继Lovable之后,硅谷顶级VC用1500万美金投了印度的一个Vibe coding产品
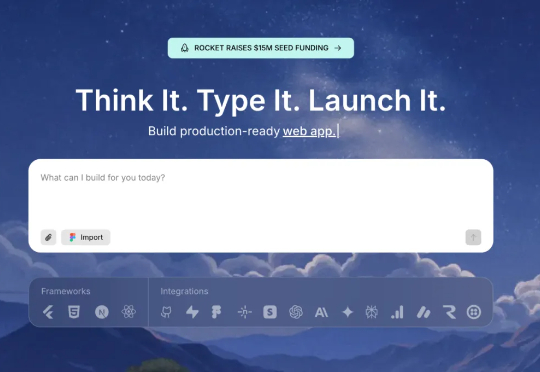
继Lovable之后,硅谷顶级VC用1500万美金投了印度的一个Vibe coding产品一家来自印度苏拉特的创业公司 Rocket.new 却声称他们解决了这个问题。不仅如此,他们还刚刚完成了1500万美元的种子轮融资,由Salesforce Ventures和Accel联合领投,Together Fund跟投。更令人惊讶的是,这家公司从beta版上线到完成融资仅用了3个月时间,目前已经拥有40万用户,分布在180个国家,年收入达到450万美元。
来自主题: AI资讯
9421 点击 2025-09-30 11:05