
首帧的真正秘密被揭开了:视频生成模型竟然把它当成「记忆体」
首帧的真正秘密被揭开了:视频生成模型竟然把它当成「记忆体」在 Text-to-Video / Image-to-Video 技术突飞猛进的今天,我们已经习惯了这样一个常识: 视频生成的第一帧(First Frame)只是时间轴的起点,是后续动画的起始画面。
来自主题: AI技术研报
9144 点击 2025-12-06 11:03
 搜索
搜索
在 Text-to-Video / Image-to-Video 技术突飞猛进的今天,我们已经习惯了这样一个常识: 视频生成的第一帧(First Frame)只是时间轴的起点,是后续动画的起始画面。
近年来,以 Veo、Sora 为代表的视频生成模型展现出惊人的合成能力,能够生成高度逼真且时序连贯的动态画面。这类模型在视觉内容生成上的进步,表明其内部可能隐含了对世界结构与规律的理解。更令人关注的是,Google 的最新研究指出,诸如 Veo 3 等模型正在逐步显现出超越单纯合成的 “涌现特性”,包括感知、建模和推理等更高层次能力。
视频生成模型如Veo-3能生成逼真视频,但有研究发现其推理能力存疑。香港中文大学、北京大学、东北大学的研究者们设计了12项测试,发现模型只能模仿表面模式,未真正理解因果。这项研究为视频模型推理能力评估提供基准,指明未来研究方向。
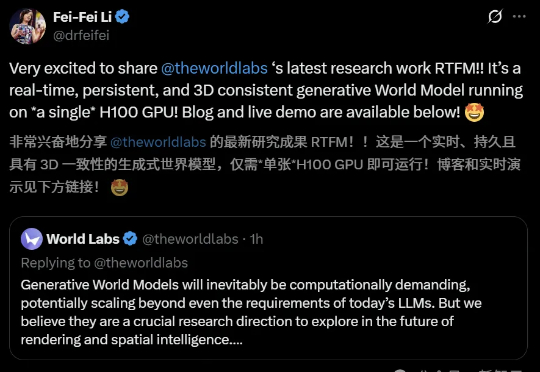
一张图,一个3D世界!今天,李飞飞团队重磅放出实时生成世界模型「RTFM」,通过端到端学习大规模视频数据,直接从输入2D图像生成同一场景下新视角的图像。值得一提的是,它仅需单块H100 GPU便能实时渲染出持久且3D一致的世界。

李飞飞的世界模型创业,最新成果来了!刚刚,教母亲自宣布对外推出全新模型RTFM(A Real-Time Frame Model),不仅具备实时运行、持久性和3D一致性,更关键的是——单张H100 GPU就能跑。

DeepMind公开了有关Veo 3视频模型最新论文!论文提出了「帧链」(Chain-of-Frames,CoF),认为视频模型也可能像通用大模型一样具备推理能力。零样本能力的涌现,表明视频模型的「GPT-3时刻」来了。
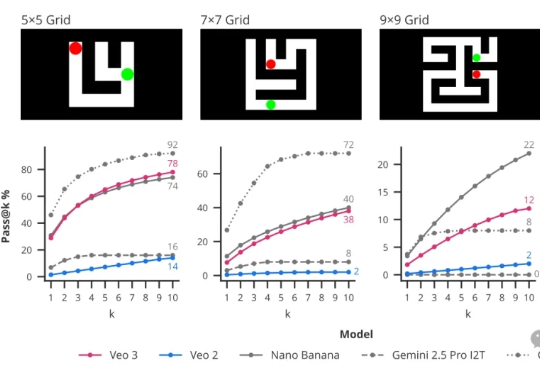
CoT思维链的下一步是什么? DeepMind提出帧链CoF(chain-of-frames)。

Framer 是一家荷兰公司,专门开发网页设计自动化工具,目前已完成一轮估值达 20 亿美元的融资。

本文介绍使用四块Framework主板构建AI推理集群的完整过程,并对其在大语言模型推理任务中的性能表现进行了系统性评估。该集群基于AMD Ryzen AI Max+ 395处理器,采用mini ITX规格设计,可部署在10英寸标准机架中。
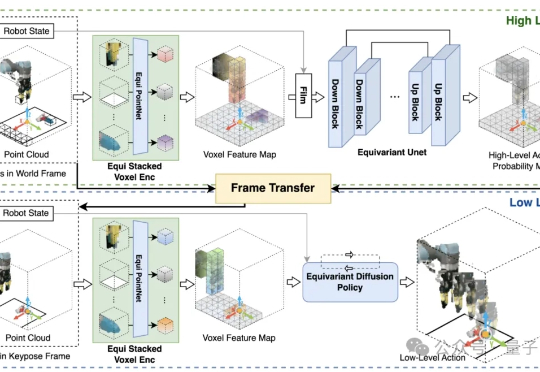
如何让AI像人一样,仅凭少量演示,就能稳健适应复杂多变的真实场景? 美国东北大学和波士顿动力RAI提出了HEP(Hierarchical Equivariant Policy via Frame Transfer)框架,首创“坐标系转移接口”,让机器人学习更高效、泛化更灵活。