
惊了!Hassabis才是AI世界的隐藏Boss?黑手党4年卷走140亿
惊了!Hassabis才是AI世界的隐藏Boss?黑手党4年卷走140亿谷歌AI掌门Hassabis,竟是死敌Anthropic的最大金主?表面上打得刺刀见红,背地里沙发挤挤兄弟情深。最可怕的是,如今的硅谷,已经被他手下的DeepMind黑手党包圆了!
来自主题: AI资讯
10328 点击 2026-05-21 13:19
 搜索
搜索
谷歌AI掌门Hassabis,竟是死敌Anthropic的最大金主?表面上打得刺刀见红,背地里沙发挤挤兄弟情深。最可怕的是,如今的硅谷,已经被他手下的DeepMind黑手党包圆了!

DeepSeek Code要来了。

近日,谷歌 DeepMind 研究员 Lun Wang@lunwang1996,在 x 上发文宣布自己已经从 DeepMind 离职,结束了这段非常精彩的旅程,「我非常感谢曾经共事的人、我们一起打造的东西,以及我在将前沿 AI 研究推向生产环境过程中学到的经验。」
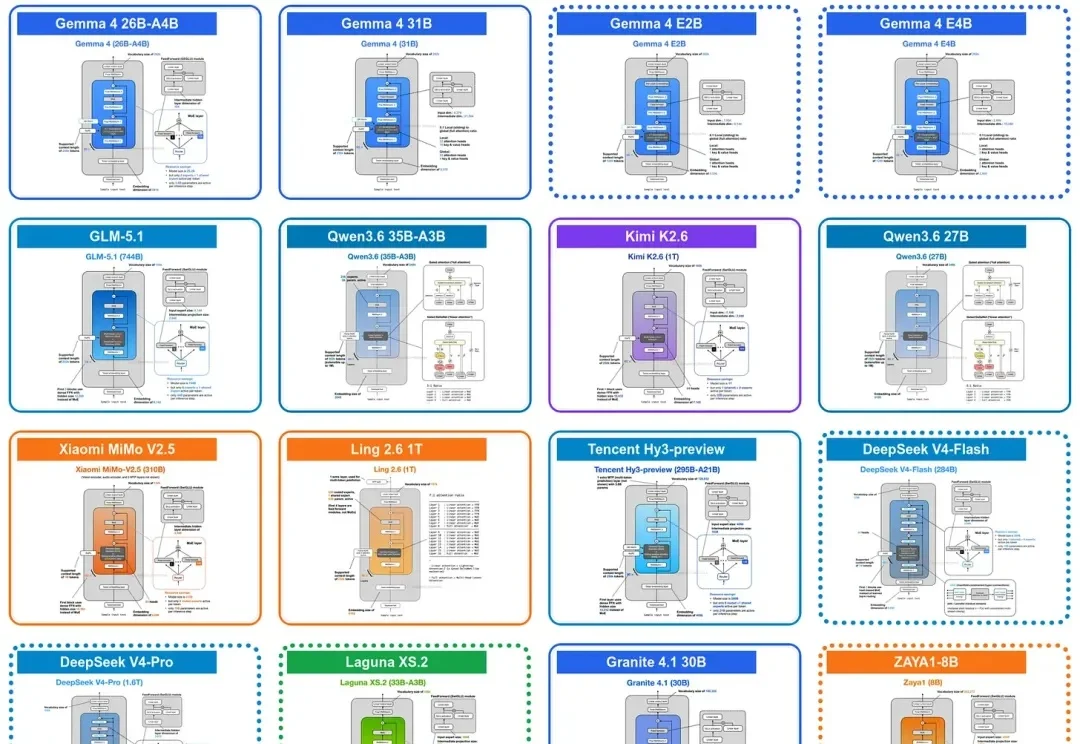
过去一段时间,很多人对大模型都有一个明显感受:token 总是不够用。
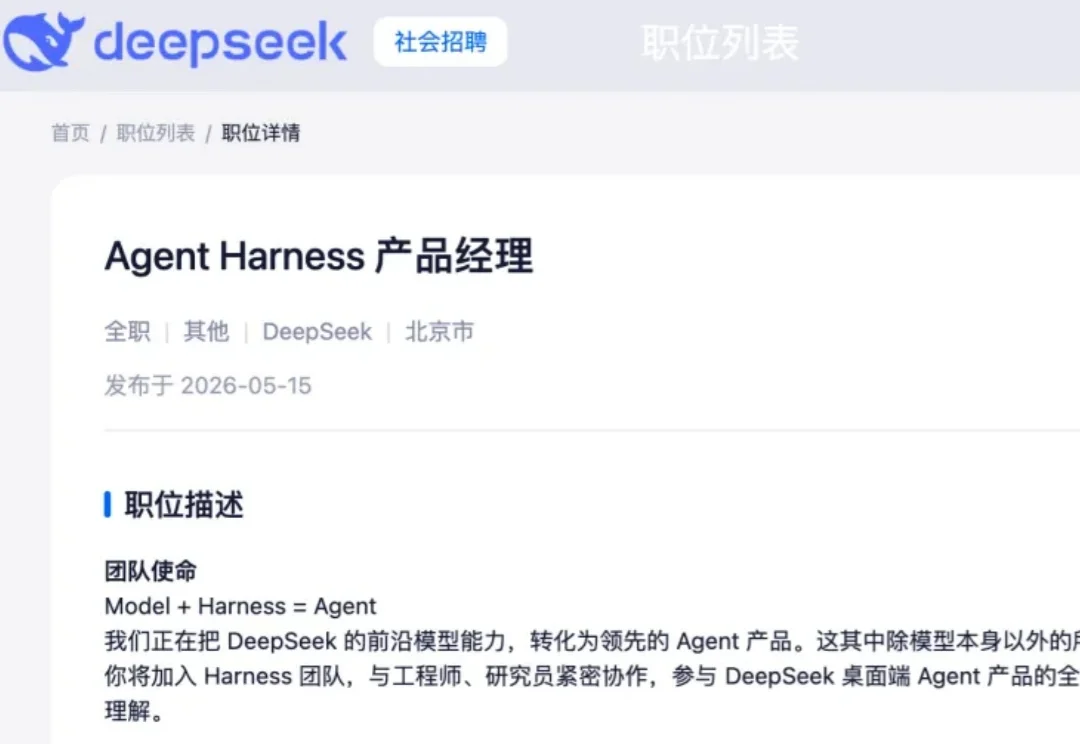
DeepSeek最新热招岗位已上线:Agent Harness产品经理。

2026 年 5 月,深度机智(DeepCybo)迎来成立一周年。

5000亿门槛前,中国大模型谁最像真巨头?

押注AI基础设施、新云和大模型。

从谷歌DeepMind分拆而出的AI药物英国研发公司Isomorphic Labs昨日宣布完成21亿美元(约合人民币143亿元)B轮融资。据外媒Ventureburn报道,这笔融资创下全球AI制药行业单笔融资新纪录。

以 DeepSeek-R1、OpenAI GPT Thinking 为代表的大型推理模型,通过长达数千 token 的「思维链」在各类复杂推理任务中展现出卓越的性能。然而,这些模型普遍存在一个核心问题,即过度思考(overthinking) :