
Claude把病毒起源算错90年,都是网页惹的祸?
Claude把病毒起源算错90年,都是网页惹的祸?顶级AI编码一日千里,到了生物学领域却频频翻车,并非模型不够聪明,而是科学数据库至今只为人类点鼠标而生。
来自主题: AI资讯
8405 点击 2026-06-10 14:45
 搜索
搜索
顶级AI编码一日千里,到了生物学领域却频频翻车,并非模型不够聪明,而是科学数据库至今只为人类点鼠标而生。

对AI效率赛道,葬AI的朋友郭先生有一句名言:「效率赛道一定要做情绪价值,因为你会发现解决实际问题大家都不行。」
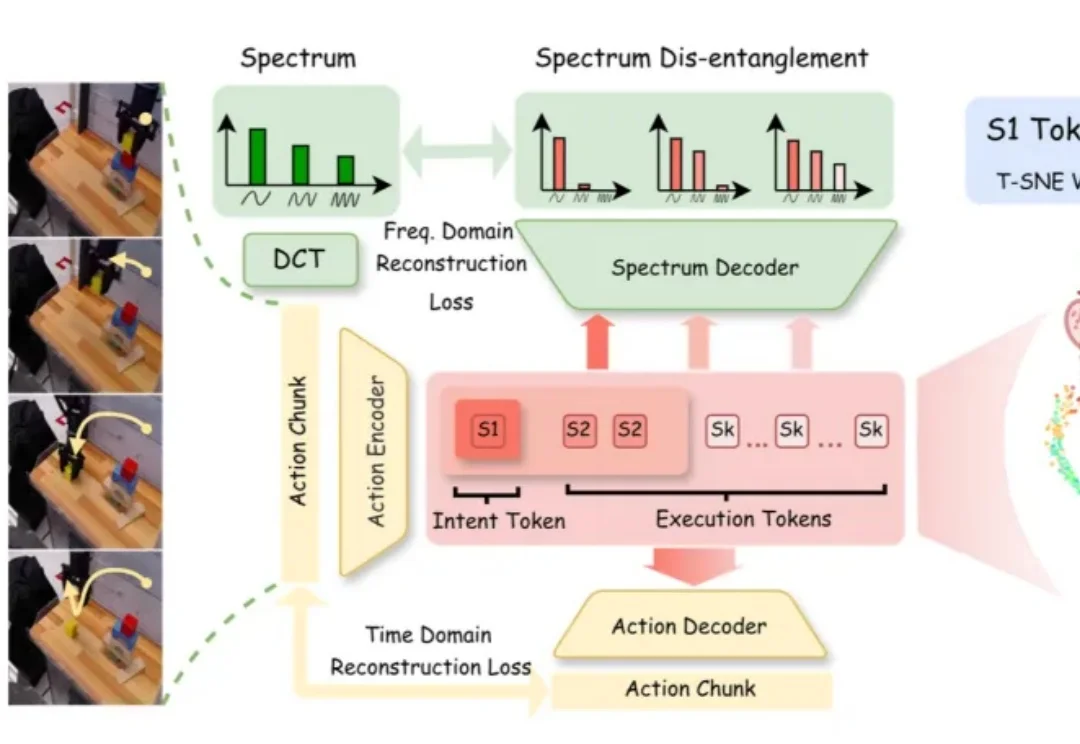
机器人视觉语言动作(Vision-Language-Action, VLA)模型越来越多地开始展示叠衣服、倒茶、做咖啡等复杂操作。但是,今天的大多数 VLA 更像 “展台机器人”。

客户数量不是核心,能为客户解决的问题数量才是核心。

过去两年,大模型写代码已经不再新鲜。从代码补全到 GitHub issue 修复,从竞赛编程到仓库级软件工程,人们习惯用一个简单标准评估 coding agent:代码能不能写对?测试能不能通过?

今日,美团GN06(原光年之外)团队正式发布AI浏览器Tabbit V1.0,并承诺核心功能将永久免费开放。Tabbit自3月2日开放公测至今,正好是100天,每周迭代,共迭代12个版本,收获了大量用户好评,比如“Windows上最好看的浏览器”、“特别务实的工具产品”、“低门槛且安全稳定地用到头部模型的方式”等等。
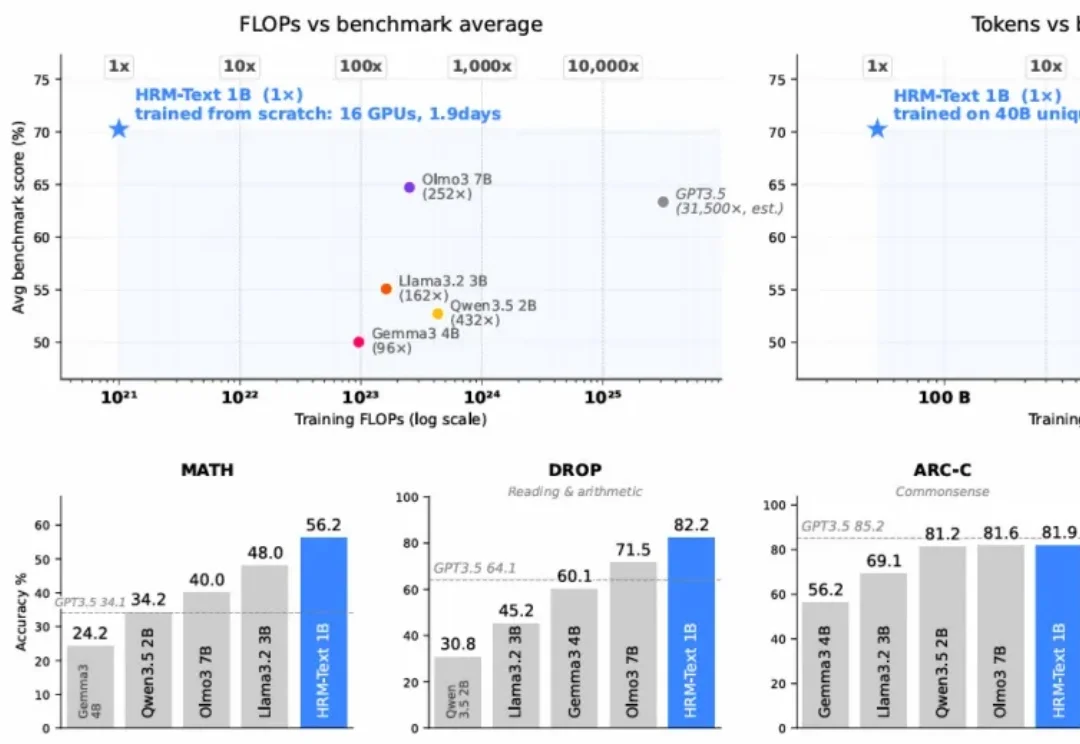
一个约 1B 参数的模型,在 MATH 上拿到 56.2,在 GSM8K 上拿到 84.5,在 ARC-Challenge 上拿到 81.9。训练成本约 1500 美元,16 块 H100 跑了不到两天。
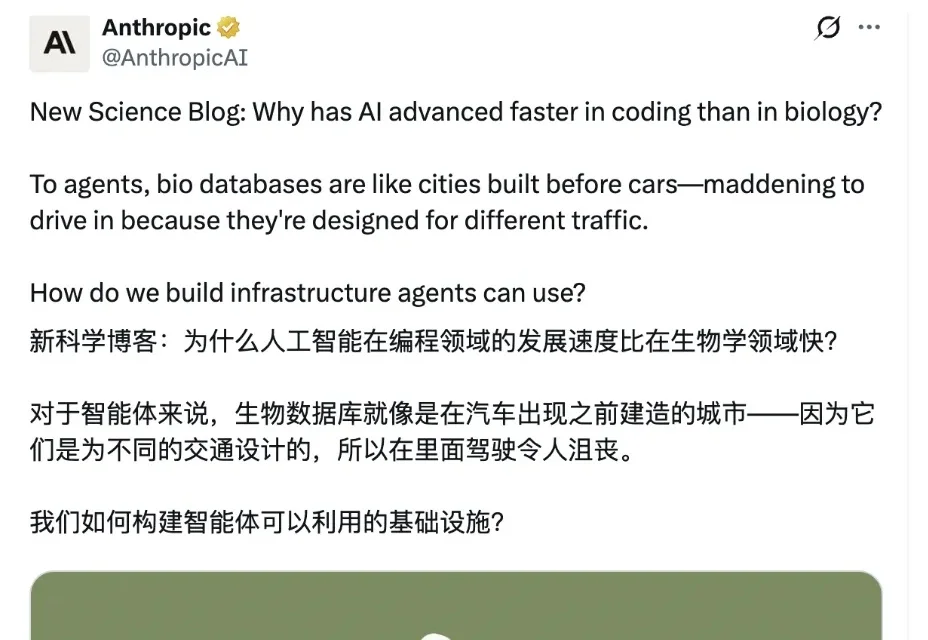
当前,Coding Agents 在软件工程领域一路高歌猛进,科学家们看到此场景,也不禁寄予厚望:AI 智能体何时能以同样的速度,帮人类攻克药物设计、病毒监控与生物学建模的重重难关?

在南加州大学,王越的 PSI Lab(Physical Superintelligence Lab)是过去两三年里具身智能方向上升最快的年轻团队之一。
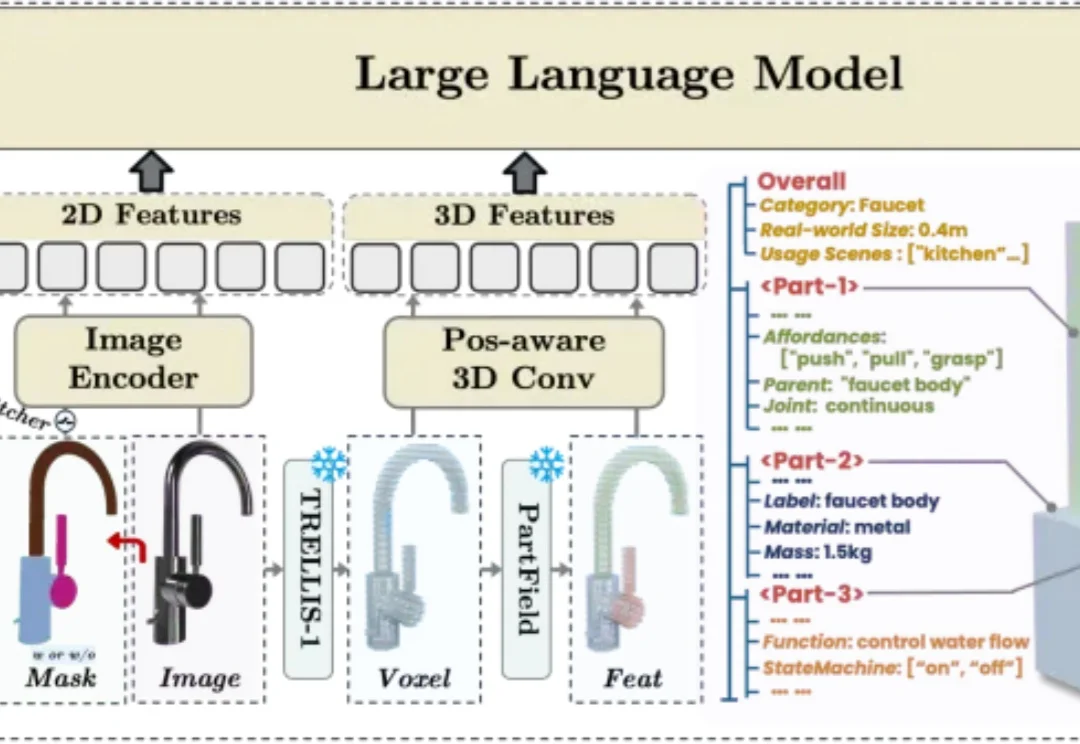
在交互式虚拟世界和具身智能快速发展的今天,高质量 3D 资产已经不再只是 “看起来像” 就足够。一个柜门不仅要有柜门的外观,还需要知道绕哪条轴旋转;一个按钮不仅要有按钮的形状,还需要具备 “按下 / 弹起” 的状态;一个抽屉不仅要有完整几何,还需要拥有滑动方向、运动范围、材质和质量等物理属性。该研究已被 ICML 2026 接收。