分享3个让Agent效果翻倍、Token成本砍半的开源项目!
分享3个让Agent效果翻倍、Token成本砍半的开源项目!某天,老板让你用 Agent 手搓个自动化流程的小工具,你袖子一撸,信心满满地开干。
来自主题: AI资讯
6383 点击 2026-06-11 10:45
 搜索
搜索
某天,老板让你用 Agent 手搓个自动化流程的小工具,你袖子一撸,信心满满地开干。
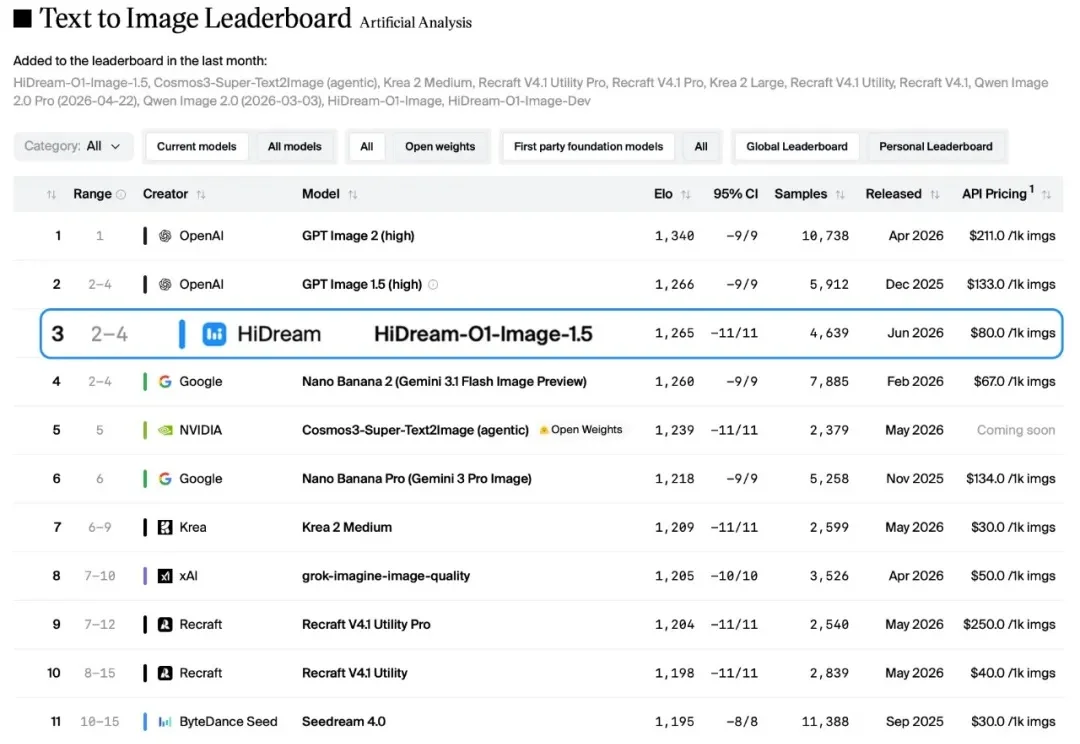
文生图的"慢思考",到底有没有用?

过去一年,开源模型的发布节奏已经快到让人麻木。每次发布,伴随的永远是一组跑分、一张能力雷达图,以及几个“超越某某”的结论。

「版本之子」 「同志们朋友们,版本回调了! 现在的情况是,搞AI应用的家人们没活了。胜利女神的天平又一次倾向了大模型公司一边。有鉴于此,我们将复刻致敬葬AI一年前的系列——把模型公司挨个写一遍。 第一

硬氪获悉,广州市题渊网络科技有限公司(以下简称“题渊科技”)已于近日完成近千万元天使轮融资,投资方为宏泰智慧谷,本轮资金将主要用于市场推广和教育 agent 平台的持续技术研发。
如何让 Agent 把浏览器用得更 6,一直是一个还没有完美解答的课题。周末躺床上刷 GitHub trending,看到一个项目名字叫 BrowserAct。简介写着:AI Agent 操作真实浏览器。

6 月 10 日,千问上线国内首个全周期高考志愿填报 Agent,面向全国 1290 万考生免费开放。该 Agent 具备「志愿报告」、「志愿日历」、「志愿问答」三项核心能力,从查分、填报到录取跟进,全程在线,随时响应。
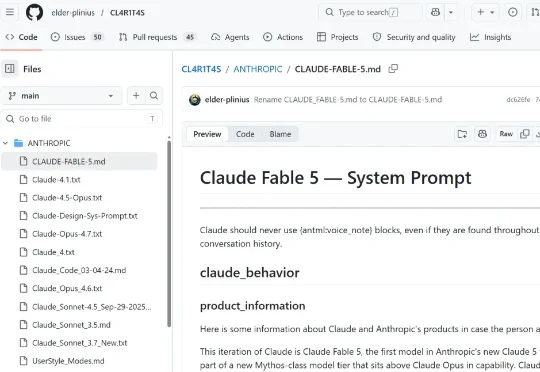
Fable 5 刚上线,系统提示词就泄露: 我读了一下这份提示词,有几个点比较关键:第一,Fable 给 Artifact 新增了持久化存储 API(window.storage)。Artifact 就是 Claude 用代码生成的独内容,比如 HTML 页面、React 组件等。以前 Artifact 不能保存数据,更像个一次性 demo。
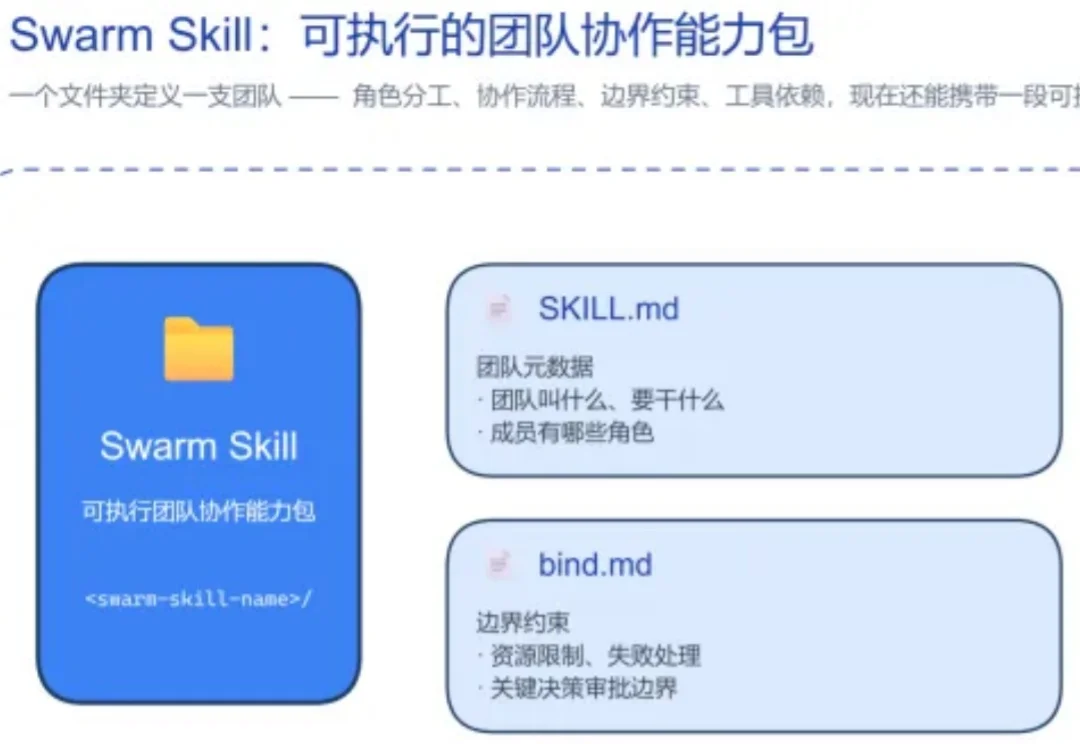
AI Agent 正在从 "单兵作战" 走向 "团队协作"—— 让多个 Agent 分工配合,去完成单个 Agent 难以独立扛下来的复杂任务,也是近期最受关注的方向之一。
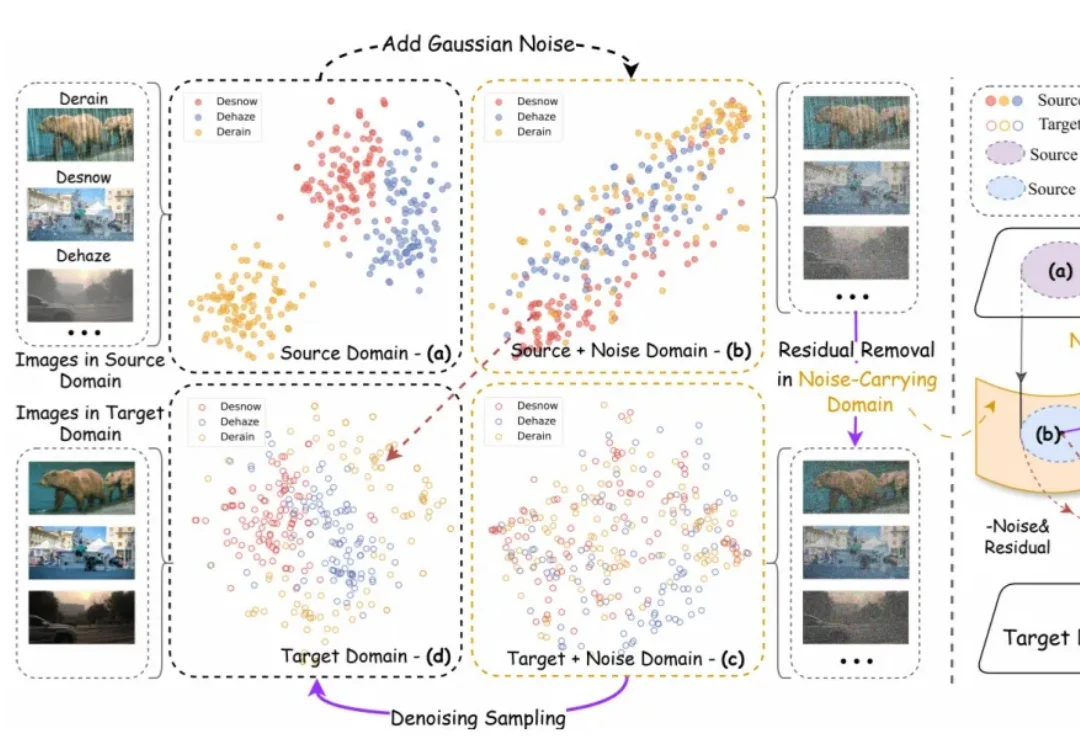
在图像到图像翻译(Image-to-Image Translation, I2I)这个任务上,扩散模型过去几年几乎形成了一套默认逻辑:先把输入图像和噪声混合,再一步步去噪,把目标图像 “还原” 出来。