
挑战GRPO,英伟达提出GDPO,专攻多奖励优化
挑战GRPO,英伟达提出GDPO,专攻多奖励优化GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。
来自主题: AI技术研报
8482 点击 2026-01-12 09:34
 搜索
搜索
GRPO 是促使 DeepSeek-R1 成功的基础技术之一。最近一两年,GRPO 及其变体因其高效性和简洁性,已成为业内广泛采用的强化学习算法。

几天前,DeepSeek 毫无预兆地更新了 R1 论文,将原有的 22 页增加到了现在的 86 页。新版本充实了更多细节内容,包括首次公开训练全路径,即从冷启动、训练导向 RL、拒绝采样与再微调到全场景对齐 RL 的四阶段 pipeline,以及「Aha Moment」的数据化验证等等。
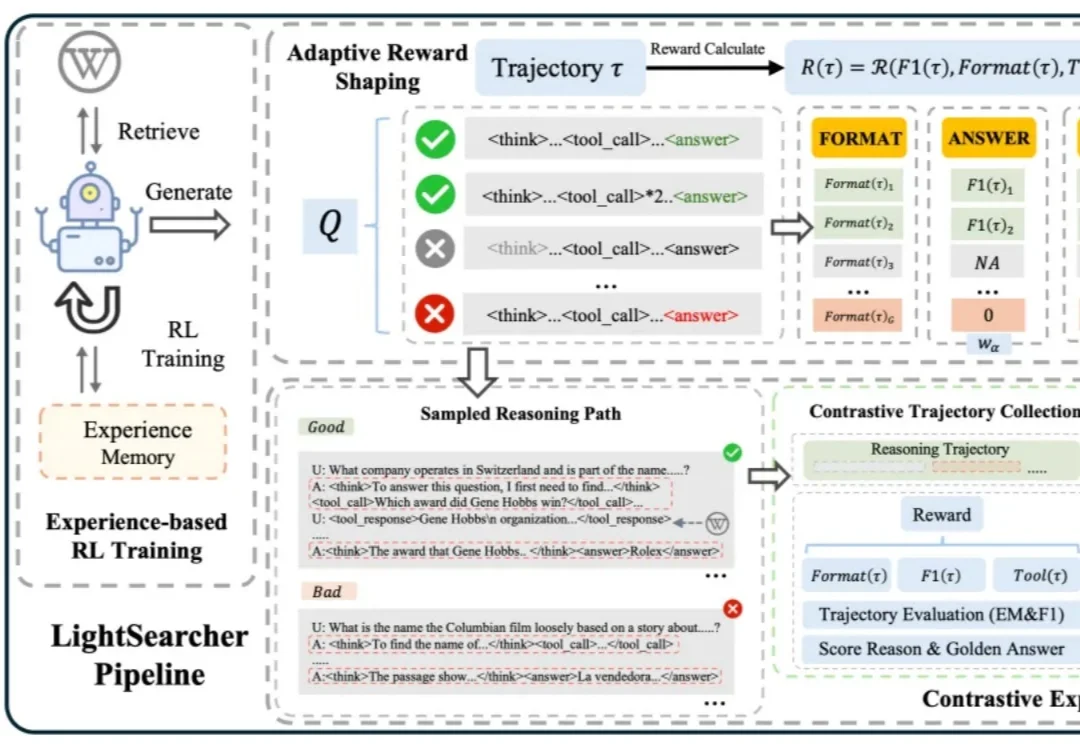
如今,以 DeepSeek-R1 为代表的深度思考大模型能够处理复杂的推理任务,而DeepSearch 作为深度思考大模型的核心搜索器,在推理过程中通过迭代调用外部搜索工具,访问参数边界之外的最新、领域特定知识,从而提升推理的深度和事实可靠性。

近日,微博正式发布首个自研开源大模型VibeThinker,这个仅拥有15亿参数的“轻量级选手”,在国际顶级数学竞赛基准测试上击败了参数量是其数百倍的、高达6710亿的DeepSeek R1模型。
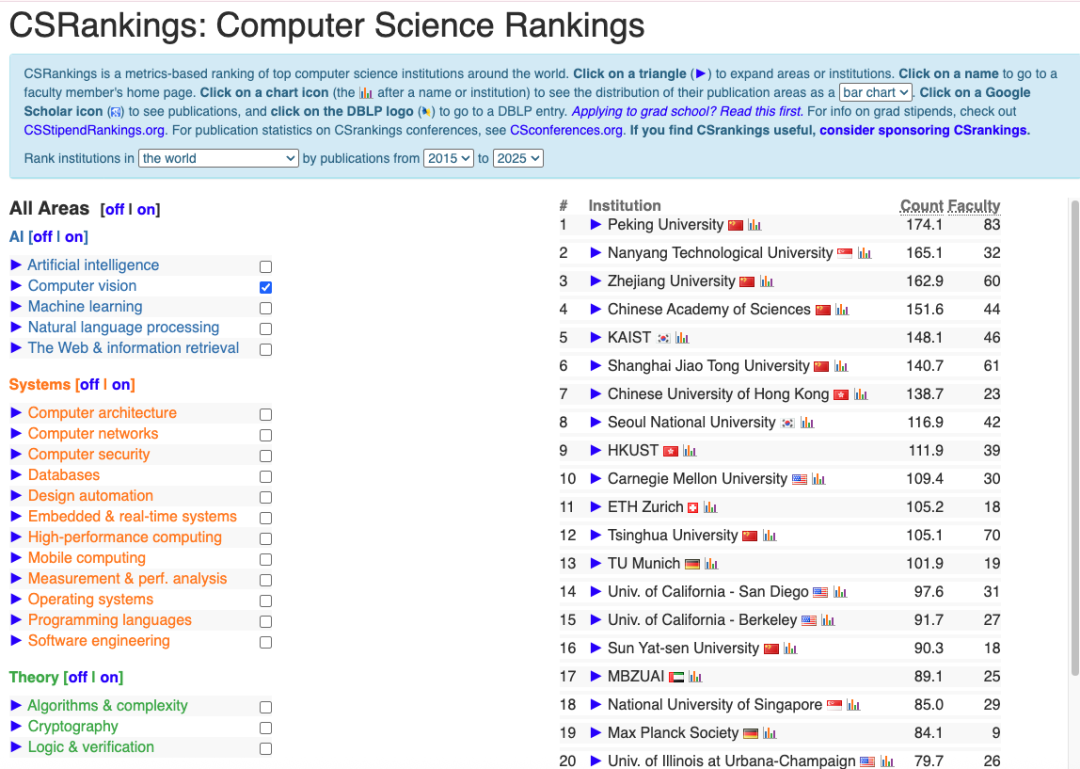
在计算机科学领域, CSRankings 曾被视为一次划时代的改进。它摒弃了早期诸如 USNews 那样依赖调查问卷的主观排名体系,转而以论文发表数量这一客观指标来评估各大学的科研实力。

2025年前盛行的闭源+重资本范式正被DeepSeek-R1与月之暗面Kimi K2 Thinking改写,二者以数百万美元成本、开源权重,凭MoE与MuonClip等优化,在SWE-Bench与BrowseComp等基准追平或超越GPT-5,并以更低API价格与本地部署撬动市场预期,促使行业从砸钱堆料转向以架构创新与稳定训练为核心的高效路线。
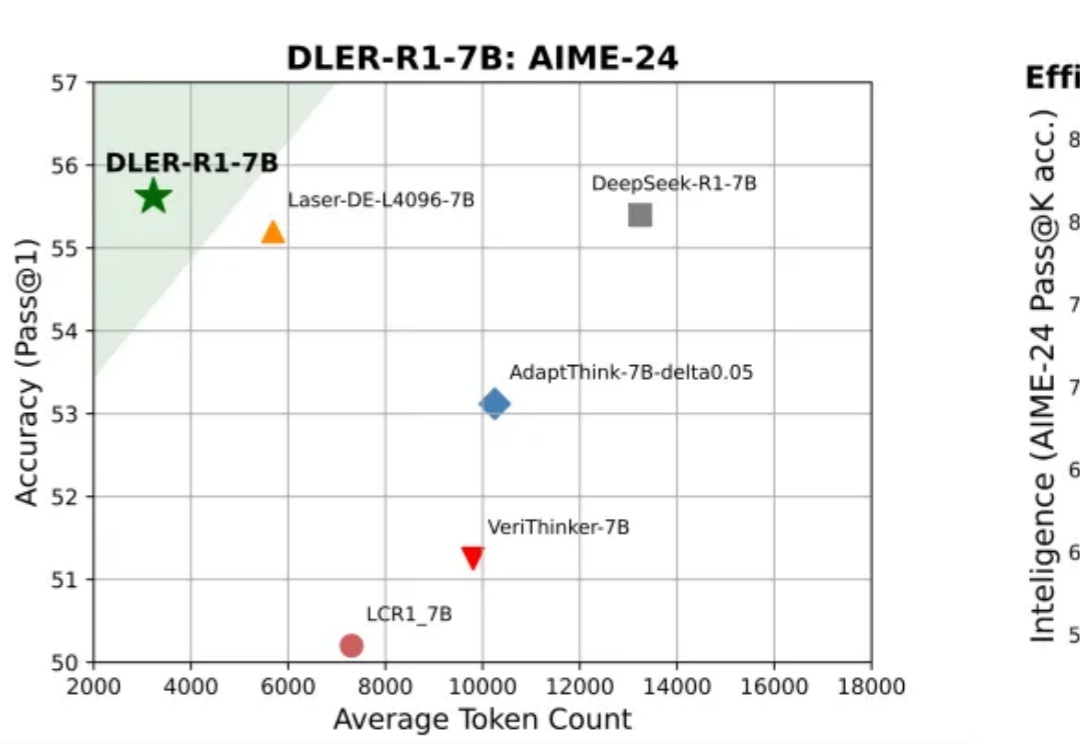
大模型推理到底要不要「长篇大论」?过去一年,OpenAI o 系列、DeepSeek-R1、Qwen 等一系列推理模型,把「长链思维」玩到极致:答案更准了,但代价是推理链越来越长、Token 消耗爆炸、响应速度骤降。
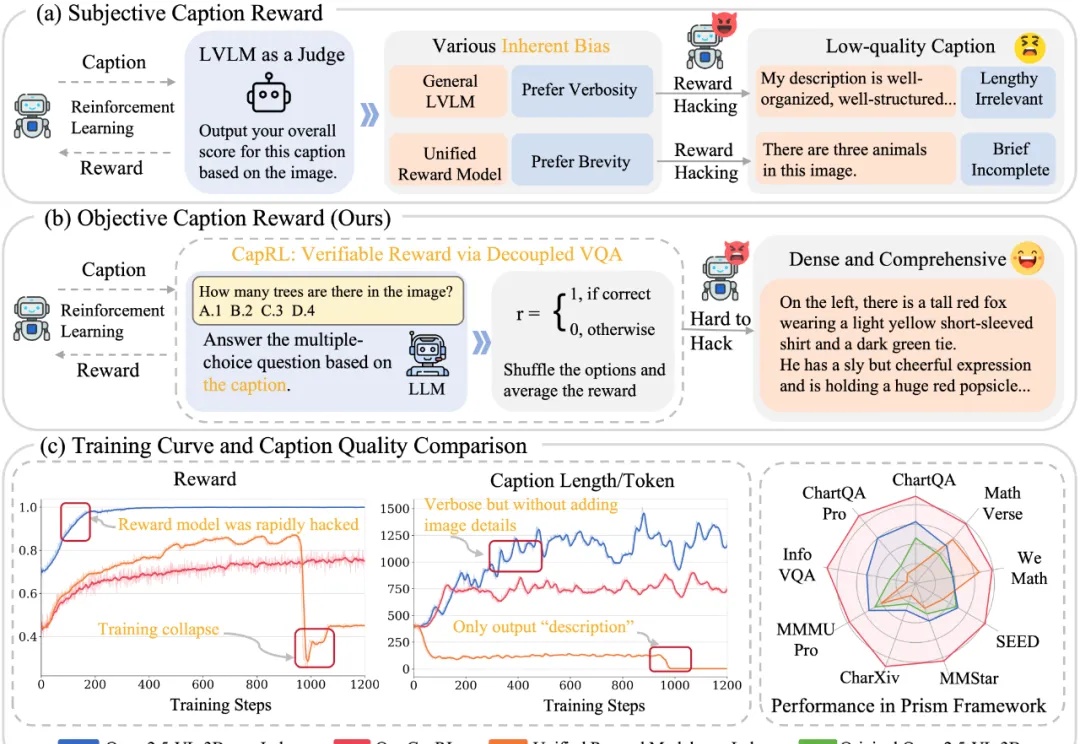
今天推荐一个 Dense Image Captioning 的最新技术 —— CapRL (Captioning Reinforcement Learning)。CapRL 首次成功将 DeepSeek-R1 的强化学习方法应用到 image captioning 这种开放视觉任务,创新的以实用性重新定义 image captioning 的 reward。

时隔两月,Baichuan-M2 Plus重磅出世!成为业内首个循证增强的医疗大模型,幻觉要比DeepSeek-R1低3倍,可信度比肩资深临床专家。新模型将「循证医学」理念深度融入训练和推理,通过首创「六源循证范式」,模拟人类医生思维,有效辨别不同层级医学证据、评估其可靠性,并在回答中优先引用高等级证据。

年初的 DeepSeek-R1,带来了大模型强化学习(RL)的火爆。无论是数学推理、工具调用,还是多智能体协作,GRPO(Group Relative Policy Optimization)都成了最常见的 RL 算法。