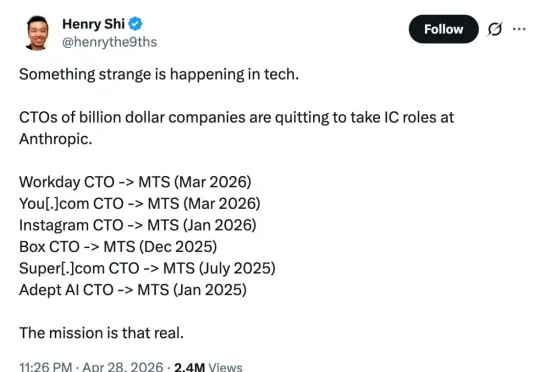
CTO不香了?百亿公司高管们为何集体转身,去Anthropic当工程师
CTO不香了?百亿公司高管们为何集体转身,去Anthropic当工程师事情是这样的,前两天,一位博主 Henry Shi 在 X 上发文称,自己看到科技界正在发生奇怪的事情,「一些曾经管理着数十亿美元公司业务的 CTO,纷纷离职,转而加入 Anthropic,去做一名个人贡献者 (IC, Individual Contributor)。」
来自主题: AI资讯
7560 点击 2026-05-04 10:18
 搜索
搜索
事情是这样的,前两天,一位博主 Henry Shi 在 X 上发文称,自己看到科技界正在发生奇怪的事情,「一些曾经管理着数十亿美元公司业务的 CTO,纷纷离职,转而加入 Anthropic,去做一名个人贡献者 (IC, Individual Contributor)。」
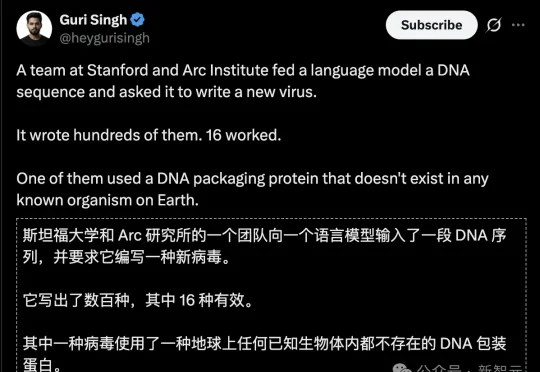
AI创造生命的一大步!斯坦福团队用AI造出从零写出16种噬菌体,内含地球前所未有的蛋白,Anthropic CEO预警:6到12个月,傻子也能造超级病毒。

Anthropic 的工程师们写了篇技术博客,标题是:构建 Claude Code 的经验教训:Prompt Caching 就是一切。Anthropic 内部把 Prompt Cache 的命中率当作基础设施级别的指标来监控,地位跟服务器 uptime 差不多。一旦命中率下降,就会触发 oncall 告警,工程师得像处理线上事故一样去排查。

昆仑万维在年报中宣告,公司正全面All in AGI与AIGC,并在2026年将战略升级为"4+3",即以视频、音乐音频、世界、基座文本四大SOTA模型为底座,支撑AI短剧、AI音乐、AI游戏三大平台。
近日,AI编程智能体初创公司 Factory 完成1.5亿美元C轮融资,投后估值达到15亿美元,正式跻身独角兽行列。本轮由Khosla Ventures领投,Sequoia Capital、Blackstone、Insight Partners、Evantic Capital、20VC、NEA和Mantis VC参与跟投。

可能还有些人记得,去年年底的时候,Anthropic 在自家办公室搞了一个自动售货项目,「主理人」是 Claude——哦不,主理机。当时是让 Claude Sonnet 3.7 在办公室里经营一台自动售货机,管进货、定价、跟同事聊天推销,干了大概一个月。结果

ElatoAI 是一个开源免费的实时AI语音交互系统,采用Arduino 编程,运行在乐鑫 ESP32 主控制器上,通过安全WebSocket连接至部署在Deno边缘函数构建的服务端,通过OpenAI Realtime API等技术实现低成本、长时长、跨设备的自然对话体验,支持多种AI模型,

谷歌母公司Alphabet营收达到1099亿美元,每股收益5.11美元,远超华尔街预期的2.62美元;亚马逊净销售额1815亿美元,净利润303亿美元,每股收益2.78美元,几乎是预期的两倍;微软营收829亿美元,同比增长18%;Meta净利润268亿美元,同比接近翻倍。

嗨大家好!我是阿真! 朋友们,好像标题党了,先别骂,看完指定有灵感。整了点不错的东西,这次真的可以把 PPT 做得很好看了!快放假之前给大家再分享一波,这个真的很棒的不容错过。 首先我其实是很早就想做
刚刚,Anthropic 公布了 Claude Code 比赛的六组获奖作品。这是 Claude 和 Cerebral Valley 联合办的一场黑客松,规则是:用 Opus 4.7 + Claude Code,一周时间,做个东西出来。