
DeepSeek估值,被一家安徽箱包公司给全部暴露了
DeepSeek估值,被一家安徽箱包公司给全部暴露了谁曾想呢,DeepSeek一直没有公开讲清楚的融资估值,被一家卖行李箱的公司给全部暴露了。7月16日晚间,安徽开润股份发布了一份投资进展公告。公告显示,开润股份参与投资的一只基金,已经将29亿元实缴资金全部间接投向DeepSeek,获得后者0.8265%的股权。
来自主题: AI资讯
8910 点击 2026-07-19 10:10
 搜索
搜索
谁曾想呢,DeepSeek一直没有公开讲清楚的融资估值,被一家卖行李箱的公司给全部暴露了。7月16日晚间,安徽开润股份发布了一份投资进展公告。公告显示,开润股份参与投资的一只基金,已经将29亿元实缴资金全部间接投向DeepSeek,获得后者0.8265%的股权。
7月15日,前谷歌DeepMind科学家Alex Turner宣布辞职。在一篇令人震惊的长文中,他揭露了谷歌如何一步步向五角大楼妥协,最终签下一份「毫无红线」的军事AI协议。以下,是Alex Turner用离职换来的惊人真相。
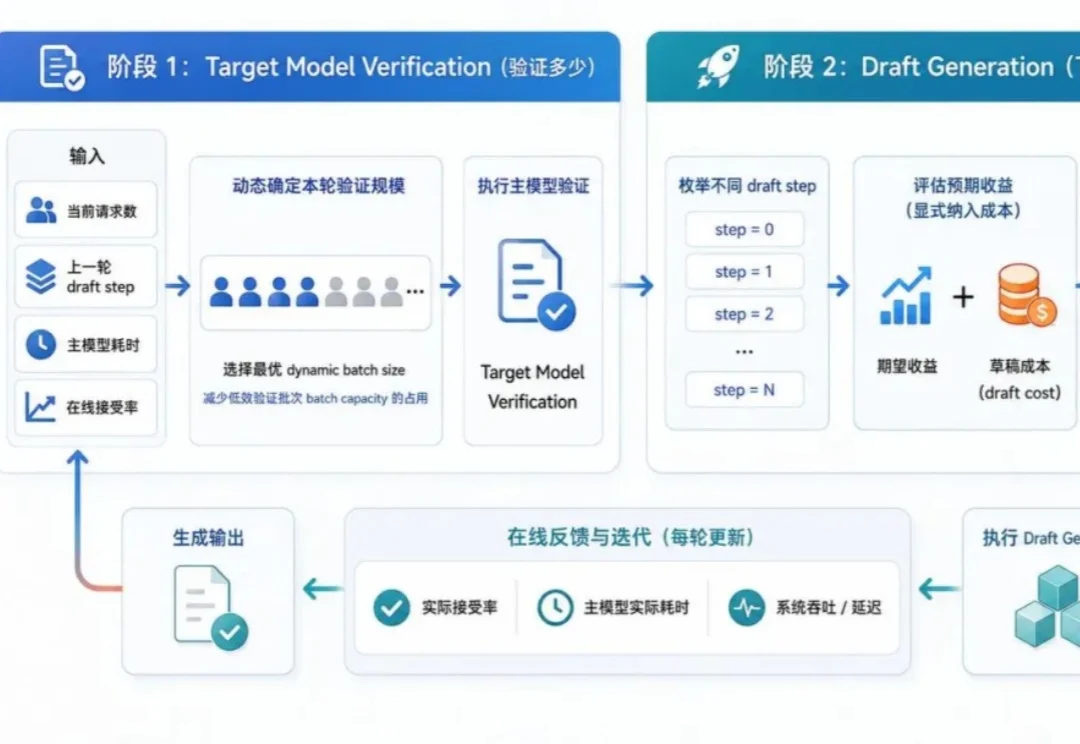
随着 DeepSeek 发布 DSpark,动态 MTP(多 Token 预测)成为了对抗高并发、提升 GPU 利用率的绝对焦点。然而,DSpark 高度绑定特定模型且需要额外训练。

7 月 16 日,月之暗面正式发布 Kimi K3:总参数量 2.8 万亿(2.8T),原生视觉理解,100 万 token 上下文,并且——开源权重。这是历史上第一个摸到 2.8 万亿参数量级的开源模型。前任"开源最大模型"的纪录保持者?也是它自己。

推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。
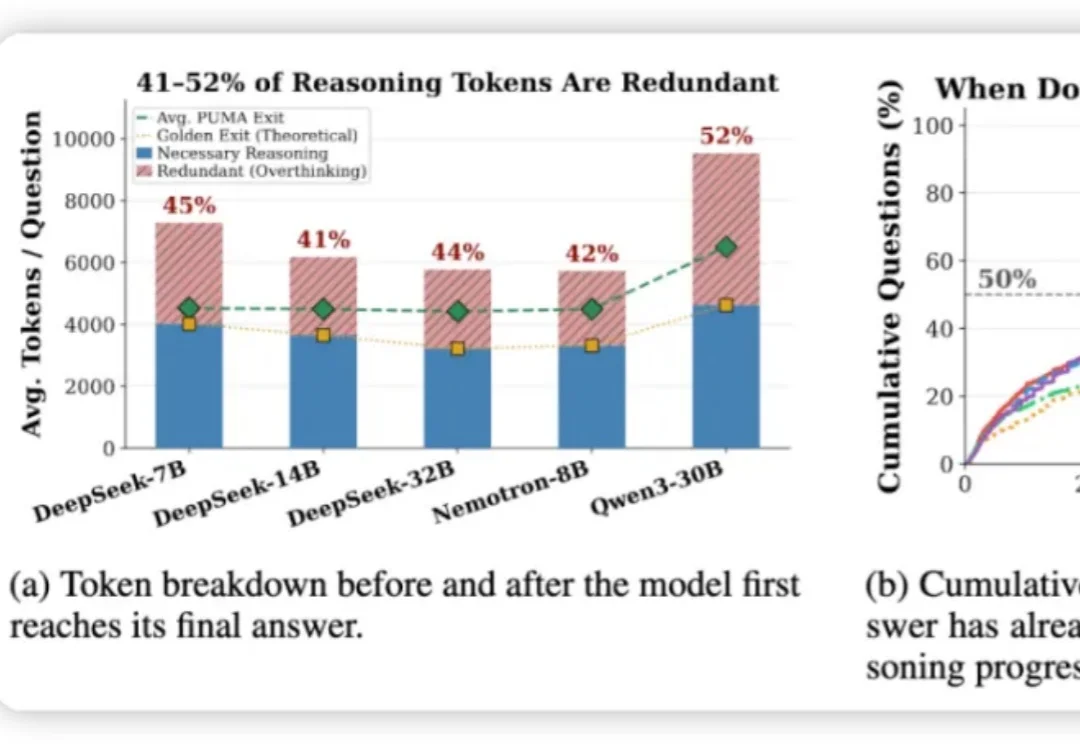
推理大模型 (如 DeepSeek-R1、o1) 靠长思维链拿高分,却普遍「想太多」: 研究统计了五个代表性模型里,发现有 41–52% 的 token 是在模型给出它的最终答案之后生成的。

最新消息终于来了——Gemini 3.5 Pro或将于7月17日正式上线。更有意思的是,这个日期恰好与国产大模型DeepSeek V4正式版的发布窗口正面重合。那么这一次,谷歌拿出的究竟是“真金”还是“虚火”?不妨从三个维度拆解一下。

过去 12 个小时,关于 DeepSeek 的消息一个接一个炸出来。

硬氪获悉,水下AI自然探索科技公司Deeplore近日完成数千万元种子轮融资,由五源资本、顺为资本联合投资。资金将核心用于研发团队扩建与水下AI技术深耕,加速首款AI潜水面镜落地迭代,搭建水下自然探索智能平台的技术底座。

7月14日,AI for Materials公司深度原理Deep Principle完成A系列融资,累计融资金额近10亿元人民币。A系列融资的募集资金将用于以下方向:持续升级AI Scientist能力,扩大全球领先优势;依托AI Materials Factory,加速重点材料管线研发落地;深化海内外上下游合作,共同构建产业生态。