
跨越落地鸿沟!清华长三院发布首个真实场景AI竞技场,实战谁是最佳?
跨越落地鸿沟!清华长三院发布首个真实场景AI竞技场,实战谁是最佳?攻克AI落地难题,清华团队推出RWAI框架与真实场景竞技场,通过标准化人机交互、任务集机制与人类反馈体系,显著提升产业应用效率。平台已实现落地周期缩短70%以上,并为AI开发者和企业提供了可复制的最佳实践。
来自主题: AI技术研报
6604 点击 2026-05-20 09:52
 搜索
搜索
攻克AI落地难题,清华团队推出RWAI框架与真实场景竞技场,通过标准化人机交互、任务集机制与人类反馈体系,显著提升产业应用效率。平台已实现落地周期缩短70%以上,并为AI开发者和企业提供了可复制的最佳实践。

数学界尘封32年的拉姆齐数经典难题被打破!浙大校友王宜平借助自研AI框架ScaleAutoResearch-Ramsey,成功将拉姆齐数R(3,17) 下界从92提升至93,终结了自1994年以来长期停滞的纪录。
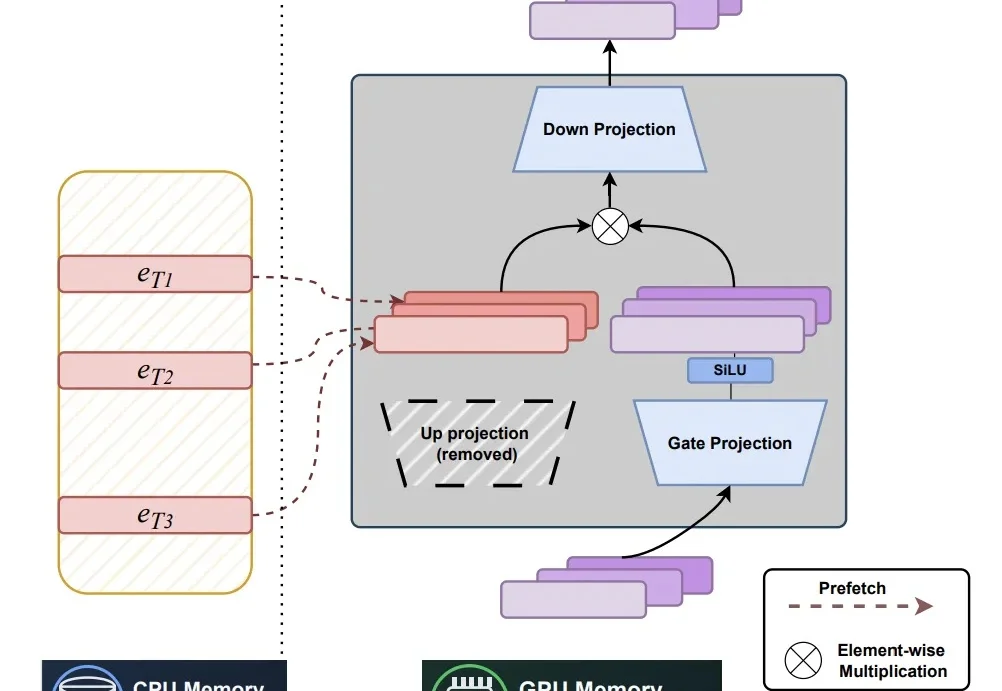
近年来,随着大语言模型规模与知识密度不断提升,研究者开始重新思考一个更本质的问题:模型中的参数应如何被组织,才能更高效地充当「记忆」。
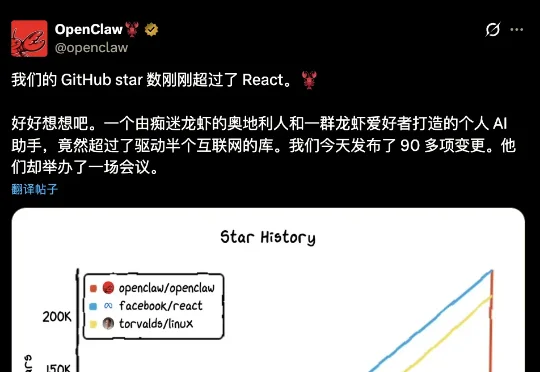
仅用两月,本地AI框架OpenClaw击败Linux,登顶GitHub星标榜!本文回顾了OpenClaw爆火之路,及其背后反映的开源社区趋势变化。
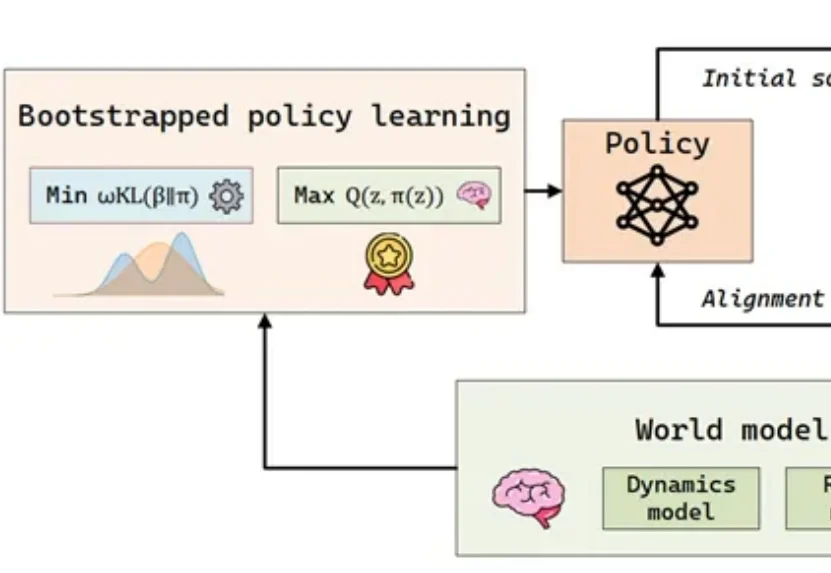
在具身智能(Embodied AI)的快速发展中,样本效率已成为制约智能体从实验室环境走向复杂开放世界的瓶颈问题。
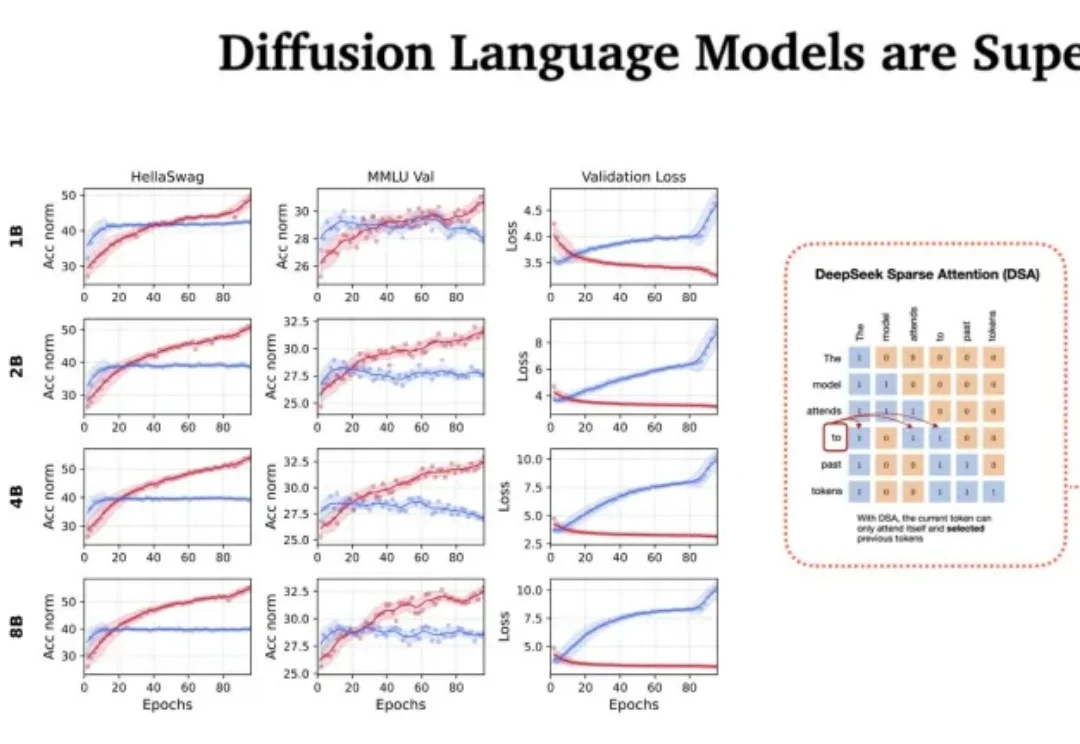
站在 2026 年的开端回望,LLM 的架构之争似乎进入了一个新的微妙阶段。过去几年,Transformer 架构以绝对的统治力横扫了人工智能领域,但随着算力成本的博弈和对推理效率的极致追求,挑战者们从未停止过脚步。
今天,首个在国产芯片上完成全程训练的SOTA(最佳水平)多模态模型开源。这是智谱联合华为开源的图像生成模型GLM-Image。从数据到训练的全流程,该模型完全基于昇腾Atlas 800T A2设备和昇思MindSpore AI框架完成构建。

清华大学等多所高校联合发布SR-LLM,这是一种融合大语言模型与深度强化学习的符号回归框架。它通过检索增强和语义推理,从数据中生成简洁、可解释的数学模型,显著优于现有方法。在跟车行为建模等任务中,SR-LLM不仅复现经典模型,还发现更优新模型,为机器自主科学发现开辟新路径。

近日,范鹤鹤(浙江大学)、杨易(浙江大学)、Mohan Kankanhalli(新加坡国立大学)和吴飞(浙江大学)四位老师提出了一种具有划时代意义的神经网络基础操作——Translution。 该研究认为,神经网络对某种类型数据建模的本质是:
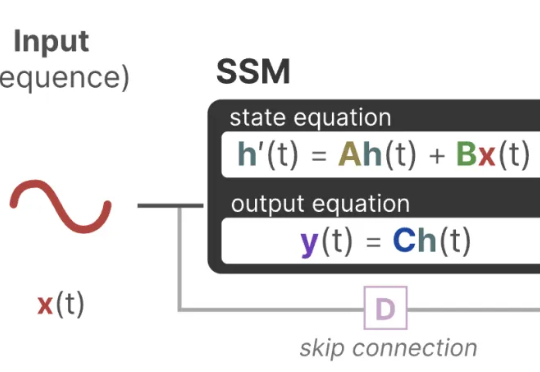
曼巴回来了!Transformer框架最有力挑战者之一Mamba的最新进化版本Mamba-3来了,已进入ICLR 2026盲审环节,超长文本处理和低延时是其相对Transformer的显著优势。另一个挑战者是FBAM,从不同的角度探索Transformer的下一代框架。