GRPO训练不再「自嗨」!快手可灵 x 中山大学推出「GRPO卫兵」,显著缓解视觉生成过优化
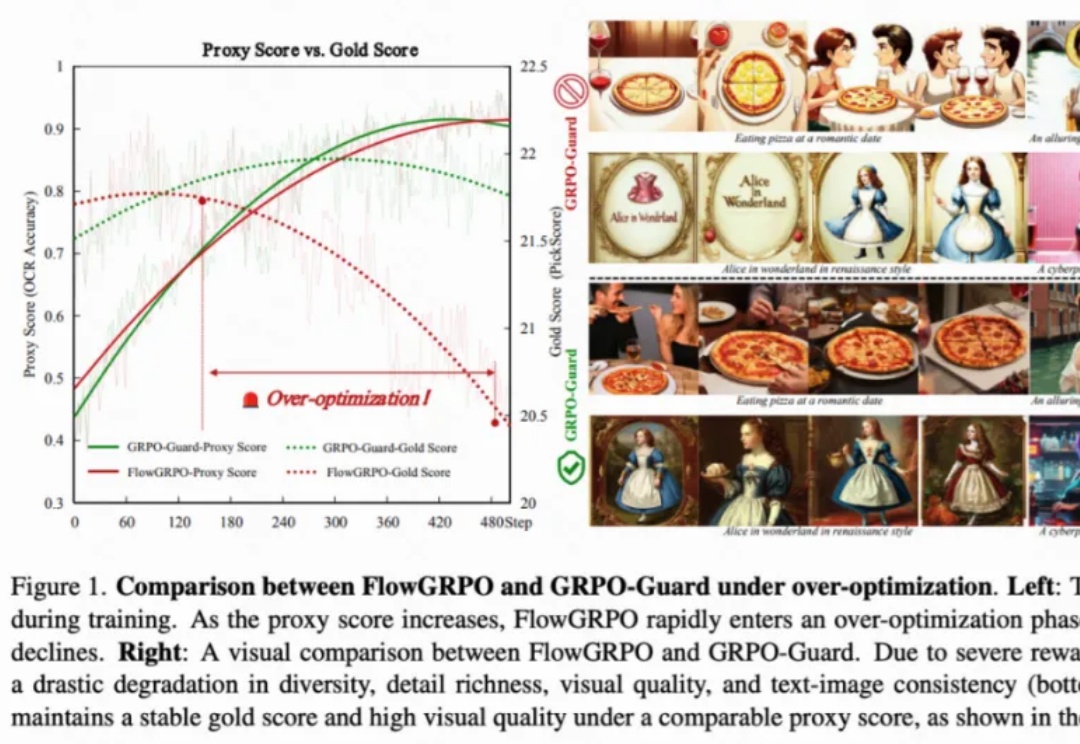
GRPO训练不再「自嗨」!快手可灵 x 中山大学推出「GRPO卫兵」,显著缓解视觉生成过优化目前,GRPO 在图像和视频生成的流模型中取得了显著提升(如 FlowGRPO 和 DanceGRPO),已被证明在后训练阶段能够有效提升视觉生成式流模型的人类偏好对齐、文本渲染与指令遵循能力。
来自主题: AI技术研报
9164 点击 2025-11-13 14:52
 搜索
搜索
目前,GRPO 在图像和视频生成的流模型中取得了显著提升(如 FlowGRPO 和 DanceGRPO),已被证明在后训练阶段能够有效提升视觉生成式流模型的人类偏好对齐、文本渲染与指令遵循能力。

近期,北京大学与字节团队提出了名为 BranchGRPO 的新型树形强化学习方法。不同于顺序展开的 DanceGRPO,BranchGRPO 通过在扩散反演过程中引入分叉(branching)与剪枝(pruning),让多个轨迹共享前缀、在中间步骤分裂,并通过逐层奖励融合实现稠密反馈。

R1 横空出世,带火了 GRPO 算法,RL 也随之成为 2025 年的热门技术探索方向,近期,字节 Seed 团队就在图像生成方向进行了相关探索。