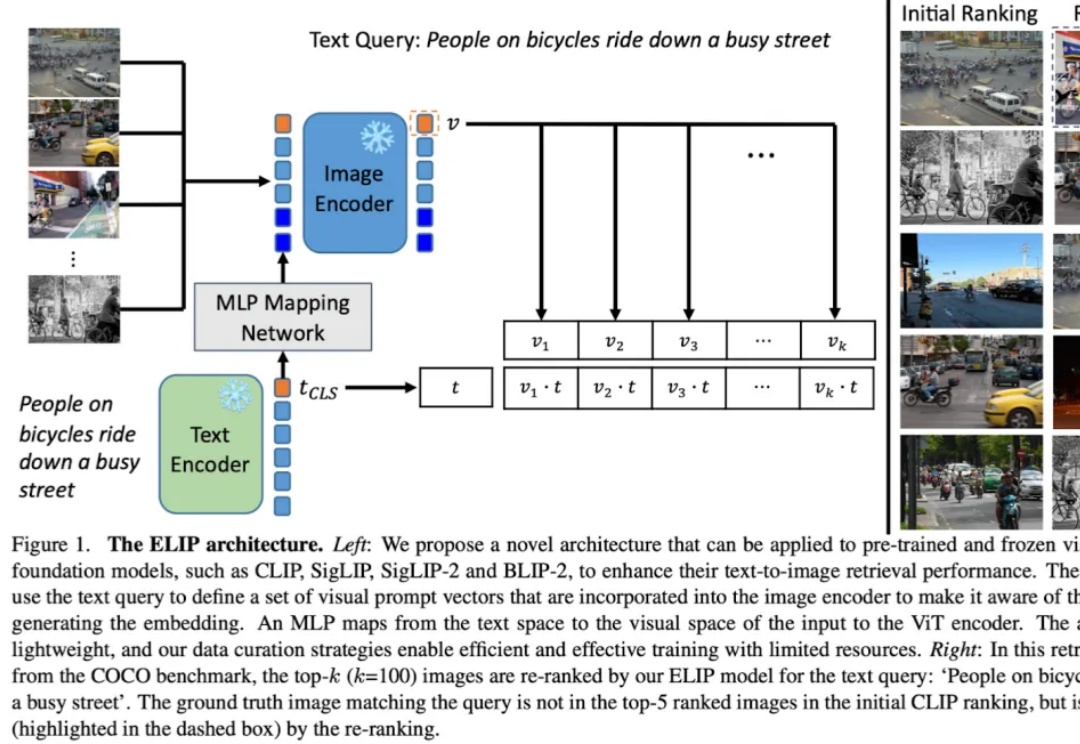
知名开源大佬爆料:OpenAI也在悄悄用Skills!ChatGPT、Codex CLI 惊现skills目录
知名开源大佬爆料:OpenAI也在悄悄用Skills!ChatGPT、Codex CLI 惊现skills目录还在争论Skills是不是prompt?已经可以停下火了。因为,刚刚得到的消息消息,OpenAI已经悄悄地用上了Skills了。今天,知名博主、Django Web 框架联合创始人Simon Willson爆料:
来自主题: AI资讯
9691 点击 2025-12-14 10:53