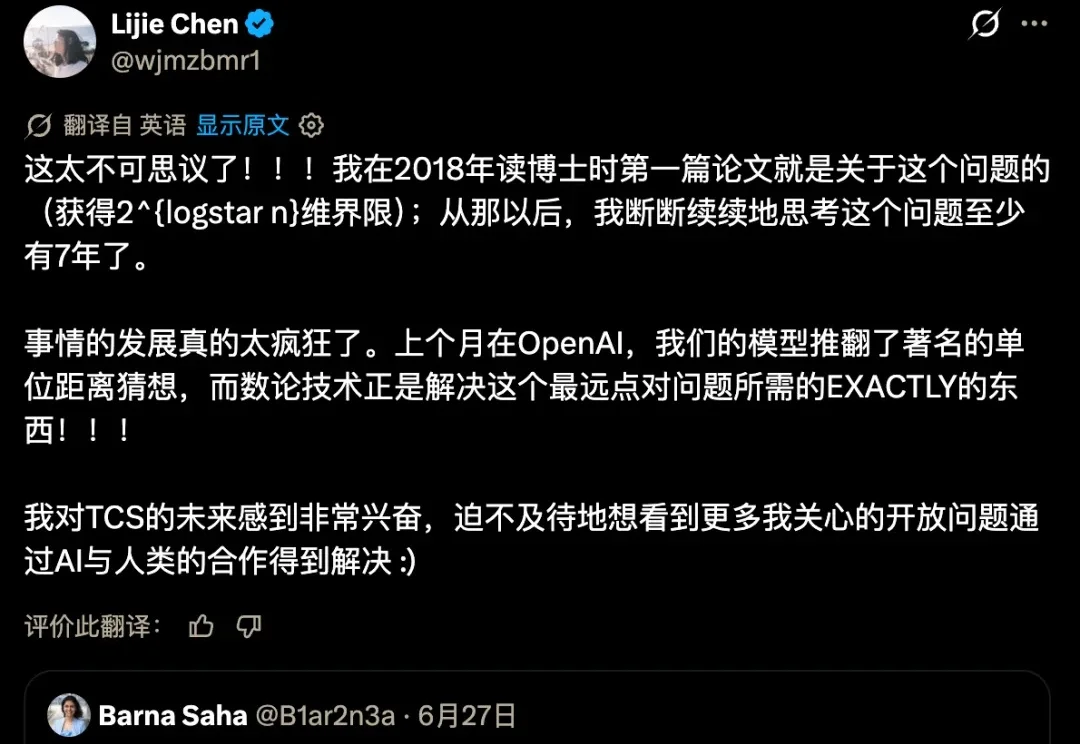
GPT-5.5 Pro 生成了一个数学证明,解决了计算几何中一个 陈立杰苦思 7 年未解的核心难题。关键技术来自 OpenAI 上月的另一项突破,而最初推进这个问题的陈立杰发现,钥匙竟是自己参与的工作。

就在外界惊呼“AI快要接管纯数学研究”之际,一场限制条件极其严格、并由30位数学家以匿名方式进行评审的数学测试,却揭开了AI数学能力的另一面:AI不仅会幻觉、会跳步骤,甚至还把数学家论文里的关键论证几乎原样照搬,却忘了注明引用。

被一道数学竞赛题卡住很久时,高手往往能准确地判断:现在缺的是一个技术细节,还是整个思路从一开始就走错了?

数学界的“最强大脑”,快被AI出的证明淹没了。

陶哲轩又发成绩单了。

自今年2月以来,AxiomProver已让8篇覆盖最硬核领域的AI论文现身arXiv,6篇正在筹备。上午出题下午交卷的节奏,让博士生秃头、教授评职称的日子一去不复返。接下来AI能做到什么?

一道悬了12年没人证出来的物理猜想,诺贝尔物理学奖得主Giorgio Parisi把它交给了Claude,模型几乎自己推出了完整证明。