# 热门搜索 #
大模型
人工智能
openai
融资
chatGPT
本论文第一作者倪赞林是清华大学自动化系 2022 级直博生,师从黄高副教授,主要研究方向为高效深度学习与图像生成。他曾在 ICCV、CVPR、ECCV、ICLR 等国际会议上发表多篇学术论文。
近年来, AIGC 领域发展十分迅猛。在计算机视觉中,扩散模型已经成为一种有效且常用的模型。相反,在自然语言处理领域,内容的生成通常通过使用 Transformer 去生成离散的 token。受到这种差异的启发,越来越多的研究(以 VQGAN 作为典型代表)开始探索这种基于离散 token 的生成范式在视觉合成中的应用。与扩散模型不同,这些方法采用类似于语言模型的离散 token 作为生成的基本单元。
为什么要探索基于离散 token 的生成模型?我们认为主要有以下几点原因:
1) 由于与语言模型范式相同,它们可以直接利用语言模型中已经成熟的训练、推理技术
2) 有助于开发更先进的、具有共享 token 空间的、scalable 的多模态基础模型
3) 有助于建构统一视觉理解与生成能力的通用视觉基础模型
在基于离散 token 的生成里,近几年非自回归 Transformer (Non-autoregressive Transformer, NAT) 展现出了显著的计算效率与生成质量方面的潜力,不同于传统的自回归生成范式,NAT 能够在仅 4 到 8 步内生成质量不错的图像。它的生成过程如下图所示:
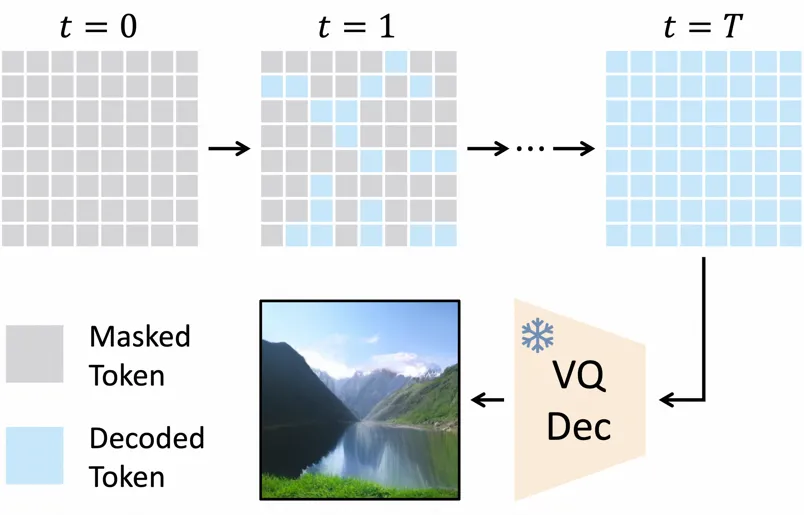
NAT 生成过程的示意图
简单来说,这类模型从一个完全 mask 的 token map 开始,每步并行解码多个 token,直到所有的 token 被解码,然后再通过一个预训练的解码器把 token 空间变换到图像空间,得到生成结果。
虽然 “并行解码” 的机制让模型生成过程更加地高效和灵活。但它也引入了许多复杂的设计挑战,例如每一步应该解码多少 token、应该选择哪些 token、以及采样时应该有多大的随机性等。
现有的工作通过构建一套包含多个人工设计的调度函数(统一记为)的生成策略来缓解这一问题。如下图所示:
NAT 的默认生成策略,其中 T 为总生成推理步数,t 为当前推理步,均为超参数。每一行策略的具体含义可以参见原文
然而,这种人为设计的方式不仅需要大量的专业知识和人力成本,最终得到的策略函数仍然可能并非最佳。与此同时,我们认为不同样本都有其独特的特性,一个应用于所有样本的、全局共享的生成策略可能难以灵活应对样本之间的差异性。
基于上述观察,我们提出 AdaNAT,核心思想是引入一个可学习的策略网络,自动根据每个样本自适应地配置生成策略:
现有工作与 AdaNAT 的对比,这里是当前生成样本在时刻时的 token map
方法介绍
然而,训练一个自适应、自动配置生成策略的网络面临一个直接的挑战:基于离散 token 的生成过程是不可微的,因此我们无法直接采用标准的端到端优化技术如梯度下降的方法来优化这个网络。为应对这一挑战,我们将生成策略的优化问题形式化为马尔可夫决策过程(MDP),在此基础上,策略网络可以自然地被定义为一个「观察生成状态,自适应地配置策略以最大化生成质量」的 agent,也因此可以通过强化学习算法(如策略梯度)进行训练。
另一个值得注意的点是,在我们的问题中,设计合适的奖励函数对于有效训练策略网络至关重要。为了解决这一问题,我们首先考虑了两种现成的设计选择:
然而,我们的实验结果表明,尽管这些设计能够有效地最大化奖励函数,但最终的生成模型往往无法生成足够高质量或足够多样化的图像,如下图所示:
以 FID 作为奖励函数的图像生成效果 (FID=2.56)
以预训练的奖励模型作为奖励函数的图像生成效果 (FID=33.1)
换句话说,策略网络倾向于 “过拟合” 这些预先设定的、静态的奖励函数。受到这一现象的启发,我们的核心思路是在策略网络学习的同时,动态更新奖励函数以防止策略网络过拟合,让二者 “相互对抗,共同进步”。这种思想自然地让我们联想到生成对抗网络 (GAN) 的想法,因此,我们提出了一个对抗奖励模型,该模型类似于 GAN 中的判别器,以生成样本为真实图片的概率作为奖励。当策略网络学习最大化奖励时,我们同时优化奖励模型,以更好地区分真实样本和生成样本。总结来看,AdaNAT 的方法示意图如下:
AdaNAT 示意图
实验结果
我们在多个基准数据集上验证了 AdaNAT 的有效性,包括 ImageNet 的 class-conditional 生成以及 MSCOCO 和 CC3M 数据集的文到图生成。
得益于 NAT 生成范式中并行解码的优势,AdaNAT 在 ImageNet-256 和 ImageNet-512 数据集上,相较于主流的扩散模型,在低开销场景下,推理开销至少减少了 2-3 倍,同时生成效果更佳:
ImageNet-256 class-conditional 生成结果
ImageNet-512 class-conditional 生成结果
此外,在文到图生成方面,AdaNAT 也有着不错的表现:
MSCOCO 文到图生成结果
CC3M 文到图生成结果
在模型的优化过程中,我们也能明显看到生成质量随着策略网络的学习而提升,同时 FID 指标也有相应的下降:
AdaNAT 的优化过程可视化
消融实验发现,引入可学习、自适应的策略都对提升 NAT 的生成质量有所帮助:
消融实验
最后,我们也可视化了 AdaNAT 模型生成的图片,总的来看,AdaNAT 的生成样本同时具有良好的生成质量与多样性:
AdaNAT 生成结果可视化
文章来源“机器之心”,作者“机器之心”



【开源免费】AutoGPT是一个允许用户创建和运行智能体的(AI Agents)项目。用户创建的智能体能够自动执行各种任务,从而让AI有步骤的去解决实际问题。
项目地址:https://github.com/Significant-Gravitas/AutoGPT
【开源免费】MetaGPT是一个“软件开发公司”的智能体项目,只需要输入一句话的老板需求,MetaGPT即可输出用户故事 / 竞品分析 / 需求 / 数据结构 / APIs / 文件等软件开发的相关内容。MetaGPT内置了各种AI角色,包括产品经理 / 架构师 / 项目经理 / 工程师,MetaGPT提供了一个精心调配的软件公司研发全过程的SOP。
项目地址:https://github.com/geekan/MetaGPT/blob/main/docs/README_CN.md
