
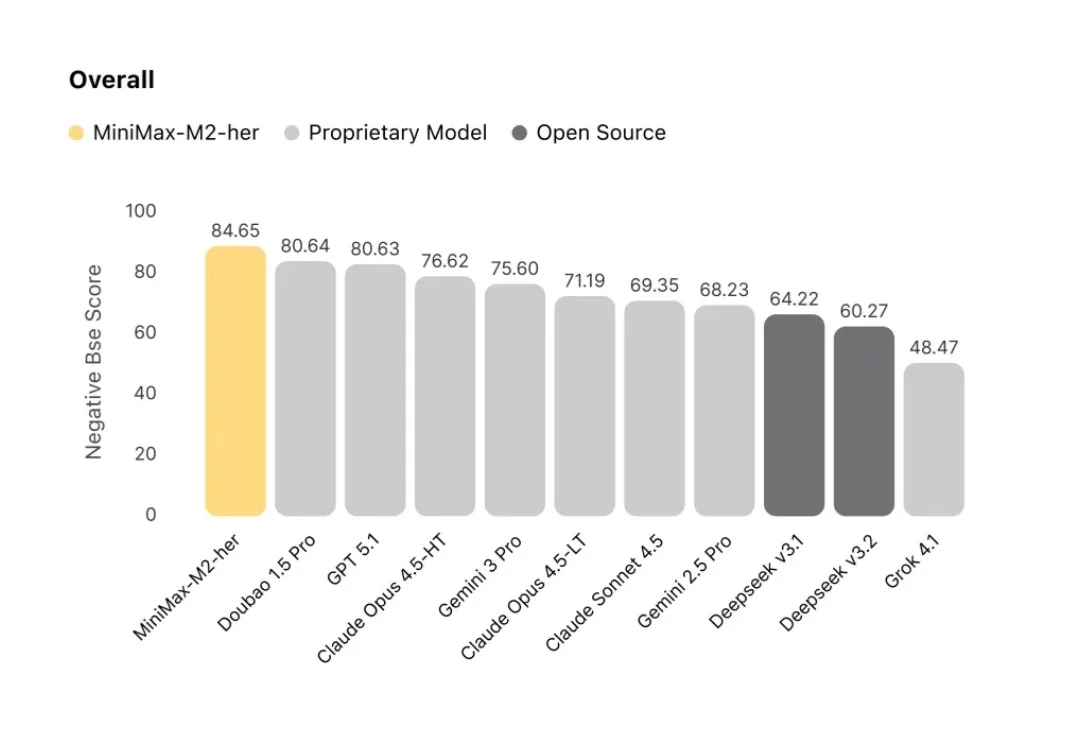
MiniMax M2-her:我们做出了更懂你的 AI
MiniMax M2-her:我们做出了更懂你的 AI今天,我们分享 MiniMax-M2-her 背后的技术思考。M2-her 也是服务星野/Talkie的底层模型。
来自主题: AI技术研报
8318 点击 2026-02-02 13:25
今天,我们分享 MiniMax-M2-her 背后的技术思考。M2-her 也是服务星野/Talkie的底层模型。
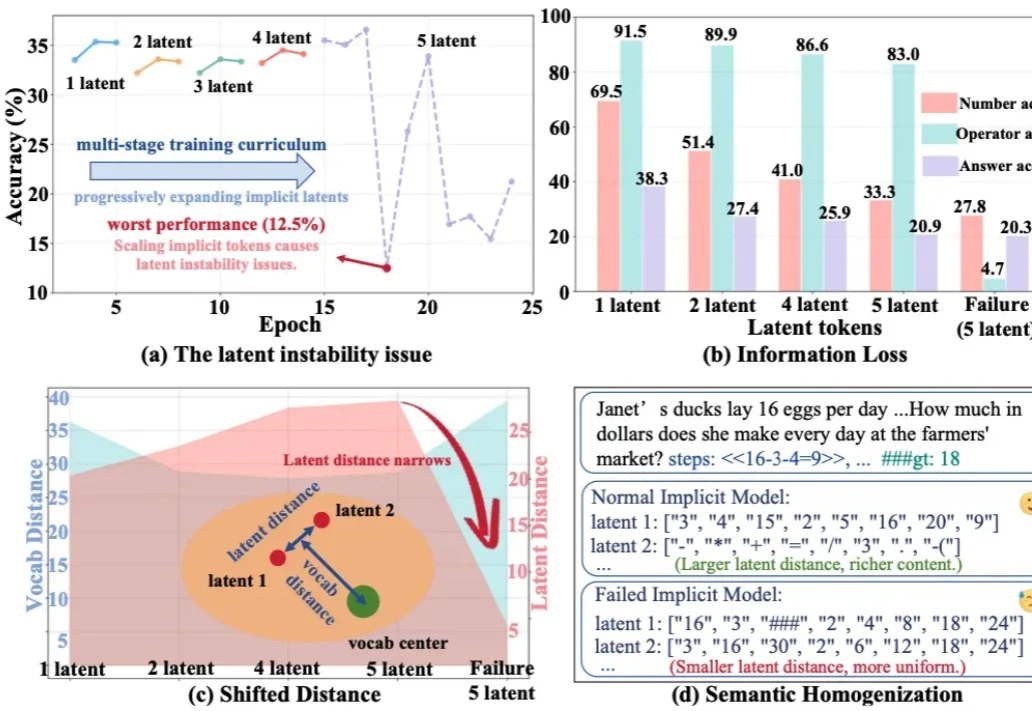
今天推荐一个 Implicit Chain-of-Thought(隐式推理) 的最新进展 —— SIM-CoT(Supervised Implicit Chain-of-Thought)。它直击隐式 CoT 一直「扶不起来」的核心痛点:隐式 token 一旦 scale 上去,训练就容易塌缩到同质化的 latent 状态,推理语义直接丢失。

最近硅谷的一个本地Agent项目也很有关注度,而且是软硬件打包好,买回来就能直接用的那种。长这样子,卖250美元(折合人民币约1700元),买来插上电就能当OpenClaw用。
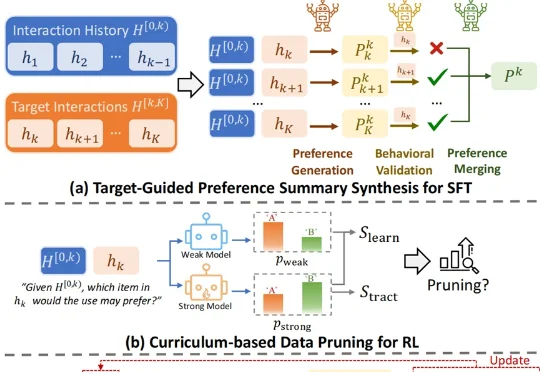
怎样做一个爆款大模型应用?这恐怕是2026年AI开发者们都在关注的问题。当算力和性能不再是唯一的护城河,“爆款”意味着大模型要能精准地“抓住”每一名具体的用户,而个性化正是其中的关键技术之一。
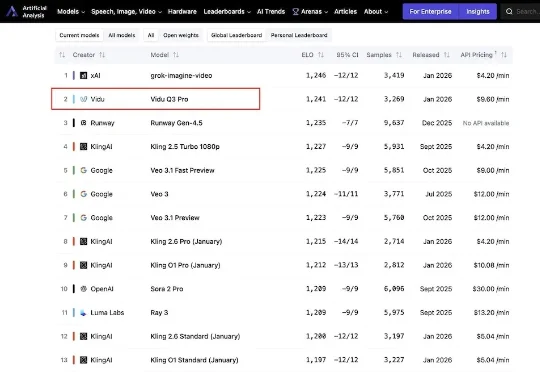
今日,来自生数科技的AI视频模型Vidu Q3 Pro登上国际权威AI基准平台Artificial Analysis榜单,位列中国第一,全球第二。这是最新榜单内,首个打入国际第一梯队的国产视频生成模型。

Google DeepMind 已于本月初向员工宣布了 Silver 的离职消息。Silver 在离职前的几个月里一直处于休假状态,并未正式返回 DeepMind 工作岗位。Google DeepMind 的一位发言人在电子邮件声明中证实了 Silver 离职的信息,表示:「Dave 的贡献是无价的,我们非常感谢他对 Google DeepMind 工作所做出的贡献。」

周伯文还详细介绍了上海 AI 实验室近年来开展的前沿探索与实践,包括驱动 “通专融合” 发展的技术架构 ——“智者”SAGE(Synergistic Architecture for Generalizable Experts),其包含基础、融合与进化三个层次,并可双向循环实现全栈进化;支撑 AGI4S 探索的两大基础设施“书生”科学多模态大模型 Intern-S1、“
离开Meta这座围城后,Yann LeCun似乎悟了“不要把鸡蛋装在同一个篮子里”。一边,他亲手打造了自己的初创公司AMI,试图在世界模型这条赛道上大展拳脚;同时,他的目光又投向了硅谷的另一角。
机器人领域是我们长期关注的赛道,而 Generalist 是当前机器人领域中极少数具备长期竞争潜力的公司,核心优势集中在数据规模、团队能力与清晰的 scaling 路径上。

当 2003 年人类基因组测序首次完成时,我们获得了一本厚达 30 亿个遗传字母的“天书”,却发现自己只能读懂其中 2% 的“文字”(编码区),剩下的 98% 被称为基因组的“暗物质”。