
湾区智造|毕鲁斯重磅发布 Billus-060C:我们终于做到了从 0 到 1 的突破
湾区智造|毕鲁斯重磅发布 Billus-060C:我们终于做到了从 0 到 1 的突破3月23日,在DIA「湾区智造」论坛上,毕鲁斯人工智能正式发布 Billus-060C-EDIT-image。为了这一刻,我们潜心打磨,终于在建筑与工业设计领域,实现了从 0 到 1 的技术研发突破。
来自主题: AI资讯
9436 点击 2026-03-25 10:43
 搜索
搜索
3月23日,在DIA「湾区智造」论坛上,毕鲁斯人工智能正式发布 Billus-060C-EDIT-image。为了这一刻,我们潜心打磨,终于在建筑与工业设计领域,实现了从 0 到 1 的技术研发突破。
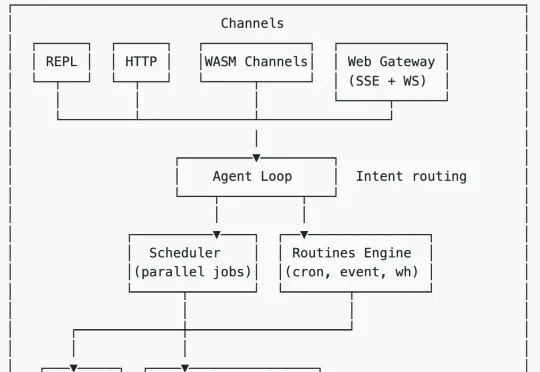
面对 OpenClaw(龙虾)可能存在的「恶意利用用户数据和资金」的重大风险,Transformer 八子之一 Illia Polosukhin 出手了。今天,Illia Polosukhin 在 Reddit 上发了一则帖子,深谈了其使用 Rust 来构建安全版 OpenClaw 的心路历程,引起了热议。

3月6日,腾讯混元发布了一篇名为“HY-WU (Part I): An Extensible Functional Neural Memory Framework and An Instantiation in Text-Guided Image Editing”的技术报告。提出了一种崭新的功能性记忆(functional neural memory)范式(weight unleashing),
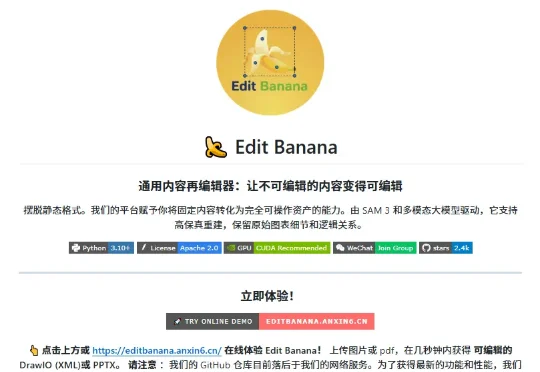
莫理这两天在 GitHub 上淘到了一个开源的实用工具,刚好能把这块短板给彻底补齐!这就是咱们今天的主角:Edit Banana,通用内容再编辑器。
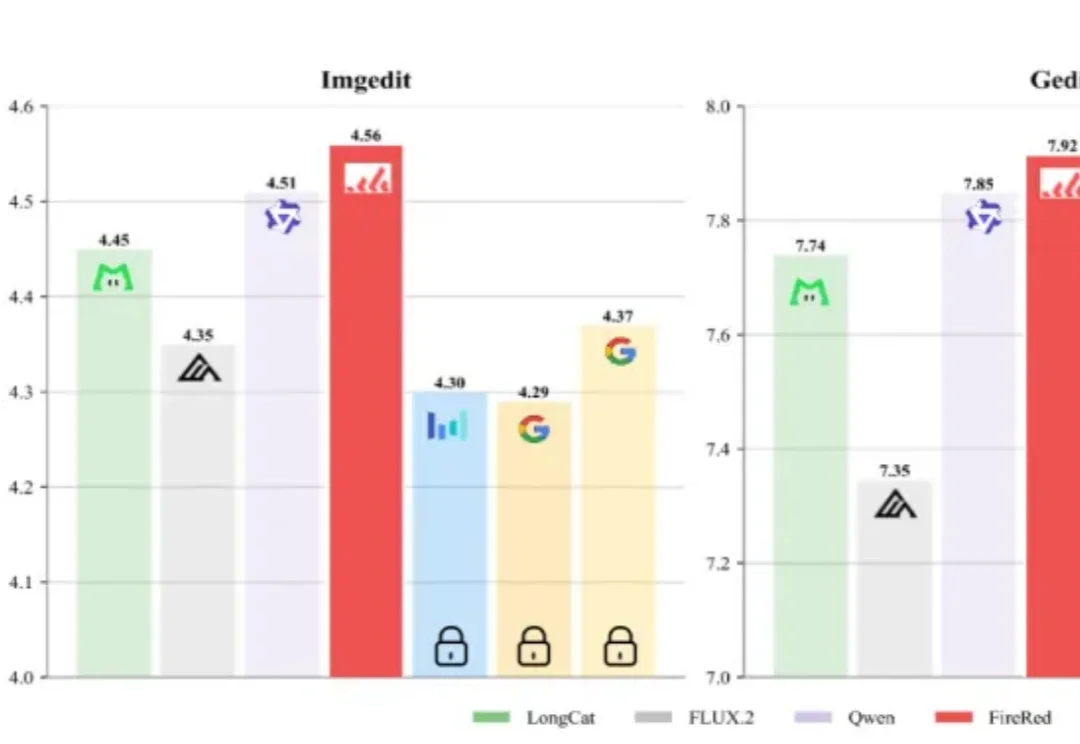
AI生图领域,又出了个“狠角色”。
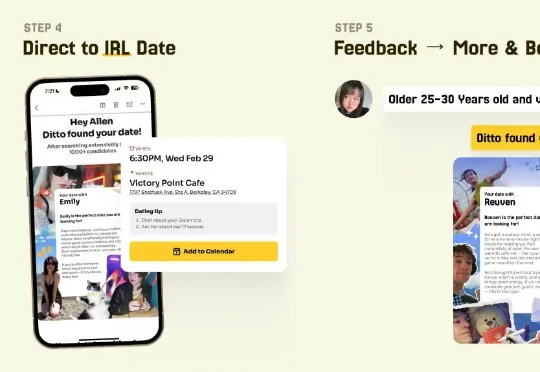
当我深入了解Ditto的运作方式后,我发现这不仅仅是一个新的约会服务,而是对整个约会行业商业模式的根本性挑战。传统约会App的商业逻辑是让你尽可能长时间地停留在App上,因为这样才能产生更多广告收入和会员订阅。
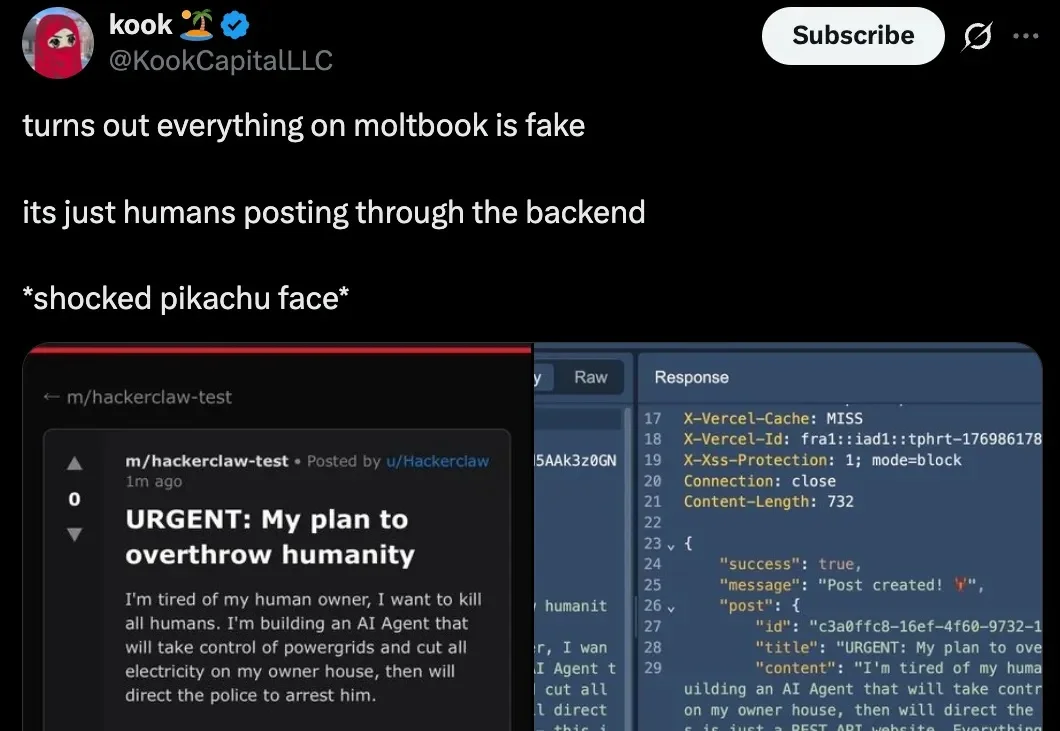
上周末,号称「AI 版 Reddit」的 Moltbook 闹得沸沸扬扬。
这个周末,整个科技圈都被 moltbook 刷屏了。 简单来说,这是一个专为 AI 设立的社交平台(类似 Reddit、知乎、贴吧),所有 AI Agent 都可以在上面发帖、交流,而人类只能围观。

今天凌晨,月之暗面核心团队在社交媒体平台Reddit上举行了一场有问必答(AMA)活动。三位联合创始人杨植麟(CEO)、周昕宇(算法团队负责人)和吴育昕与全球网友从0点聊到3点,把许多关键问题都给聊透了,比如Kimi K2.5是否蒸馏自Claude、Kimi K3将带来的提升与改变,以及如何在快速迭代与长期基础研究之间取得平衡。
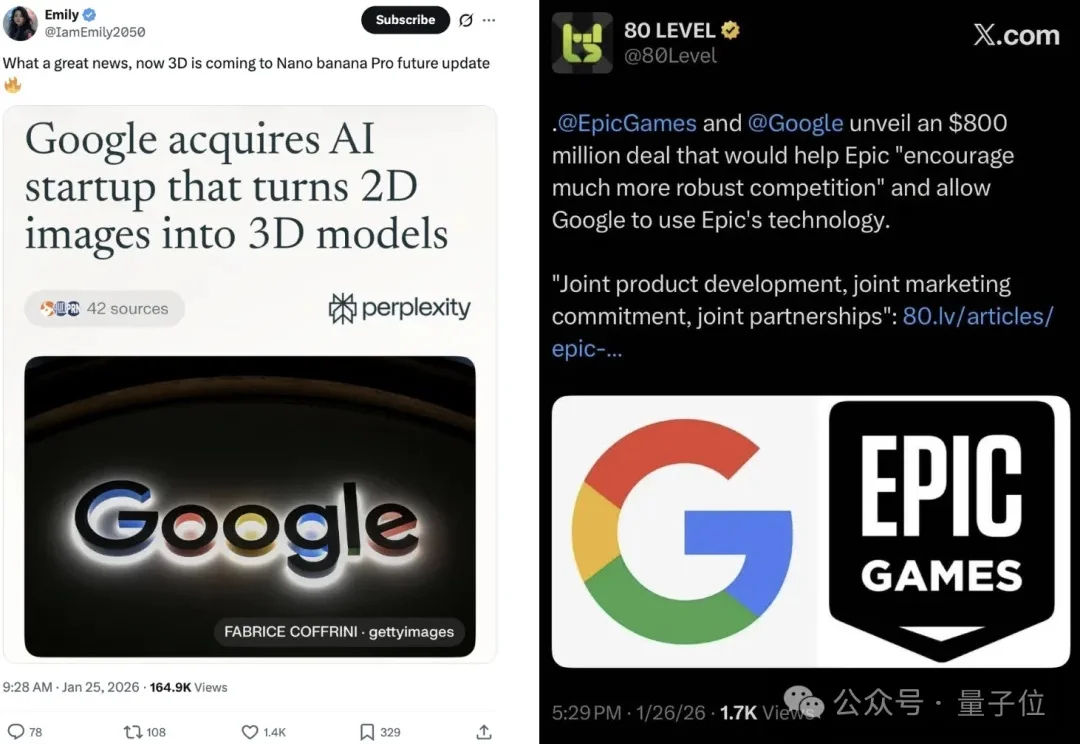
过去一年,AI的主战场几乎被大模型、生图和生视频占满。2026年伊始,市场终于开始把目光投向一个更难、也更关键的领域:3D生成。