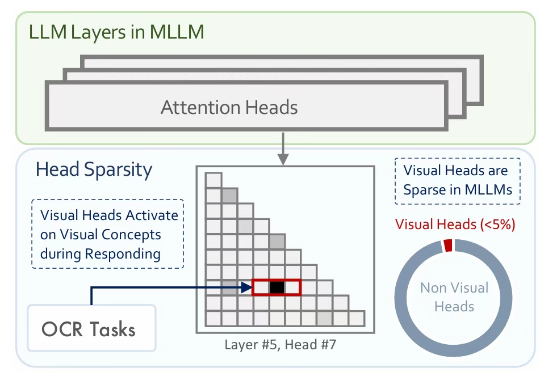
ICCV 2025 | 清华&腾讯混元X发现「视觉头」机制:仅5%注意力头负责多模态视觉理解
ICCV 2025 | 清华&腾讯混元X发现「视觉头」机制:仅5%注意力头负责多模态视觉理解多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。
来自主题: AI技术研报
8539 点击 2025-07-15 10:07
 搜索
搜索
多模态大模型通常是在大型预训练语言模型(LLM)的基础上扩展而来。尽管原始的 LLM 并不具备视觉理解能力,但经过多模态训练后,这些模型却能在各类视觉相关任务中展现出强大的表现。

近年来,多模态大模型(MLLMs)发展迅猛,从看图说话到视频理解,似乎无所不能。
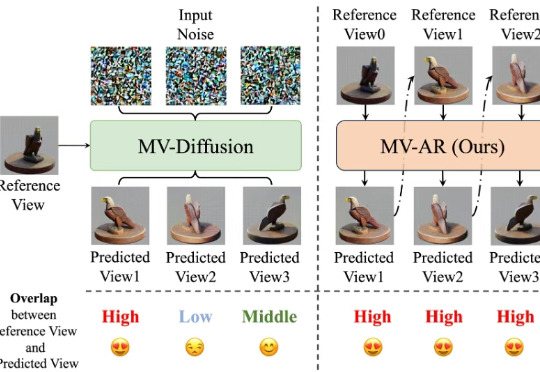
本文介绍并开发了一种自回归生成多视图图像的方法 MVAR 。其目的是确保在生成当前视图的过程中,模型能够从所有先前的视图中提取有效的引导信息,从而增强多视图的一致性。
来自加州大学河滨分校(UC Riverside)、密歇根大学(University of Michigan)、威斯康星大学麦迪逊分校(University of Wisconsin–Madison)、德州农工大学(Texas A&M University)的团队在 ICCV 2025 发表首个面向自动驾驶语义占用栅格构造或预测任务的统一基准框架 UniOcc。
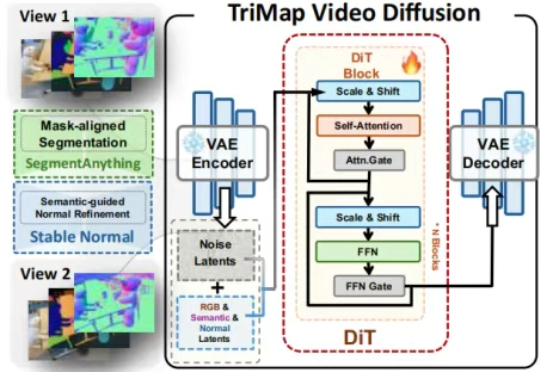
最少只用2张图,AI就能像人类一样理解3D空间了。ICCV 2025最新中稿的LangScene-X:以全新的生成式框架,仅用稀疏视图(最少只用2张图像)就能构建可泛化的3D语言嵌入场景,对比传统方法如NeRF,通常需要20个视角。
最近,上海交通大学 ScaleLab 与香港大学 MMLab@HKU 领衔发布 RoboTwin 系列新作 RoboTwin 2.0 以及基于 RoboTwin 仿真平台在 CVPR 上举办的双臂协作竞赛 Technical Report。

AI竞争加剧下,Meta面临人才外流和模型性能瓶颈。扎克伯格启动"超级智能单元"招募顶尖AI人才失败后,转向企业风险投资(CVC),通过收购Scale AI和入股NFDG基金,旨在提升竞争力,但优质标的稀缺加剧市场挑战。
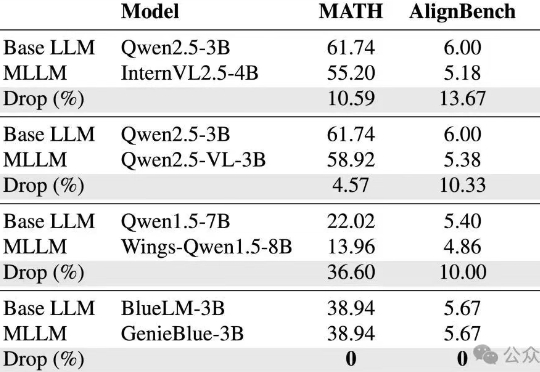
vivo AI研究院联合港中文以及上交团队为了攻克这些难题,从训练数据和模型结构两方面,系统性地分析了如何在MLLM训练中维持纯语言能力,并基于此提出了GenieBlue——专为移动端手机NPU设计的高效MLLM结构方案。

当前大型视觉语言模型(LVLMs)存在物体幻觉问题,即会生成图像中不存在的物体描述。

中科院自动化所提出BridgeVLA模型,通过将3D输入投影为2D图像并利用2D热图进行动作预测,实现了高效且泛化的3D机器人操作学习。