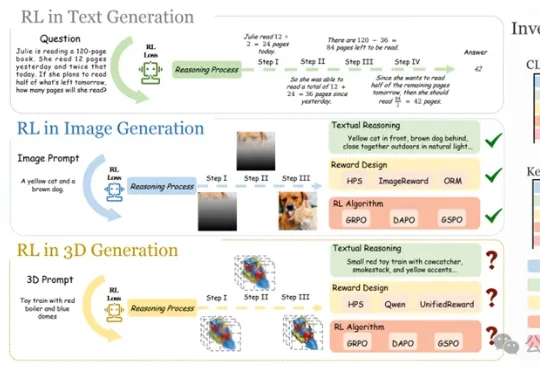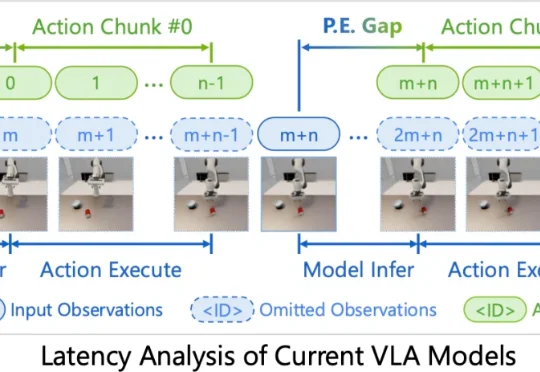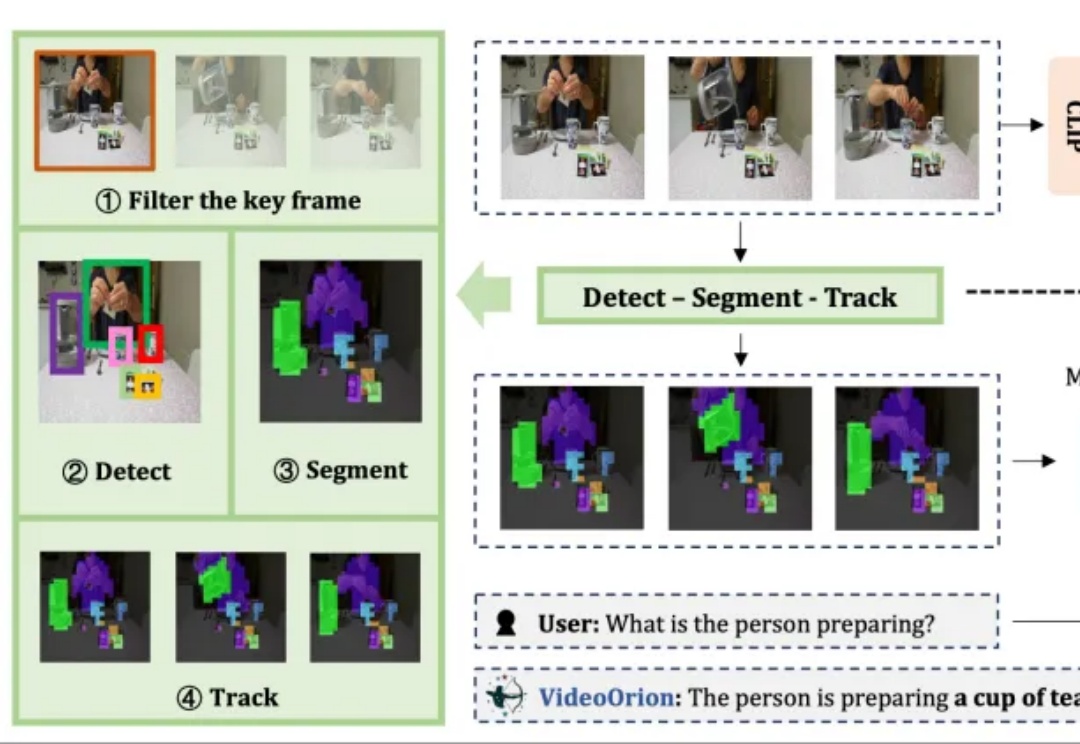
CVPR 2026 | 1B模型也能当多镜头导演?大连理工&快手可灵开源力作MultiShotMaster
CVPR 2026 | 1B模型也能当多镜头导演?大连理工&快手可灵开源力作MultiShotMaster近期,大连理工与快手可灵团队推出了 MultiShotMaster—— 一个高度可控的多镜头视频生成框架,该论文向研究社区展示了即使在 1B 左右的小参数量级模型上,也可以实现导演级的镜头调度和连贯叙事,且支持多图参考、主体运动控制。
来自主题: AI技术研报
9715 点击 2026-03-06 15:06