
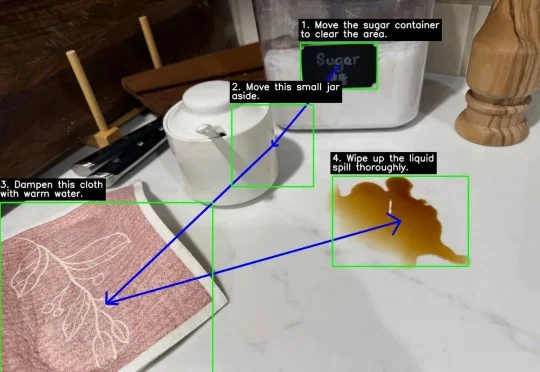
开源免费!推荐一款基于DeepSeek大模型RAG知识库与知识图谱平台,打通飞书、企业微信、钉钉
开源免费!推荐一款基于DeepSeek大模型RAG知识库与知识图谱平台,打通飞书、企业微信、钉钉语析Yuxi-Know 是基于大模型RAG知识库与知识图谱技术构建的智能问答平台,支持多种知识库文件格式,如PDF、TXT、MD、Docx,支持将文件内容转换为向量存储,便于快速检索。
来自主题: AI技术研报
7158 点击 2026-02-02 13:23
 搜索
搜索
语析Yuxi-Know 是基于大模型RAG知识库与知识图谱技术构建的智能问答平台,支持多种知识库文件格式,如PDF、TXT、MD、Docx,支持将文件内容转换为向量存储,便于快速检索。


这个春节,中国 AI 迎来「决战时刻」。据《The Information》援引内部消息人士透露:字节或将祭出全模态三件套;阿里除了或将发布强大的全新旗舰模型 Qwen 3.5 外,也会让千问打通支付与电商,挑战豆包;DeepSeek V4 或将携最强代码能力突袭。这不仅是技术竞赛,更是对 14 亿用户生活入口与未来互联网秩序的终极争夺。
没想到吧,Google DeepMind刚刚为Gemini 3 Flash推出了一个重量级新能力:Agentic Vision(智能体视觉)。(难道是被DeepSeek-OCR2给刺激到了?)

就在刚刚,月之暗面正式发布并开源了 Kimi k2.5。

嘿!刚刚,DeepSeek 又更新了!这次是更新了十月份推出的 DeepSeek-OCR 模型。刚刚发布的 DeepSeek-OCR 2 通过引入 DeepEncoder V2 架构,实现了视觉编码从「固定扫描」向「语义推理」的范式转变!

DeepSeek开源DeepSeek-OCR2,引入了全新的DeepEncoder V2视觉编码器。该架构打破了传统模型按固定顺序(从左上到右下)扫描图像的限制,转而模仿人类视觉的「因果流(Causal Flow)」逻辑。

这一框架可用于集成额外文本、语音和视觉等多种模态。

Sora画下的饼终于被做熟了!用DeepSeek式的慢思考逻辑,把AI视频从「看运气抽卡」变成了「确定性交付」,这才是电商人真正需要的工业革命。
“DeepSeek-V3是在Mistral提出的架构上构建的。”