4比特量化三倍加速不掉点!清华即插即用的SageAttention迎来升级
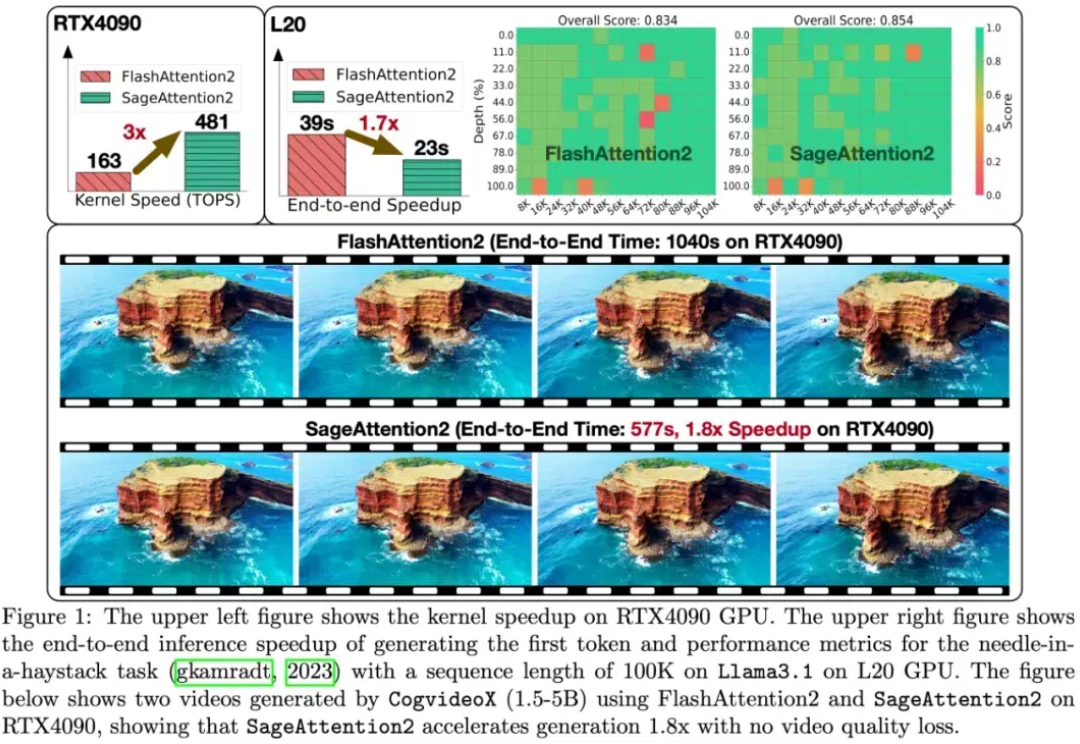
4比特量化三倍加速不掉点!清华即插即用的SageAttention迎来升级大模型中,线性层的低比特量化已经逐步落地。然而,对于注意力模块,目前几乎各个模型都还在用高精度(例如 FP16 或 FP32)的注意力运算进行训练和推理。并且,随着大型模型需要处理的序列长度不断增加,Attention(注意力运算)的时间开销逐渐成为主要开销。
来自主题: AI技术研报
9607 点击 2024-12-27 09:44