GPT-5.5翻倍,Gemini涨3倍:这波涨价游戏还能玩多久?
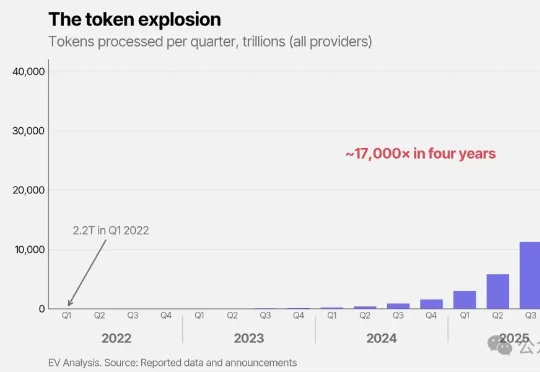
GPT-5.5翻倍,Gemini涨3倍:这波涨价游戏还能玩多久?Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。
来自主题: AI技术研报
8737 点击 2026-05-28 20:59
 搜索
搜索
Epoch AI刚刚发布的《梯度更新》报告,做了一件简单粗暴的事:把全球所有Blackwell芯片能处理的Token数量算出来,再和实际需求一比。结论只有一个字——不够。
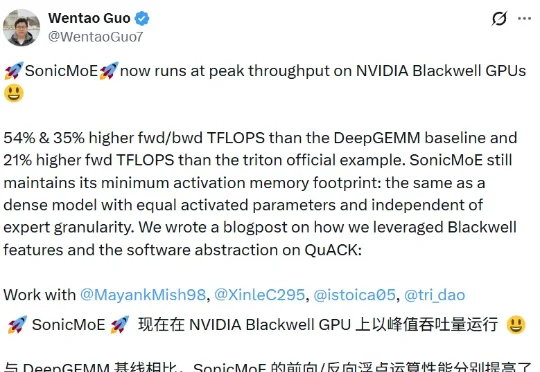
近日,由普林斯顿大学 Tri Dao(FlashAttention 的一作)和加州大学伯克利分校 Ion Stoica 领导的一个联合研究团队也做出了一个超快的索尼克:SonicMoE。据介绍,SonicMoE 能在英伟达 Blackwell GPU 上以峰值吞吐量运行!并且运算性能超过了 DeepSeek 之前开源并引发巨大轰动的 DeepGEMM。

MoE模型的稀疏激活本是优势,却常陷通信瓶颈。NVIDIA以软件为利剑,通过程序化依赖启动和全对全通信革新,在三个月内将GB200的单GPU吞吐提升2.8倍,真正释放Blackwell硬件潜力。
全球AI终局战,牌桌上只剩OpenAI和Anthropic了!现在,两家已经开启了指数级双雄争霸,GPT-5.5救了老黄,Blackwell重锤反击。面对30GW的算力对决和步骤坍塌,谁能拿稳AGI的头等舱门票?

Cognichip正在构建一个深度学习模型,以便在工程师设计新计算机芯片的过程中为其提供协助。它试图解决的问题是该行业数十年来一直面临的一个难题:芯片设计极其复杂、成本高昂且速度缓慢。先进的芯片从概念设计到大规模生产需要三到五年的时间;仅设计阶段就可能长达两年。想想看,英伟达最新的 GPU 系列Blackwell就包含1040 亿个晶体管——要排列这么多晶体管可不是一件容易的事。

今天早上,Cursor 在X上发布一条推文:“我们重建了 MoE 模型在 Blackwell GPU 上生成 Tokens 的方式,导致推理速度快了 1.84 倍。”
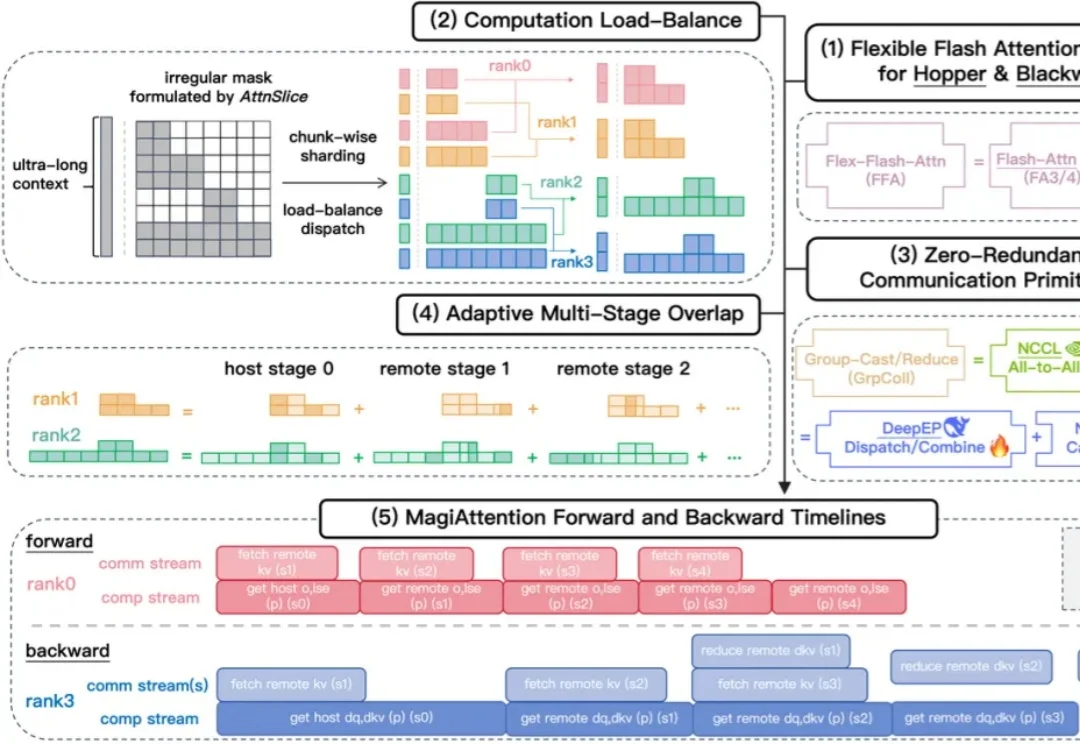
2025 年 4 月,Sand.ai 开源了 MagiAttention v1.0.0,定义了下一代分布式 Attention 的全新设计和系统框架。历经一年的深耕,今天 Sand.ai 正式发布:MagiAttention v1.1.0,以更成熟的原生算子组件,重新定义 Hopper 与 Blackwell 两代架构分布式 Attention 的性能上限。

所有用英伟达Blackwell B200的人,都在花冤枉钱??

近日,深度学习领域重要底层优化技术 FlashAttention 迎来大版本更新。FlashAttention 核心作者、普林斯顿大学助理教授 Tri Dao 表示,在 Blackwell GPU 上,即使瓶颈截然不同,注意力机制的执行速度现在也几乎与矩阵乘法一样快了!

英伟达H200终于获批了!美国以「代差优势」为前提,放行上一代旗舰芯片,并顺手抽走25%「回扣」。其性能是H20的6倍,却仍落后于最新Blackwell架构。