
ICCV 2025放榜!录取率24%,夏威夷门票你抢到了吗?
ICCV 2025放榜!录取率24%,夏威夷门票你抢到了吗?ICCV 2025 将于 10 月 19 日至 25 日在美国夏威夷举行。刚刚,ICCV 官方向投稿者发送了今年论文接收结果的通知。
来自主题: AI资讯
12370 点击 2025-06-26 15:30
 搜索
搜索
ICCV 2025 将于 10 月 19 日至 25 日在美国夏威夷举行。刚刚,ICCV 官方向投稿者发送了今年论文接收结果的通知。
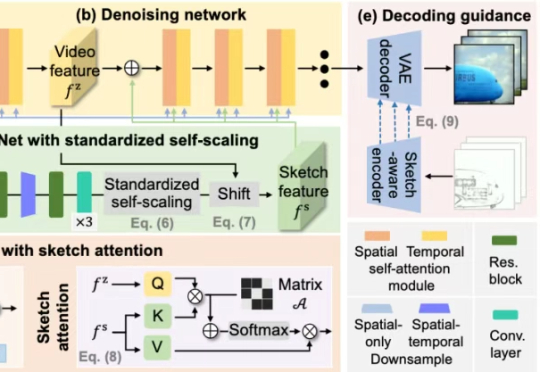
视频是信息密度最高、情感表达最丰富的媒介之一,高度还原现实的复杂性与细节。
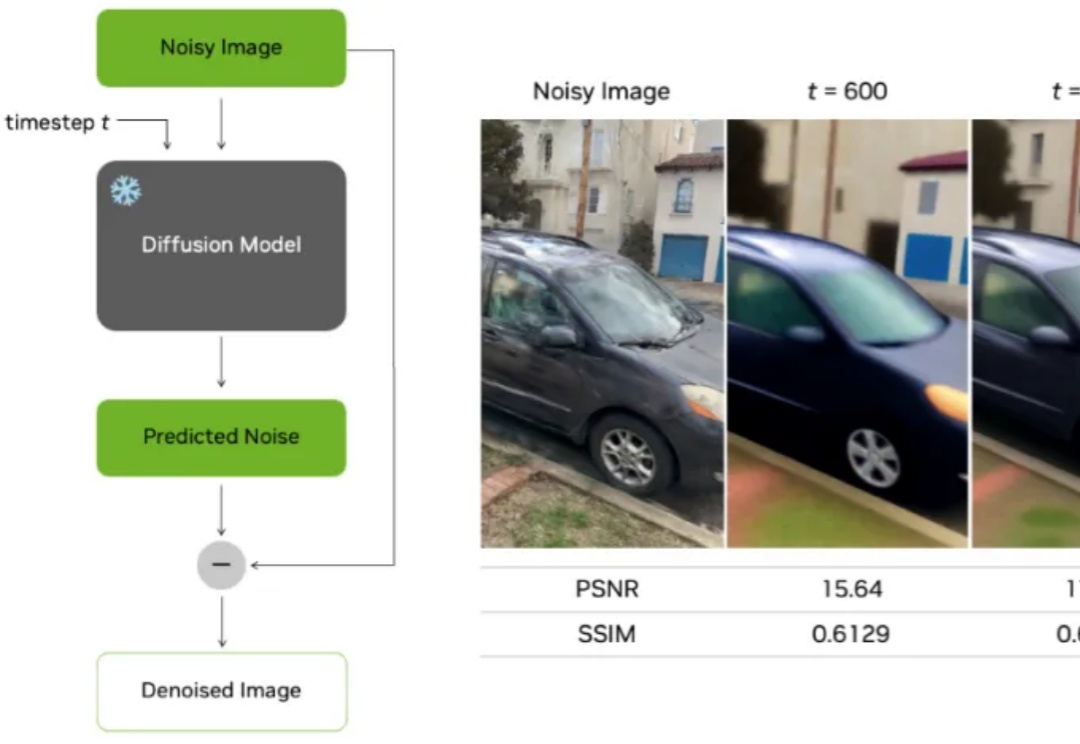
在 3D 重建领域,无论是 NeRF 还是最新的 3D Gaussian Splatting(3DGS),在生成逼真新视角时仍面临一个核心难题:视角一旦偏离训练相机位置,图像就容易出现模糊、鬼影、几何错乱等伪影,严重影响实际应用。
生成模型会重现识别模型的历史吗?

CVPR 2025落下帷幕,这次关注度和社交参与感,非常深度了。

CVPR 2025,自动驾驶传来重大进展: Scaling Law,首次在这条赛道被验证!

不去今年的CVPR不知道,原来中国自动驾驶在AI领域的创新已经这么牛了。作为今年唯一受邀参与CVPR演讲的车企,这家公司在AI顶流圈层上桌吃饭了!
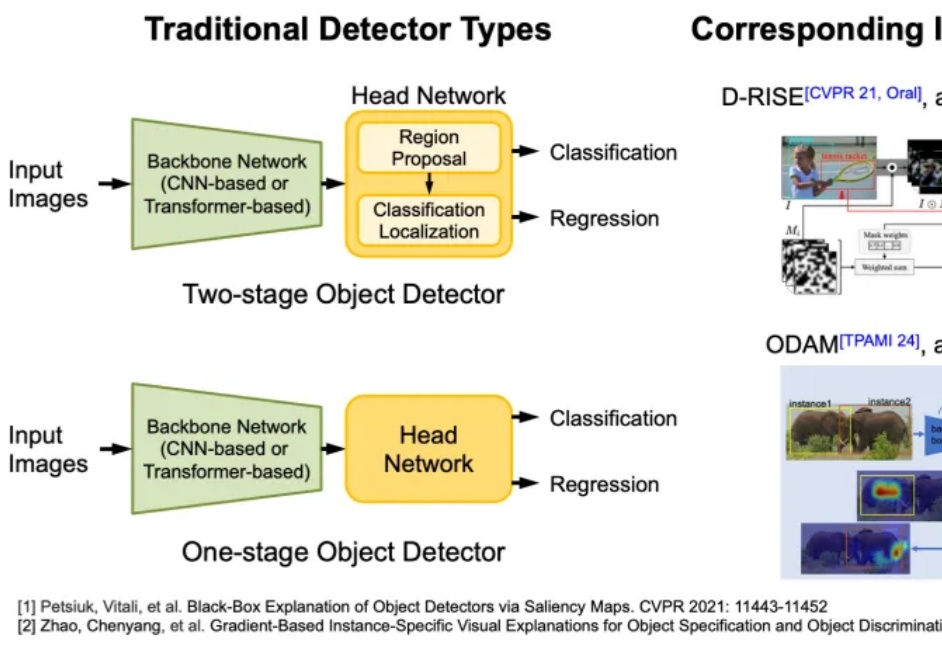
AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。

AI 决策的可靠性与安全性是其实际部署的核心挑战。当前智能体广泛依赖复杂的机器学习模型进行决策,但由于模型缺乏透明性,其决策过程往往难以被理解与验证,尤其在关键场景中,错误决策可能带来严重后果。因此,提升模型的可解释性成为迫切需求。

就在刚刚的CVPR上,鹅厂3D生成模型混元3D 2.1正式宣布开源!