吞下17亿图片,Meta最强巨兽DINOv3开源!重新定义CV天花板
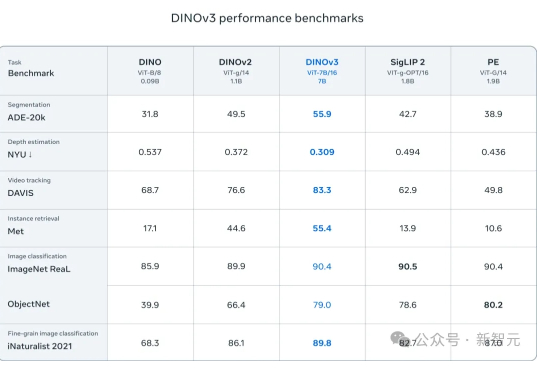
吞下17亿图片,Meta最强巨兽DINOv3开源!重新定义CV天花板无需人工标注,吞下17亿张图片,Meta用自监督学习炼出「视觉全能王」!NASA已将它送上火星,医疗、卫星、自动驾驶领域集体沸腾。
来自主题: AI资讯
8802 点击 2025-08-15 20:36
 搜索
搜索
无需人工标注,吞下17亿张图片,Meta用自监督学习炼出「视觉全能王」!NASA已将它送上火星,医疗、卫星、自动驾驶领域集体沸腾。
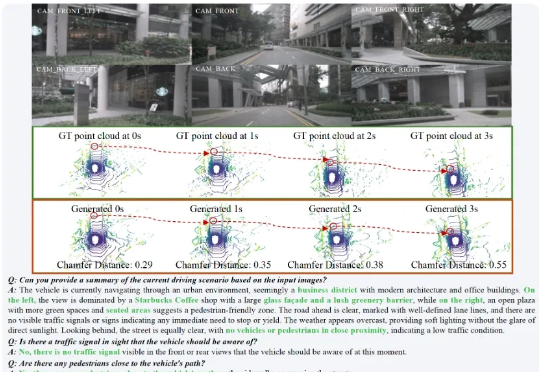
在复杂的城市场景中,HERMES 不仅能准确预测未来三秒的车辆与环境动态(如红圈中标注的货车),还能对当前场景进行深度理解和问答(如准确识别出 “星巴克” 并描述路况)。

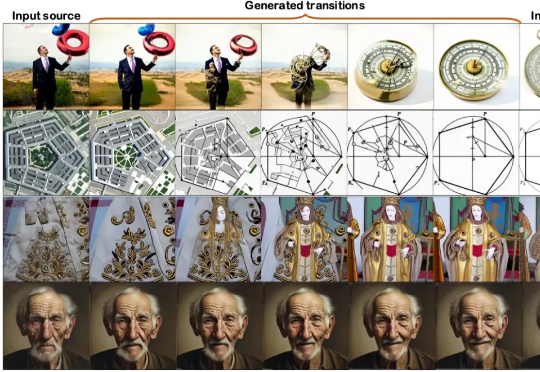
近年来,扩散模型在图像与视频合成领域展现出前所未有的生成能力,为人脸生成与编辑技术按下了加速键。特别是一张静态人脸驱动任意表情、姿态乃至光照的梦想,正在走向大众工具箱,并在三大场景展现巨大潜力
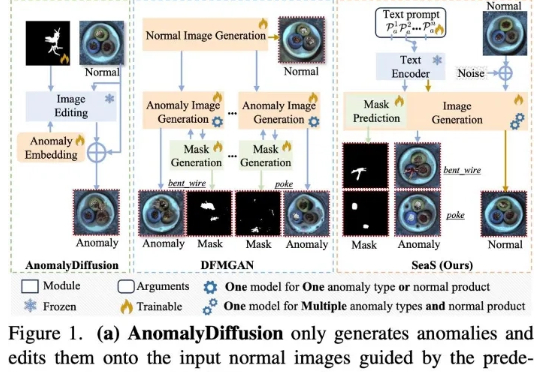
当前先进制造领域的产线良率往往超过 98%,因此异常样本(也称为缺陷样本)的搜集和标注已成为⼯业质检的核⼼瓶颈,过少的异常样本显著限制了模型的检测能⼒,利⽤⽣成模型扩充异常样本集合正逐渐成为产业界的主流选择,但现有⽅法存在明显局限
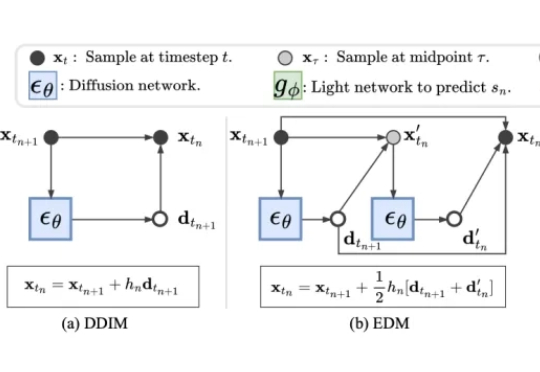
近年来,扩散模型(Diffusion Models)凭借出色的生成质量,迅速成为图像、视频、语音、3D 内容等生成任务中的主流技术。从文本生成图像(如 Stable Diffusion),到高质量人脸合成、音频生成,再到三维形状建模,扩散模型正在广泛应用于游戏、虚拟现实、数字内容创作、广告设计、医学影像以及新兴的 AI 原生生产工具中。

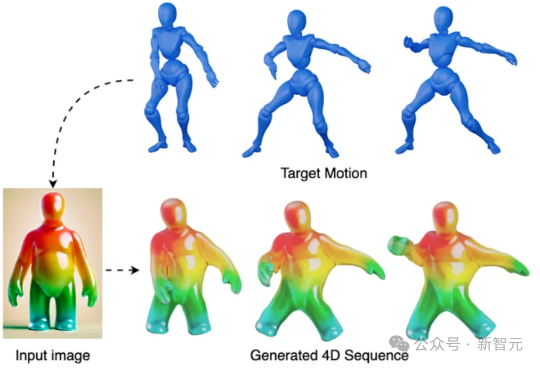
只需一段视频,就可以直接生成可用的4D网格动画?!来自KAUST的研究团队提出全新方法V2M4,能够实现从单目视频直接生成高质量、显式的4D网格动画资源。
PhysRig是UIUC与Stability AI联合提出的首个面向角色动画的可微物理绑定框架。通过将刚性骨架嵌入弹性软体体积,并使用Material Point Method(MPM)进行可微分物理模拟,PhysRig能够自然还原皮肤、脂肪、尾巴等柔性结构的变形过程,显著提升角色动画的真实感,解决传统LBS无法克服的体积丢失与变形伪影问题。
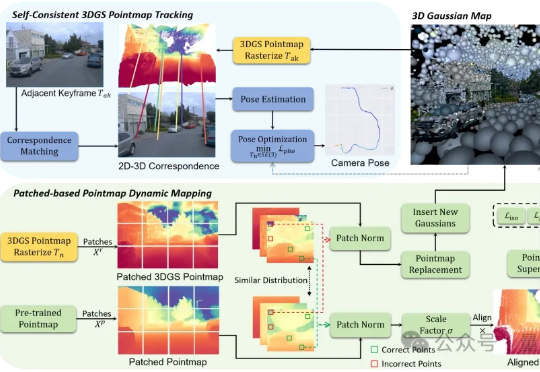
户外SLAM的尺度漂移问题,终于有了新解法! 香港科技大学(广州)的研究的最新成果:S3PO-GS,一个专门针对户外单目SLAM的3D高斯框架,已被ICCV 2025接收。
本文第一作者操雨康,南洋理工大学MMLab博士后,研究方向是3D/4D重建与生成,人体动作/视频生成,以及图像生成与编辑。
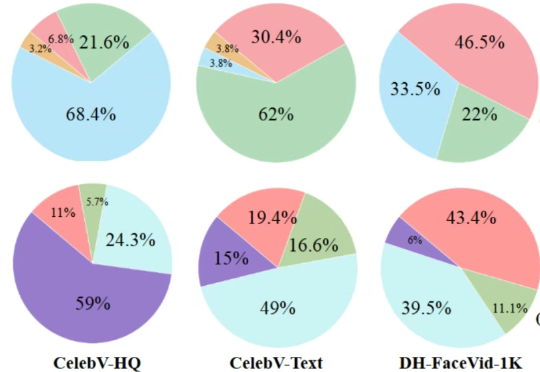
近日,ICCV 2025(国际计算机视觉大会)公布论文录用结果,理想汽车共有 8 篇论文入选,其中 3 篇来自基座模型团队。