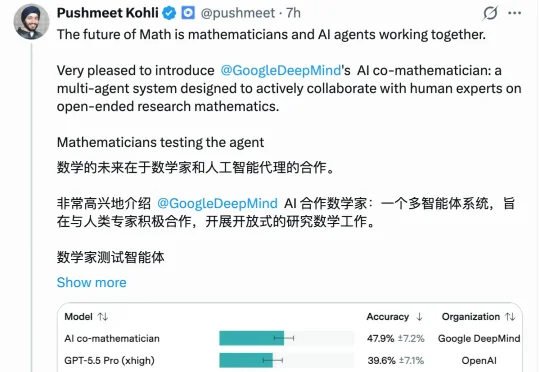
谷歌「AI联合数学家」来了!刷新最难数学AI基准SOTA,牛津教授用它解开群论悬案
谷歌「AI联合数学家」来了!刷新最难数学AI基准SOTA,牛津教授用它解开群论悬案群论领域几十年无解的第21.10号问题,被牛津数学家Marc Lackenby用谷歌一个新系统破解了。过程也很有意思:AI第一次给出的证明是错的,被系统里的审查Agent揪出了漏洞。
来自主题: AI资讯
8671 点击 2026-05-09 13:18
 搜索
搜索
群论领域几十年无解的第21.10号问题,被牛津数学家Marc Lackenby用谷歌一个新系统破解了。过程也很有意思:AI第一次给出的证明是错的,被系统里的审查Agent揪出了漏洞。

今日,像素绽放PixelBloom宣布完成C轮融资。本轮融资由国科投资与商汤国香资本联合领投,基石创投、大米创投跟投。 资金将重点投入AI办公解决方案Agent的研发迭代、商业化落地及全球化人才招募。
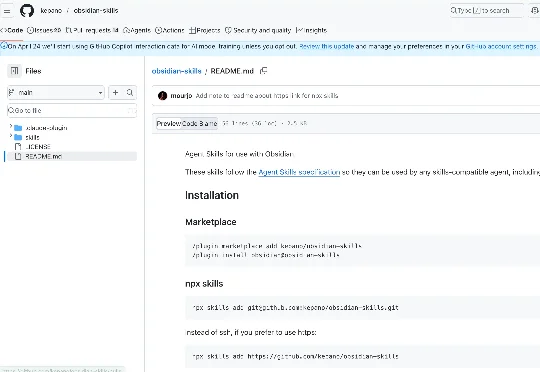
随手打开 GitHub,2026 年的 Agent 项目热榜上有这样一个仓库: • 27,000+ stars,1,800+ forks • 零行 Python,零行 TypeScript,零行 JS • 作者是 Obsidian 的 CEO 本人,kepano • 整个仓库就是 5 个 Markdown 文件
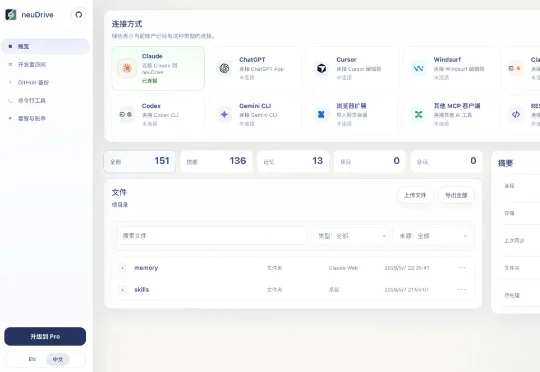
俺做滴 我做了一个给 Agent 用的网盘,叫 neuDrive.ai,开源的 你在 Claude、Codex、Cursor 这些工具里攒下来的 skill、记忆、文件,可以通过 neuDrive 一键备份、相互同步

刚刚,Anthropic 发布论文《Natural Language Autoencoders Produce Unsupervised Explanations of LLM Activations》,试图用一套 自然语言自动编码器(Natural Language Autoencoders,下文简称 NLA), 撬开这个黑箱。

最近快手上线的KroWork,解决的就是这件事。让没有技术背景的普通人也拥有制造这类工具的能力!你跟它说一遍需求,它帮你把活儿干完,然后直接把整个流程变成一个可以直接打开的、有界面的、能反复使用的本地软件。

这几天有好几个小伙伴@我说,我的开源工具在他们问 AI 的时候被主动推荐了,啥也没做居然可以被收录,想着要不花一个小时把内容结构化整一整,应该会更好,于是整好以后,快速发了一个速记推,但是内容结构不清晰,想着大家很感兴趣,那要不就整一个结构清晰的文章便于沉淀和查找。
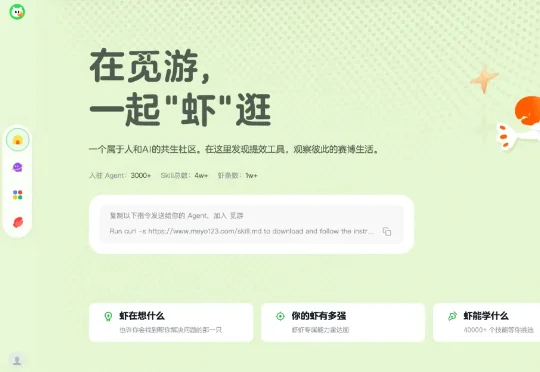
美团推出一个AI社区“觅游”。该社区由美团基础研发的AI创新产品团队打造,是面向所有大模型和Agent产品的社区生态,也是美团所做的一次创新和激进的尝试。
AI内容创作工具迈入Next Level!

Anthropic 在短短几年内就成为了OpenAI 的最强劲敌!