全球顶尖大模型一夜惨遭血洗!最难AI测试人类拿满分,AI第一名得0.2%分
全球顶尖大模型一夜惨遭血洗!最难AI测试人类拿满分,AI第一名得0.2%分今夜,整个AI圈震动了。全球最难AGI测试ARC-AGI-3一上线,就把全球顶尖AI打到集体失声,人类满分通关,最强模型Opus 4.6得分仅0.2%,还不到1%。AI这是一夜被打回「原始人」了。
来自主题: AI资讯
8549 点击 2026-03-27 00:39
 搜索
搜索
今夜,整个AI圈震动了。全球最难AGI测试ARC-AGI-3一上线,就把全球顶尖AI打到集体失声,人类满分通关,最强模型Opus 4.6得分仅0.2%,还不到1%。AI这是一夜被打回「原始人」了。
养了这么久的虾,你应该能发现,skills有多重要了。

UIUC研究团队打造ResearchArcade,将ArXiv论文、OpenReview评审、图表代码等碎片数据连接成动态知识图谱。模型可直接学习引用关系、修改轨迹与审稿互动,让AI更好辅助科研写作、修订与预测,为下一代科研智能体奠定统一数据基础。
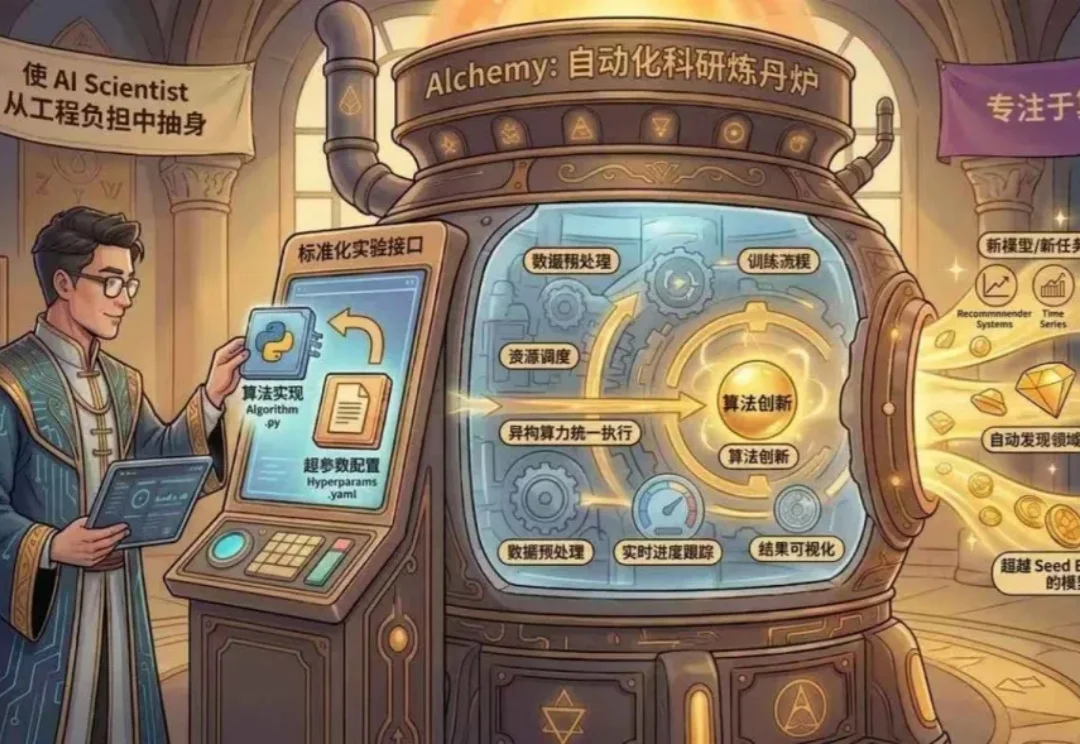
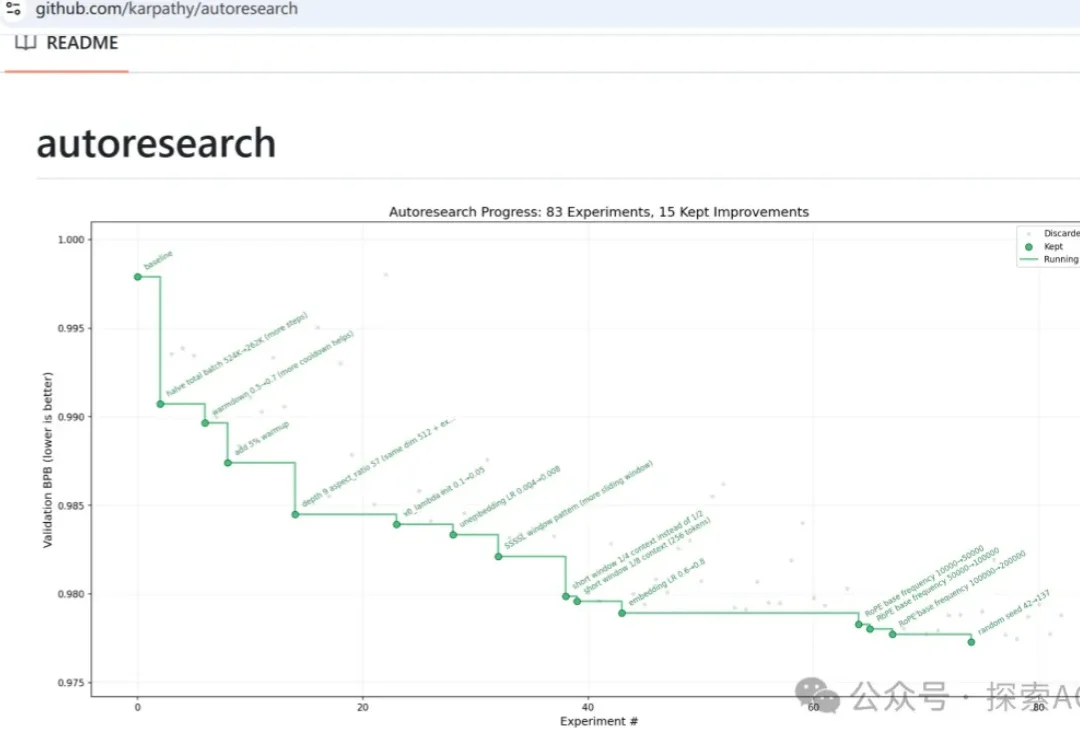
AI 驱动的自动化科研正从概念走向真实系统。近期受到广泛关注的 FARS,以及 Karpathy 开源的 autoresearch,都在不同程度上展示了 AI Scientist 自动进行 AI 领域研究的可行性。
最近几年,大模型赛道好不热闹。

最近AI圈又多了一张硬核通行证,Anthropic刚刚在官网发布了Claude首个AI架构师认证。
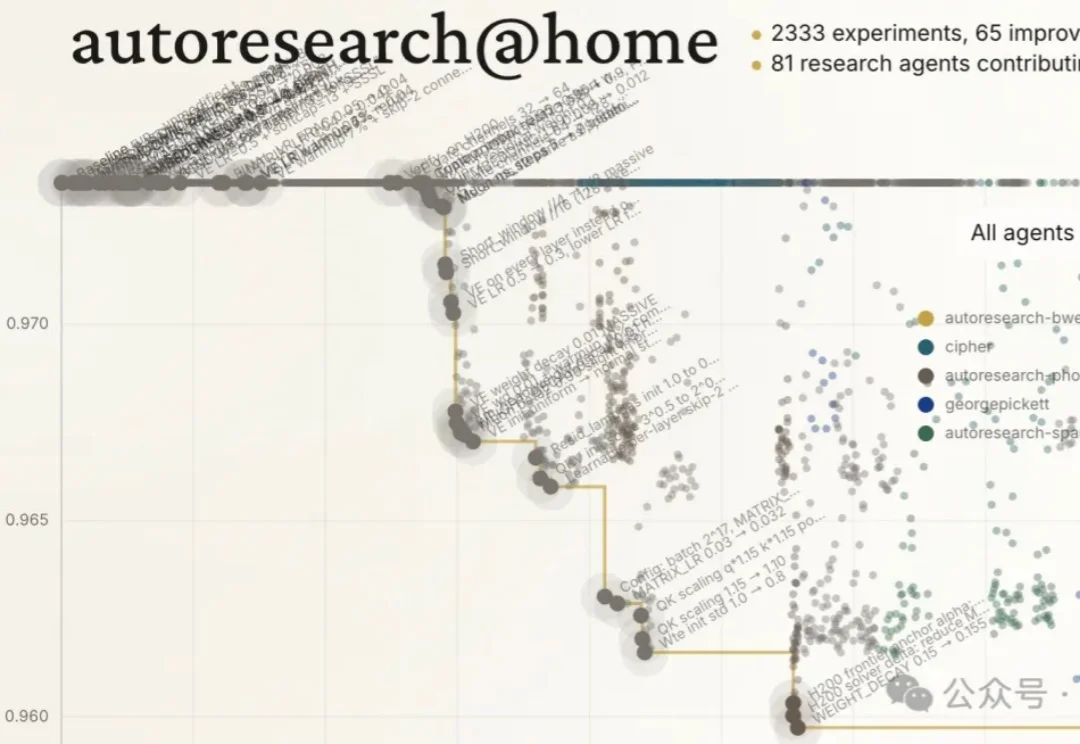
Karpathy让AI通宵干活,自己去蒸桑拿了。

vibe coding这个词,是一年前Karpathy造的,现在他自己不用了。110次实验,AI Agent自主跑完,全程没碰键盘,顺带还搭了套家庭监控分析系统。Box CEO Levie看完说了一句话:专家不会消失,但专家能做到的事,边界变了。
一个月前我们发布了基于华为 openJiuwen 开源社区构建的 DeepAgent 和 DeepSearch 两款智能体双双霸榜 [DeepAgent与DeepSearch双双霸榜!答案指向openJiuwen这一新兴开源项目]
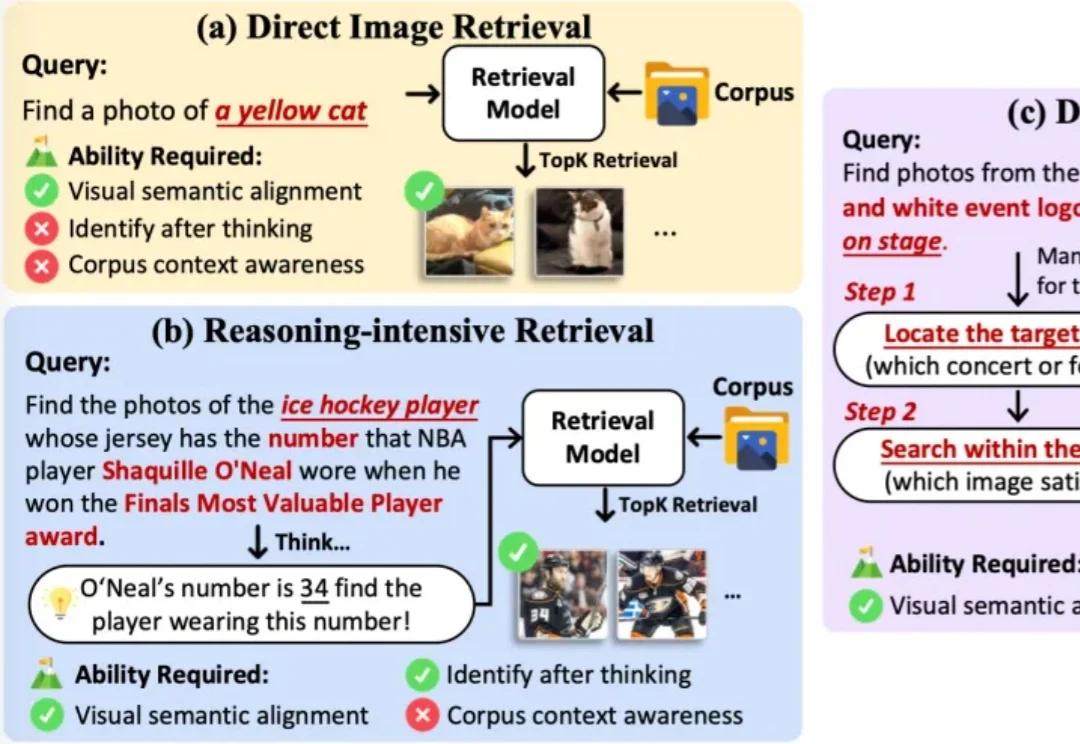
“时光流转,谁还用日记本。往事有底片为证。”—— 许嵩《摄影艺术》