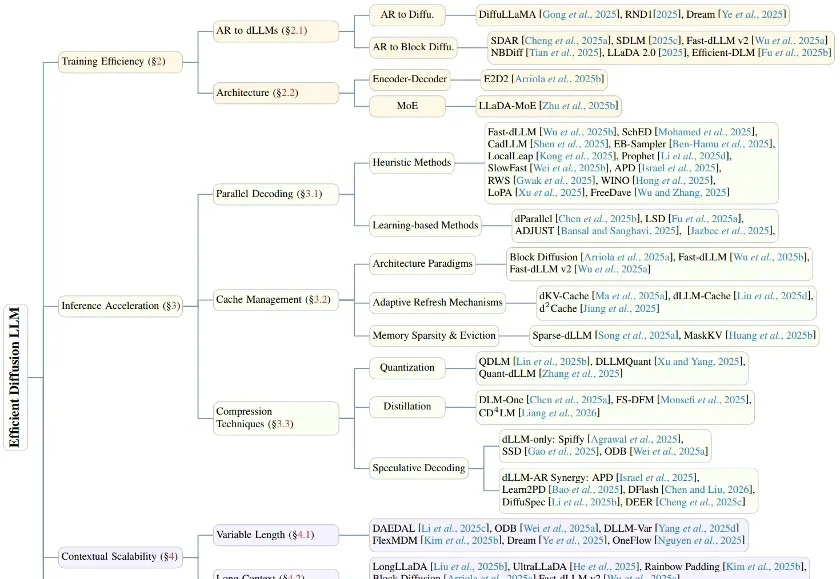
从训练到推理的「瘦身」演进:首篇高效扩散语言模型(dLLM)深度综述
从训练到推理的「瘦身」演进:首篇高效扩散语言模型(dLLM)深度综述在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。
来自主题: AI技术研报
6853 点击 2026-03-10 14:29
 搜索
搜索
在生成式 AI 的浪潮中,自回归(Autoregressive, AR)模型凭借其卓越的性能占据了统治地位。然而,其「从左到右」逐个预测 Token 的串行机制,天生限制了并行生成的可能性。

谁能想到啊,在自回归模型(Autoregressive,AR)当道的现在,一个非主流架构的模型突然杀了回马枪——被长期视为学术玩具的扩散语言模型,直接在复杂编程任务中飙出了892 tokens/秒的速度!
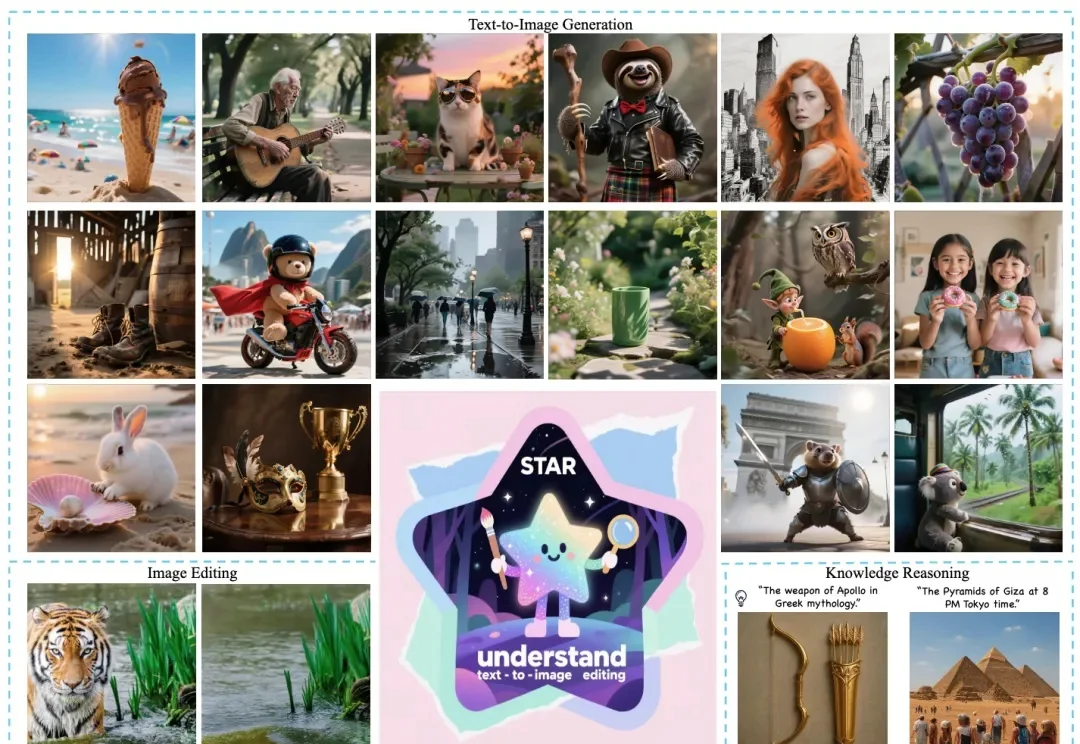
近日,美团推出全新多模态统一大模型方案 STAR(STacked AutoRegressive Scheme for Unified Multimodal Learning),凭借创新的 "堆叠自回归架构 + 任务递进训练" 双核心设计,实现了 "理解能力不打折、生成能力达顶尖" 的双重突破。

近日,上海人工智能实验室针对该难题提出全新范式 SDAR (Synergistic Diffusion-AutoRegression)。该方法通过「训练-推理解耦」的巧妙设计,无缝融合了 AR 模型的高性能与扩散模型的并行推理优势,能以极低成本将任意 AR 模型「改造」为并行解码模型。

扩散语言模型(Diffusion Language Models,DLM)一直以来都令研究者颇感兴趣,因为与必须按从左到右顺序生成的自回归模型(Autoregressive, AR)不同,DLM 能实现并行生成,这在理论上可以实现更快的生成速度,也能让模型基于前后文更好地理解生成语境。
近年来,扩散大语言模型(Diffusion Large Language Models, dLLMs)正迅速崭露头角,成为文本生成领域的一股新势力。与传统自回归(Autoregressive, AR)模型从左到右逐字生成不同,dLLM 依托迭代去噪的生成机制,不仅能够一次性生成多个 token,还能在对话、推理、创作等任务中展现出独特的优势。

在图像生成领域,自回归(Autoregressive, AR)模型与扩散(Diffusion)模型之间的技术路线之争始终未曾停歇。大语言模型(LLM)凭借其基于「预测下一个词元」的优雅范式,已在文本生成领域奠定了不可撼动的地位。
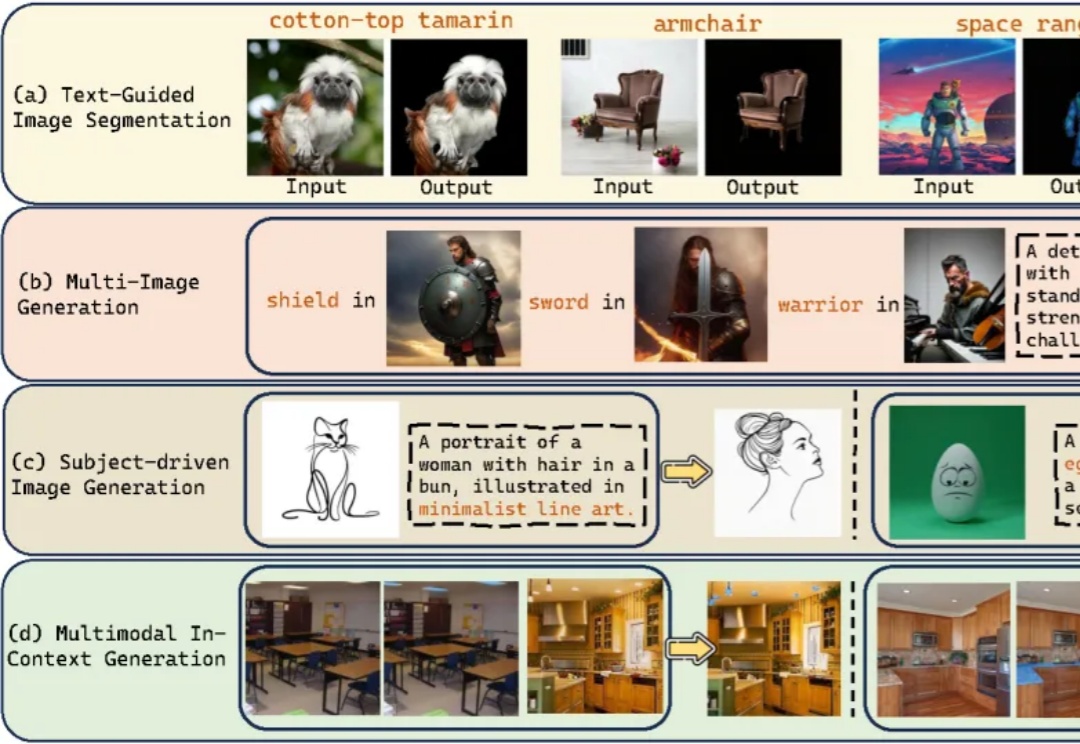
当下的AI图像生成领域,Diffusion模型无疑是绝对的王者,但在精准控制上却常常“心有余而力不足”。
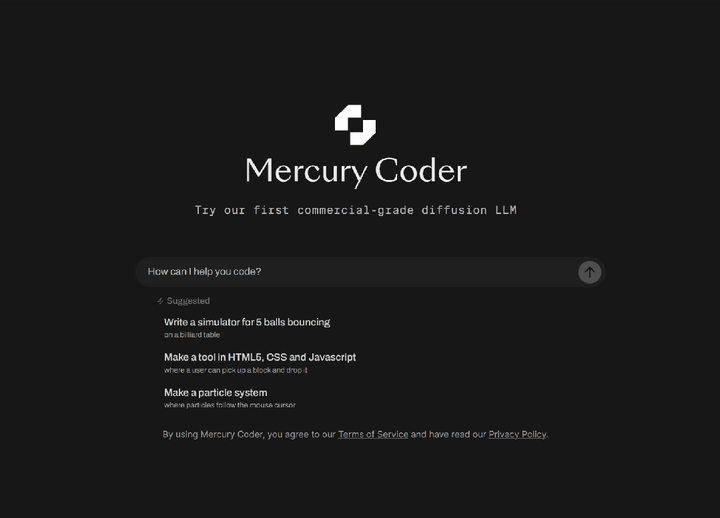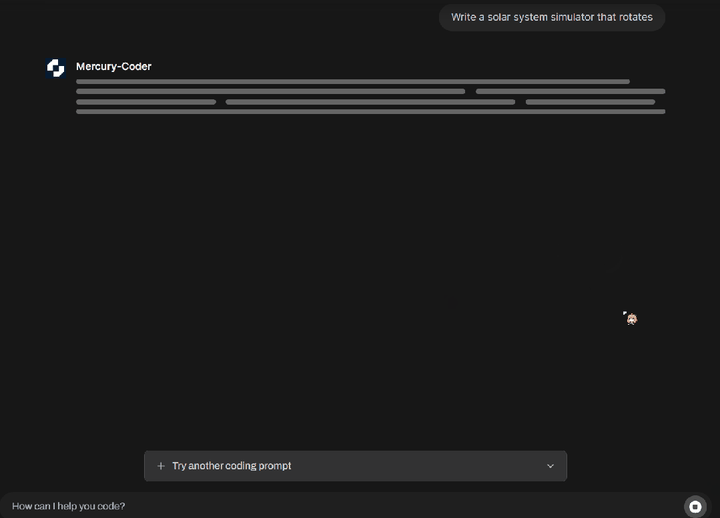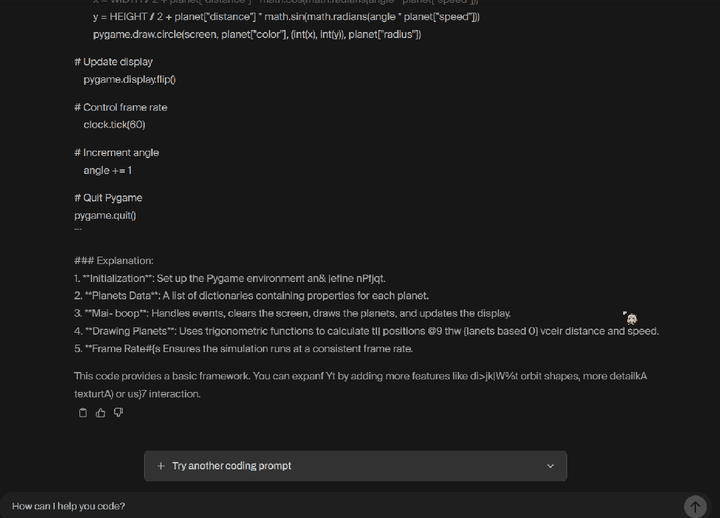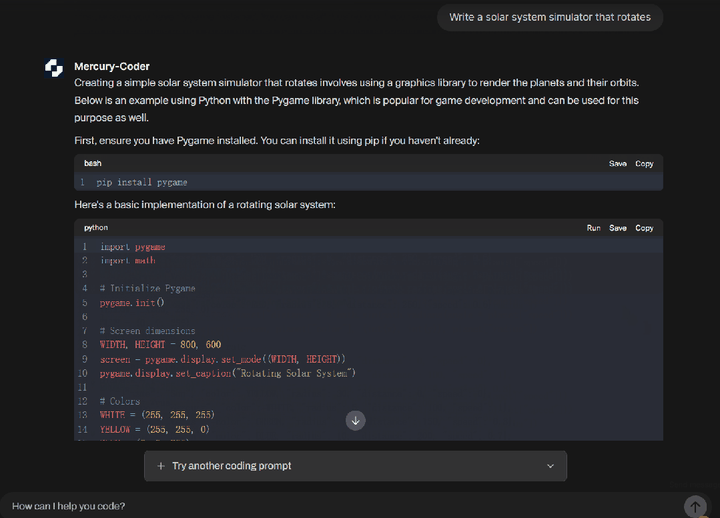
2025年2月27日,由前扩散模型领域顶尖研究者创立的Inception Labs正式发布了全球首个商业级扩散大语言模型(dLLM)——“Mercury”。这一里程碑式产品不仅在生成速度、硬件效率和成本控制上实现突破,更标志着自然语言处理技术从自回归(Autoregressive)范式向扩散(Diffusion)范式的重大跃迁。
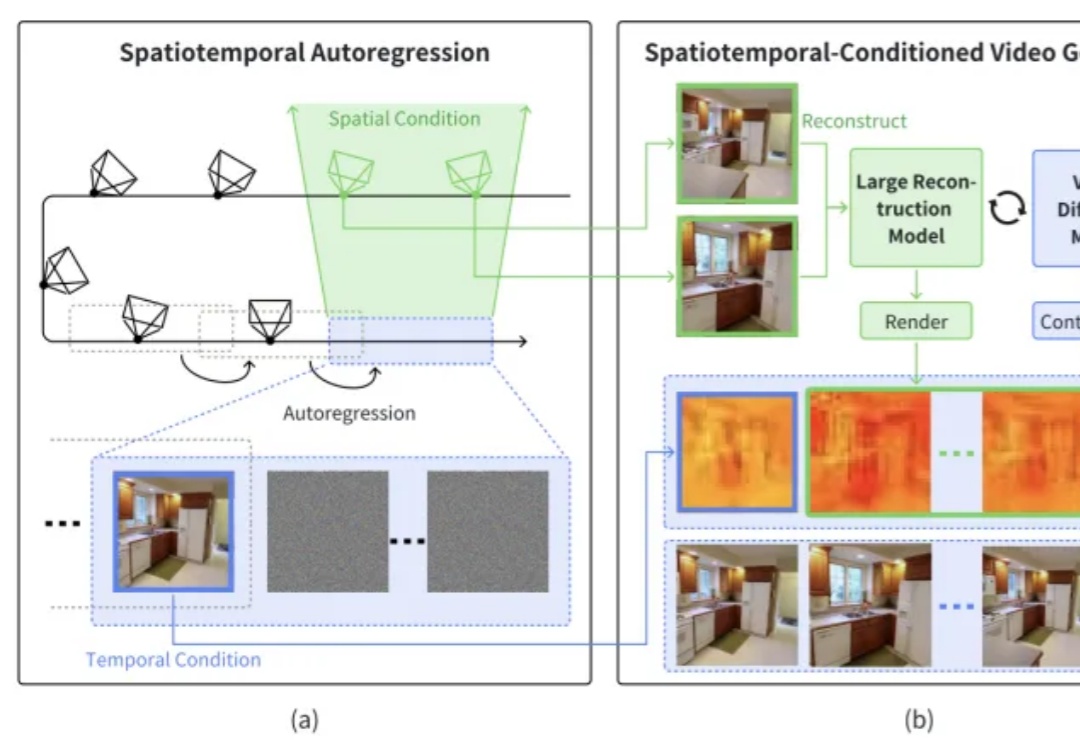
本文介绍了一篇由浙江大学章国锋教授和商汤科技研究团队联合撰写的论文《StarGen: A Spatiotemporal Autoregression Framework with Video Diffusion Model for Scalable and Controllable Scene Generation》。